该论文由复旦大学、普林斯顿大学、Intel Labs 和腾讯 AI Lab 合作完成。文章提出了一种端到端的深度学习框架,可从单张彩色图片直接生成三维网格(3D Mesh)。
受深度神经网络特性的限制,以前的方法通常用 volume 或者 point cloud 表示三维形状,将它们转换为更易于使用的 mesh 并非易事。与现有方法不同,本文使用图卷积神经网络表示 3D mesh,利用从输入图像中提取的特征逐步对椭球进行变形从而产生正确的几何形状。本文使用由粗到精的模式进行生成,使得整个变形过程更加稳定。
此外,本文还定义了几种与 mesh 相关的损失函数捕捉不同级别的特性,以保证视觉上有吸引力并且物理上高重建精度。大量实验表明,本文的方法不仅定性上可以生成细节更加充分的 mesh 模型,而且与当前最好的方法相比也实现了更高的重建精度。
三维数据有多种表示形式,包括 volume、point cloud、mesh 等。volume 是一种规则的数据结构,即将物体表示为的 N3 格子,受分辨率和表达能力限制,这种表示方法通常缺乏细节。
point cloud 是一种不规则的数据结构,由于点之间没有局部连结关系,点云往往缺乏物体的表面信息;3D Mesh 同样是一种不规则的数据结构,由点、边和面组成,由于其轻量、形状细节丰富等特性,在虚拟现实、动画游戏、生产制造等实际产业中应用越来越广泛,本文研究如何从单张 RGB 图重建出对应的 3D mesh 模型。
模型架构
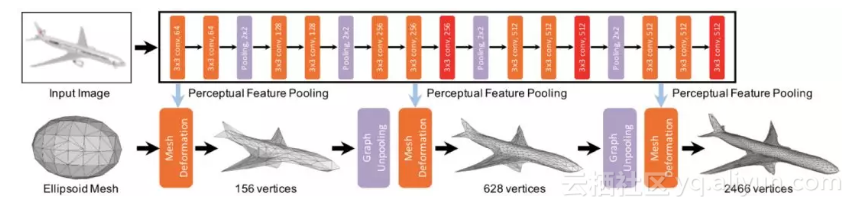
▲ Figure 1: Pixel2Mesh的架构
Pixel2Mesh 的架构如图 1 所示。对于输入图像,设计一个多层的卷积神经网络,用于提取图片不同层次的特征。对于输出三维网格,设计了 3 个级联的变形模块,由图神经网络构成。Perceptual feature pooling 层可根据网格顶点坐标得到投影的图片特征,然后根据此特征不断对初始的椭球进行变形,以逼近真实形状。Graph unpooling 层用于增加三维网格节点和边的数量。
本文的目的在于提出一种生成结果光滑、重建精度高的利用单张彩色图生成物体三维网格模型的方法。本文没有直接采用生成 3D Mesh 的方法,而是采用将一个固定的椭球依据图像特征逐渐形变成目标形状的策略。本文针对两个三维网格重建难点给出了解决方案:
1. 3D Mesh 的表示问题—引入图卷积神经网络。3D mesh 一般使用非规则数据形式—图(Graph)来表示,而同时整个网络还需要对其输入的规则的图像数据进行特征抽取。本文使用图卷积网络(GCN)来处理三维网格,使用类似于 VGG-16 的网络来提取二维图像特征。为了将两者联系在一起,设计了一个投影层使得网格中的每个节点能对应获取相应的二维图像的特征。
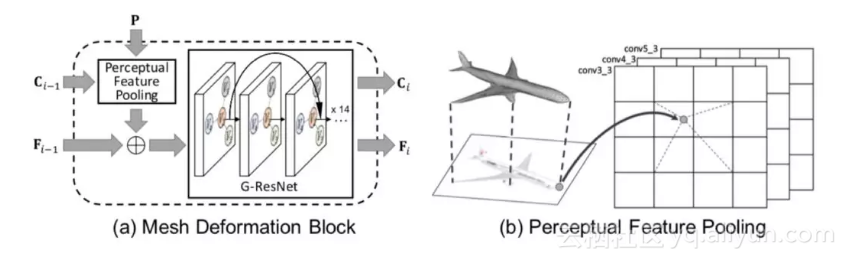
上图(a)中 P 是从输入图片得来的特征,是顶点的位置,两者组合可得到相应的投影特征,再与 GCN 的特征简单合并送入网格形变模块(Mesh Deformation Block)中。整个网络包含若干该模块。上图(b)是依据相机参数进行投影的示意图。
2. 如何有效地更新网格的形状—引入图的上池化层。实验发现,直接训练网络使其预测 mesh 的效果并不好。一个原因是如果直接预测较大数量的点的网格,顶点的感受野会有受限,即 mesh 的顶点无法有效地检索邻近顶点的特征。为了解决这个问题,本文设计了一个图的上池化层(Graph unpooling layer),使得点的数量逐渐由少到多,相应的网格形状由粗到细,既保留了全局信息,又具有细节的表达。
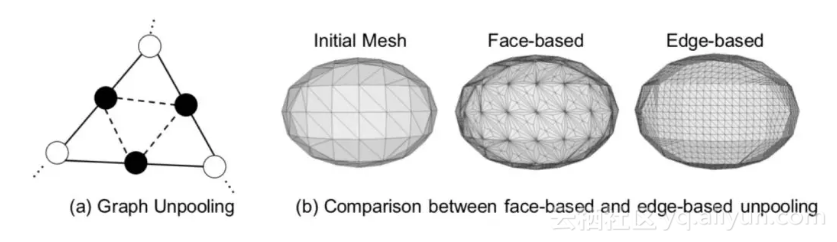
上图是图的上池化过程。(a)中的黑色顶点即为新增的顶点,连接的虚线即为新增的边。这是 Edge-based 的方式,还有一种 Face-based 的方式,即在每个三角形中心添加一个顶点,但这样会造成网格顶点不均衡的问题,如(b)所示。在实际操作中,每个新增的点位于旧三角形的边的中点位置,特征的值取相邻两顶点的均值。
损失函数
本文定义了四种不同的损失函数来促使网格更好地形变。

本方法对输入图像进行的三维网格建模的结果:

▲ Qualitative results. (a) Input image; (b) Volume from 3D-R2N2 [1], converted using Marching Cube [4]; (c) Point cloud from PSG [2], converted using ball pivoting [5]; (d) N3MR[3]; (e) Ours; (f) Ground truth.
实验结果
F-score (%)
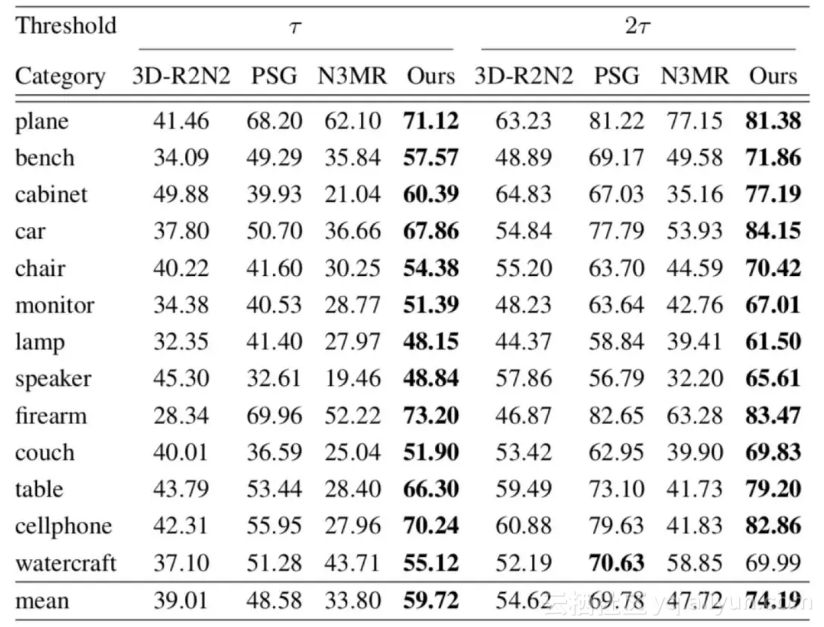
本文提出的方法在 ShapeNet 测试数据集上的表现,除了当阈值为时在 watercraft 类低于 PSG,其他指标均达到了最好水平。
CD 和 EMD
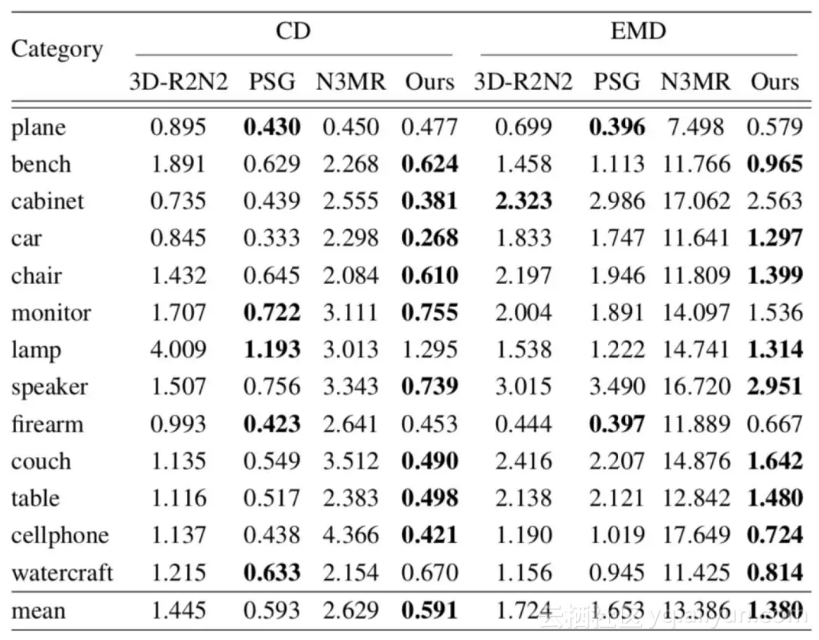
对于 CD 和 EMD,在 ShapeNet 测试集上,本文的方法在多数情况下都达到了最好水平。
原文发布时间为:2018-09-10
本文作者:让你更懂AI
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”。