一 前言
前几天,某科研工作者咨询我,是否可以利用PostGIS实现线数据的汇总分析,目前他使用的Arcpy处理实在太慢,难以满足应用需求。他的需求如下图:
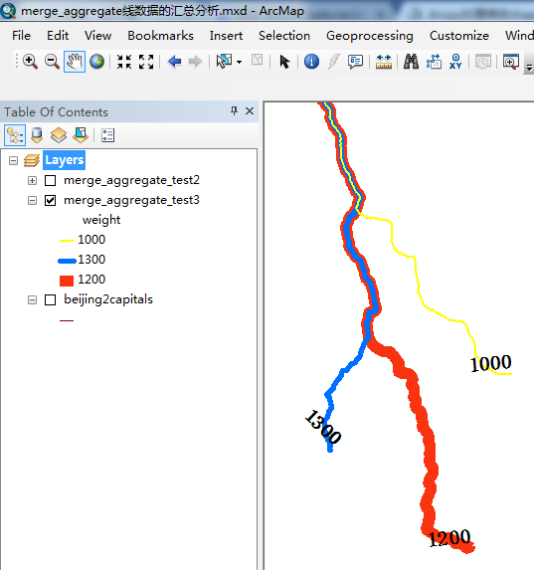
输入数据:3条线路,权重值分别为1300,1200,1000。
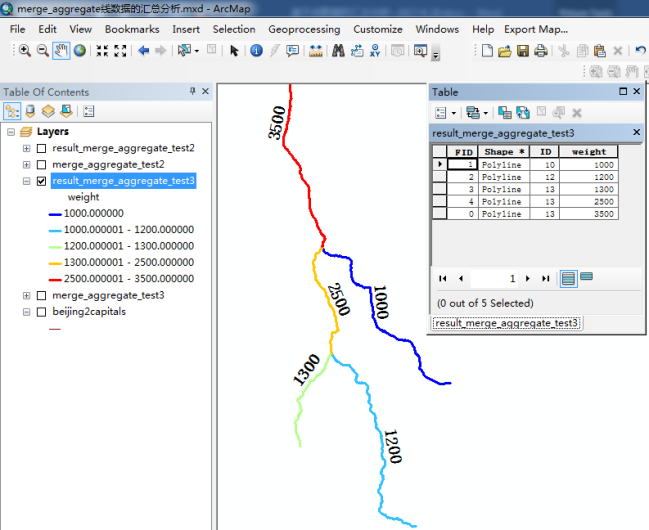
输出数据:消除重叠部分线路,重叠部分聚合为单一线路段且权重值累加,结果输入数据被切分成了绝不重叠的5段。
本着好奇心的态度,利用周末时间对此问题进行了研究。
二 解决方案一(逐条截取法)
首先映入脑海的思路是,一条条的线路单独处理,如先求取1300路段和1200路段的不重叠部分a,和重叠部分b。
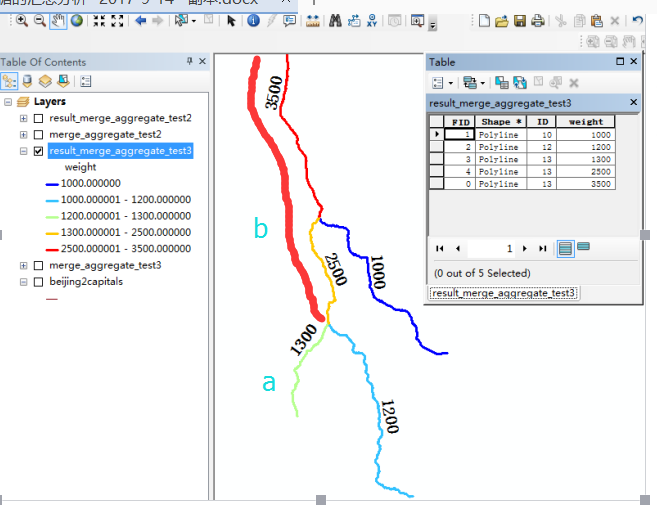
再用a,b这种被切分后的结果,与1000路段处理,a部分与1000路段无重叠,直接作为结果,b部分与1000路段重叠,被切割出不同部分b1和重叠部分c。
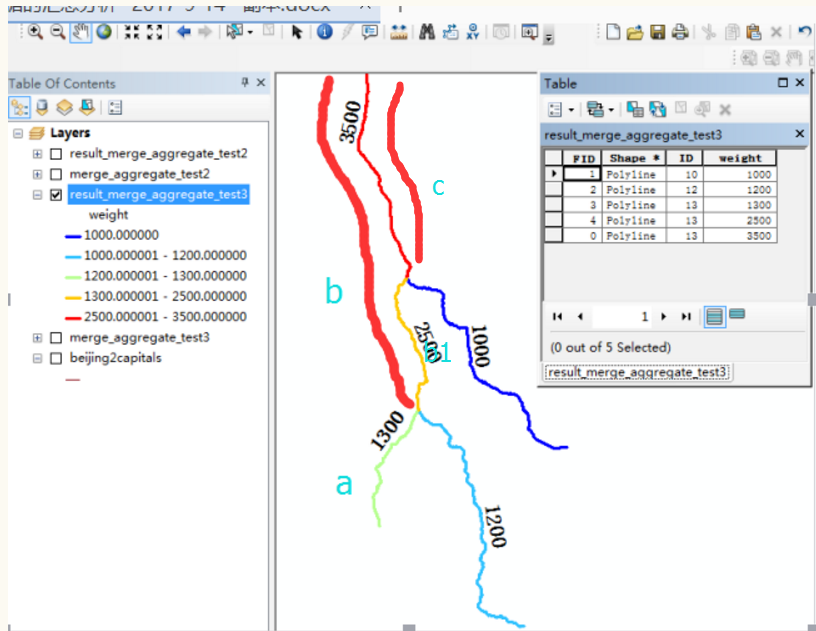
最终的结果,1300路段被切分的结果是a,b1,c。
同理处理1200,1000路段,最后对所有切割的图形进行geom的聚合运算,得到结果,重要算法如下:
#求取两个图形的不重叠部分
select ST_Difference(geom1,geom2);
#求取两个图形重叠部分
select ST_Intersection(geom1,geom2);
#根据图形聚合,权重累加,去除重叠图形
select sum(weight) weight,geom from result group by geom;
整体代码逻辑如下:
do language plpgsql $$
DECLARE
rec record;
rec1 record;
rec2 record;
rec3 record;
rec4 record;
publicgeom geometry;
privategeom geometry;
geom_array geometry[];
geom_array_split geometry[];
temp_geom geometry;
_temp_geom geometry;
geomcount int;
BEGIN
for rec in select * from test_road loop --遍历路段表
geom_array:=array[rec.geom];--切割成果集合初始化
--从表中找出与处理的路段存在压盖关系且非自身的数据
for rec1 in select gid,geom from test_road where ST_Overlaps(geom,rec.geom) and gid!=rec.gid loop
geom_array_split:='{}';
--对每次的切割成果迭代分析,求取公共部分,单独部分
FOREACH temp_geom IN ARRAY geom_array loop
publicgeom:=ST_LineMerge(ST_Intersection(temp_geom,rec1.geom));--提取公共部分
privategeom:=ST_Difference(temp_geom,rec1.geom);--提取单独部分
if(ST_IsEmpty(publicgeom)=false) then
for rec4 in select * from geomsplit(publicgeom) loop
geom_array_split:=array_append(geom_array_split,rec4.geom);
end loop;
end if;
if(ST_IsEmpty(privategeom)=false) then
for rec4 in select * from geomsplit(privategeom) loop
geom_array_split:=array_append(geom_array_split,rec4.geom);
end loop;
end if;
end loop;
geom_array:=geom_array_split;--每次处理完重叠和不重叠部分,结果形成新的待切割结果
end loop;
--一条记录处理完毕,切割完毕的结果存入表
FOREACH temp_geom IN ARRAY geom_array loop
execute format('INSERT INTO result_test_road(
id, weight, geom) VALUES ($1,$2,$3)') using rec.gid,rec.weight,temp_geom;
end loop;
end loop;
end;
$$;
--对切割成果进行聚合分析
select sum(weight),geom from result_test_road group by geom;
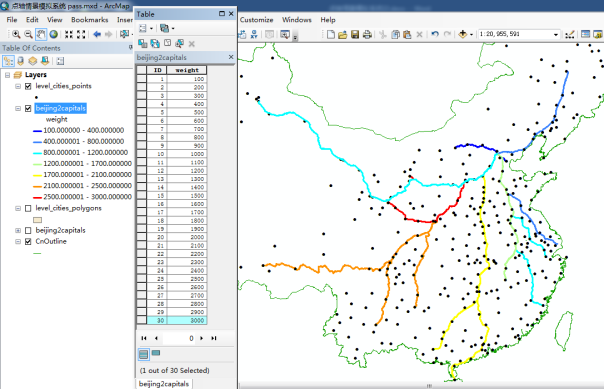
该算法在处理北京与各省会城市的路径时比较有效,样本数据30几条,很快处理完了。但是,处理北京与各县的路径时,数据量大概2500条,每切割完一条线路,消耗10分钟。(处理完大概333小时,oh my god)
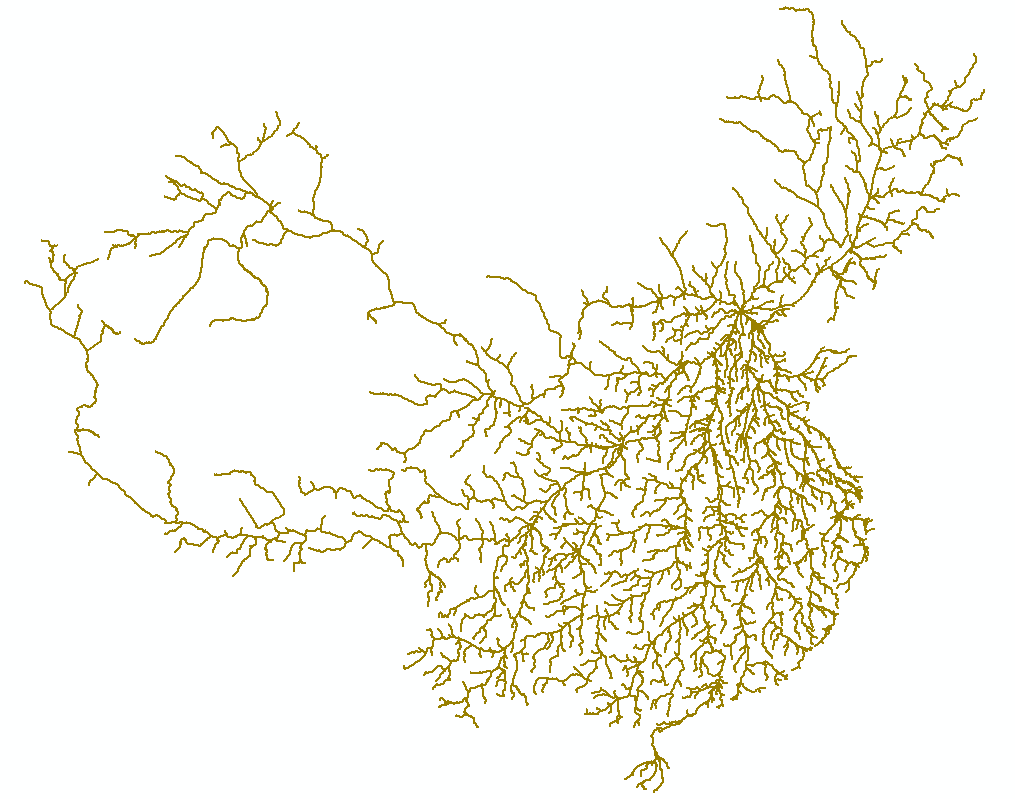
总结:该算法思路比较简单,就是对每条线路逐个的切割,每次切割完的结果再和相交的线路切割,直到相交线路处理完毕。该算法保证了结果的正确性,逻辑的简单性,但是明显循环实在太多,计算代切割集合会像滚雪球一样几何级别的增长,尤其在数据表记录较多的情况下,简直惨不忍睹。
三 解决方案二(原子聚合法)
该方法是将每条线上的点拆解下来,重叠线路部分的点位也是重合的,然后根据点位进行权重聚合,相同位置的话,权重累加,如下图:
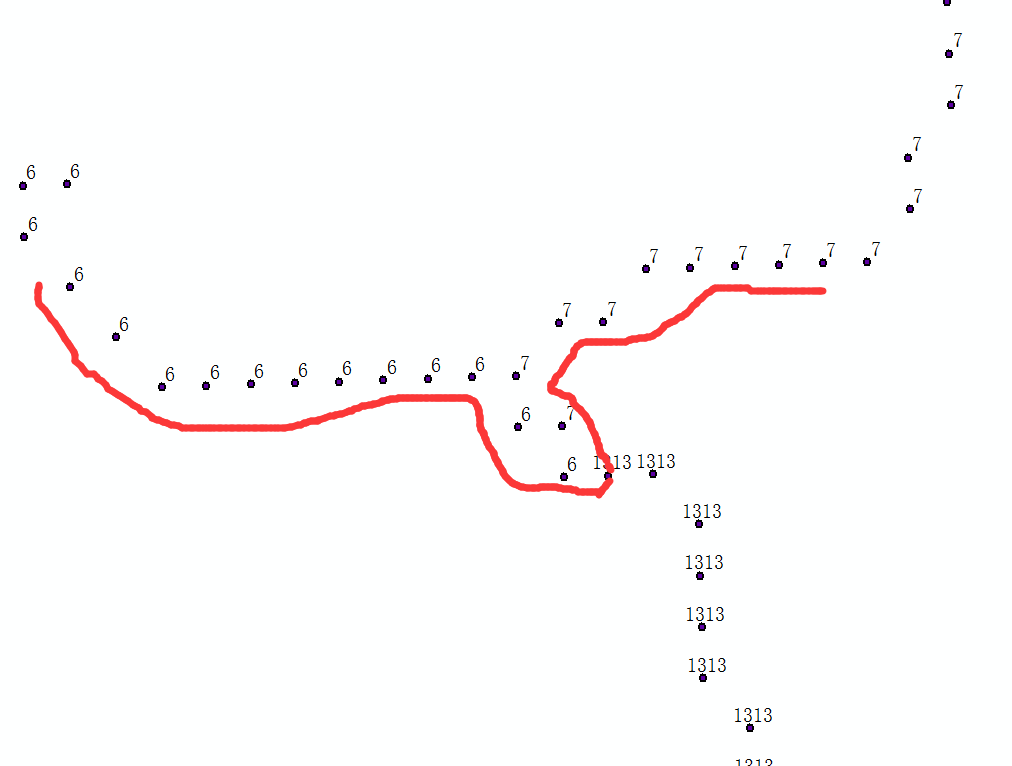

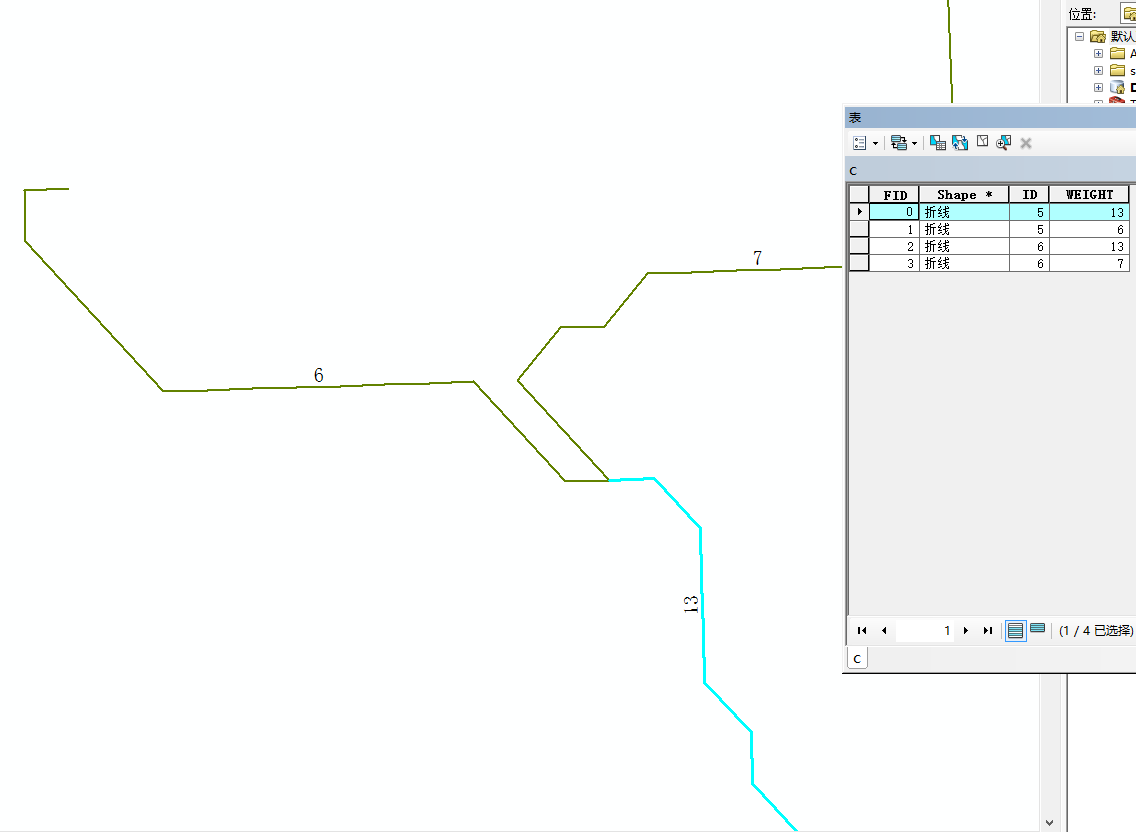
id为5的线路被拆分成了权重是6,13的两部分,同理,另外一个线路也根据权重实现了拆分。

代码如下:
--线拆分成点,该表存储所有节点
CREATE TABLE road_pt(
gid serial primary key,
id integer,
weight numeric,
ptindex int,
geom geometry(Point,3857)
);
--将每个线路拆分点存入road_pt表
do language plpgsql $$
DECLARE
rec record;
ptcount int;
BEGIN
for rec in select * from test_road loop
raise notice '正在处理gid:%',rec.gid;
ptcount:=ST_NPoints(rec.geom);
insert into road_pt(id,weight,ptindex,geom) values(rec.id,rec.weight,generate_series(1,ptcount),ST_PointN(rec.geom,generate_series(1,ptcount)));
end loop;
end;
$$;
--消耗50s
--创建空间索引
CREATE INDEX road_pt_geom_idx
ON road_pt
USING gist
(geom);
--Query returned successfully with no result in 01:14 minutes.
--相同的图形点,权重累加,权重聚合后的点数据存入表road_pt_group
select sum(weight) weight,geom into road_pt_group from road_pt group by geom;
--Query returned successfully: 76035 rows affected, 17.1 secs execution time.
--创建空间索引
CREATE INDEX road_pt_group_geom_idx
ON road_pt_group
USING gist
(geom);
--3s
--将点表中,与聚合图形相同的点位,统一更新新的点位权重
update road_pt t2 set weight=t1.weight from road_pt_group t1 where ST_Equals(t2.geom,t1.geom);
--Query returned successfully: 2237228 rows affected, 02:26 minutes execution time.
--重新点拼接成线
--点合成线,存储进入road_split
CREATE TABLE road_split(
gid serial primary key,
id integer,
weight numeric,
geom geometry(LineString,3857)
);
--线的拆分点,合并成路段
do language plpgsql $$
DECLARE
rec record;
i int;
ptcount int;
geomarr geometry[];
beforerec record;
isstart boolean:=true;
BEGIN
for rec in select * from road_pt order by id,ptindex loop
if(isstart=true) then
beforerec:=rec;
isstart:=false;
geomarr:=array[rec.geom];
continue;
end if;
if(rec.id!=beforerec.id) then
insert into road_split(id,weight,geom) values (beforerec.id,beforerec.weight,st_makeline(geomarr));
geomarr:=array[rec.geom];
else
if(rec.weight>beforerec.weight) then
geomarr:=array_append(geomarr,rec.geom);
insert into road_split(id,weight,geom) values (rec.id,beforerec.weight,st_makeline(geomarr));
geomarr:=array[rec.geom];--开启新篇章
elsif(rec.weight<beforerec.weight) then
insert into road_split(id,weight,geom) values (rec.id,beforerec.weight,st_makeline(geomarr));
geomarr:=array[beforerec.geom,rec.geom];
else
geomarr:=array_append(geomarr,rec.geom);
end if;
end if;
beforerec:=rec;
end loop;
insert into road_split(id,weight,geom) values (beforerec.id,beforerec.weight,st_makeline(geomarr));
end;
$$;
--30 s
--创建表,用于合并路段
CREATE TABLE road_merge(
gid serial primary key,
weight numeric,
geom geometry(LineString,3857)
);
--根据权重,图形聚合,去掉重复的,结果就是需要的
insert into road_merge(weight,geom) select weight,geom from road_split group by weight,geom; --1.4s
该算法的灵感认为:点的图形计算比线极大简化+空间索引的查询效率。请注意程序中每次的中间步骤表都有gist索引的创建!用于聚合,相等等判断快速完成。
最终,将每条线处理耗时10分钟(处理完333小时),优化到全部处理完成5min,且仍有可优化空间。
四 思考
- shp数据不应做项目应用,正如这位科研工作者的arcpy处理shp很慢的结果,参考《shp与PostGIS在项目应用中比较》。
- 批量空间数据处理,尤其大批量计算和分析,肯定应在空间数据引擎中实现而非后台,充分利用索引。
- 复杂分析,可能的话,可将图形抽象成点去分析,极大提升分析速度。
- 事情完成不代表做好,在某个数据量下可行不代表在任何情况下可行,思路要开阔,技术要多比较。
- 坚信GIS未来是空间数据的时代,PostGIS+大数据数据平台大有可为。
