挺久没更新简书了,之前一直在忙机器视觉的开题报告,现在又要期末复习,射频通信,信号处理看的脑阔疼,所以决定写个简单点的爬虫,放松下,换个环境,也顺便巩固下爬虫。

图片来自网络
0.运行环境
- Python3.6.5
- Pycharm
- win10
1.爬虫思维框架
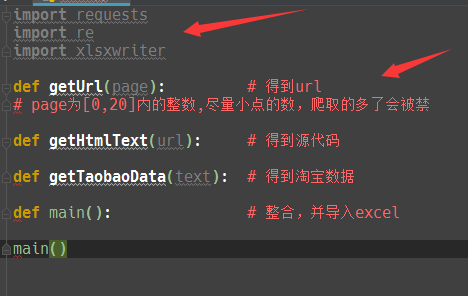
框架
1:从上图中可以看出本次爬虫所用到的库,其中xlsxwriter库是用来制作excel表格存储数据的,剩余两个库就不用多说了,爬虫必备库,你一定接触过。
官方xlsxwriter解释
CSDN博主的精简版
2:分四个步骤完成,详见上图框架。
3:爬取的淘宝页面
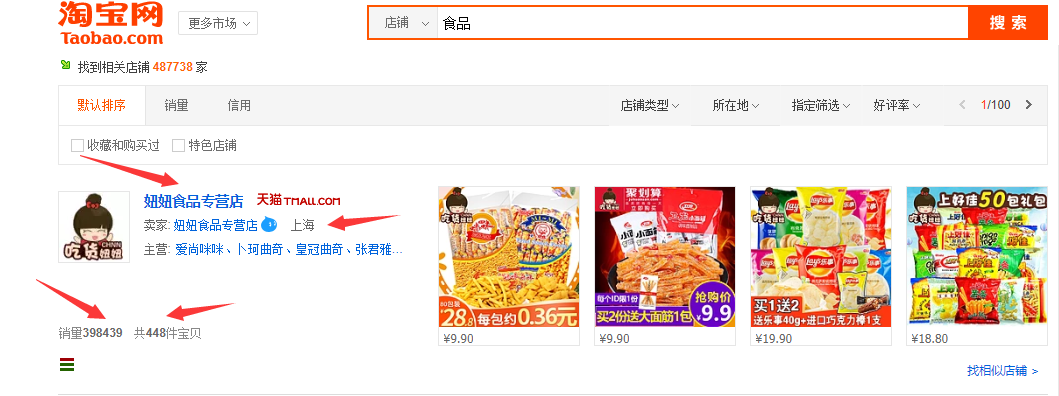
本次所要爬取的信息
2.可能遇到的问题及解决方案
- Q1,无法获取网页源代码,得到的text总是为空?
A1,必须在headers中加入cookie和user-agent,缺一不可。 - Q2,使用beautifulsoup库好还是直接正则表达式RE好?
A2,对于本次爬虫还是正则表达式好,做了就知道了。==! - Q3,如何爬取多个页面的信息?
A3,仔细观察多个页面的URL有何区别,本次的URL最后,第一页是0,第二页是20,第三页是40,找规律便可取得所有页面的URL。 - Q4,我还有其他疑问怎么办?
A4,在评论区提出,博主会第一时间回复你的哦!
3.完整代码
import requests
import re
import xlsxwriter
def getUrl(page): # page为[0,10]内的整数
part1 = 'https://shopsearch.taobao.com/search?app=shopsearch&spm=a230r.7195193.0.0.45xMl6&q=%E9%A3%9F%E5%93%81&tracelog=shopsearchnoqcat&s='
list = []
for a in range(0, page):
part2 = '{}'.format(20*a)
url = part1 + part2
list.append(url)
return list
def getHtmlText(url):
try:
headers = {
隐藏,因为每个人都不一样,可通过F12获取,具体方法自行百度
Cookie 和 User-Agent必须要
}
res = requests.get(url, headers=headers, timeout=30)
res.raise_for_status()
res.encoding = res.apparent_encoding
# time.sleep(1)
return res.text
except:
return '网络异常'
def getTaobaoData(text):
NAME = re.findall('"nick":"(.*?)"', text)
PLACE = re.findall('"provcity":"(.*?)"', text)
Totalsold = re.findall('"totalsold":(.*?),', text)
Procnt = re.findall('"procnt":(.*?),', text)
return NAME, PLACE, Totalsold, Procnt
def main(page):
num = 0
List = getUrl(page)
TaobaoData = xlsxwriter.Workbook('E:\\taobaodata.xlsx')
StoresData = TaobaoData.add_worksheet()
title = [u'店铺', u'地址', u'销量', u'产品数']
StoresData.write_row('A1', title)
StoresData.set_column('A:D', 25)
for URL in List:
Text = getHtmlText(URL)
name, place, totalsold, procnt = getTaobaoData(Text)
StoresData.write_column(1+20*num, 0, name)
StoresData.write_column(1+20*num, 1, place)
StoresData.write_column(1+20*num, 2, totalsold)
StoresData.write_column(1+20*num, 3, procnt)
num += 1
if not name:
print('第{}页爬取失败'.format(num))
else:
print('第{}页爬取成功'.format(num))
TaobaoData.close()
if __name__ == '__main__':
a = input('请输入需要爬取的页数(建议小于10):')
main(int(a))
4.实现效果
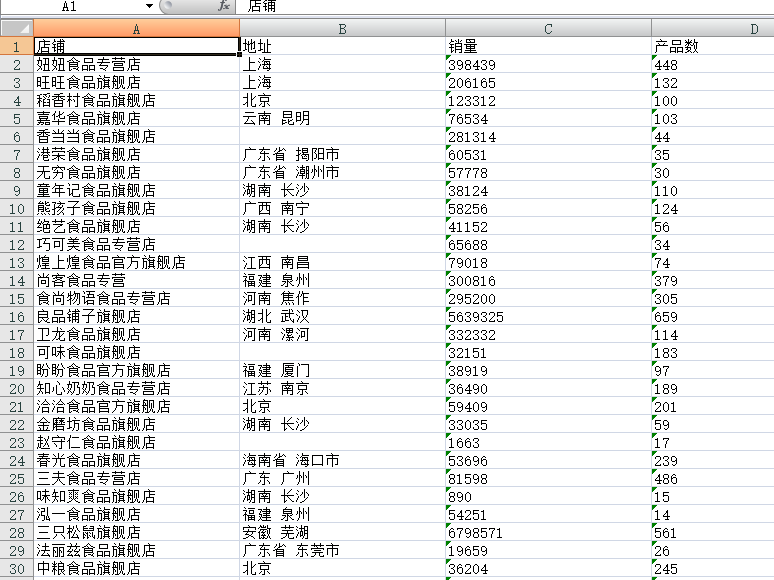
Excel
