概述
全局索引是Phoenix的重要特性,合理的使用二级索引能降低查询延时,让集群资源得以充分利用。 本文将讲述如何高效的设计和使用索引。
全局索引说明
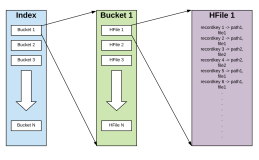
全局索引的根本是通过单独的HBase表来存储数据表的索引数据。我们通过如下示例看索引数据和主表数据的关系。
-- 创建数据表
CREATE TABLE DATA_TABLE(
A VARCHAR PRIMARY KEY,
B VARCHAR,
C INTEGER,
D INTEGER);
-- 创建索引
CREATE INDEX B_IDX ON DATA_TABLE(B)INCLUDE(C);
-- 插入数据
UPSERT INTO DATA_TABLE VALUES('A','B',1,2);当写入数据到主表时,索引数据也会被同步到索引表中。索引表中的主键将会是索引列和数据表主键的组合值,include的列被存储在索引表的普通列中,目的是让查询更加高效,只需要查询一次索引表就能够拿到数据,而不用去回查主表。其过程如下图:
Phoenix表就是HBase表,而HBase Rowkey都是通过二进制数据的字典序排列存储,也就意味着Row key前缀匹配度越高就越容易排在一起。
全局索引设计
我们继续使用DATA_TABLE作为示例表,创建如下组合索引。之前我们已经提到索引表中的Row key是字典序存储的,什么样的查询适合这样的索引结构呢?
CREATE INDEX B_C_D_IDX ON DATA_TABLE(B,C,D);
所有字段条件以=操作符为例:

注:上表查询中and条件不一定要和索引组合字段顺序一致,可以任意组合。
在实际使用中我们也只推荐使用1~4,遵循前缀匹配原则,避免触发扫全表。5~7条件就要扫描全表数据才能过滤出来符合这些条件的数据,所以是极力不推荐的。
其它
- 对于order by字段或者group by字段仍然能够使用二级索引字段来加速查询。
- 尽量通过合理的设计数据表的主键规避建更多的索引表,因为索引表越多写放大越严重。
- 使用了ROW_TIMESTAMP特性后不能使用全局索引
- 对索引表适当的使用加盐特性能提升查询写入性能,避免热点。