在Spark中很多地方都涉及网络通信,比如Spark各个组件间的消息互通、用户文件与Jar包的上传、节点间的Shuffle过程、Block数据的复制与备份等。在Spark 0.x.x与Spark 1.x.x版本中,组件间的消息通信主要借助于Akka[1],使用Akka可以轻松的构建强有力的高并发与分布式应用。但是Akka在Spark 2.0.0版本中被移除了,Spark官网文档对此的描述为:“Akka的依赖被移除了,因此用户可以使用任何版本的Akka来编程了。”Spark团队的决策者或许认为对于Akka具体版本的依赖,限制了用户对于Akka不同版本的使用。尽管如此,笔者依然认为Akka是一款非常优秀的开源分布式系统,我参与的一些Java Application或者Java Web就利用Akka的丰富特性实现了分布式一致性、最终一致性以及分布式事务等分布式环境面对的问题。在Spark 1.x.x版本中,用户文件与Jar包的上传采用了由Jetty[2]实现的HttpFileServer,但在Spark 2.0.0版本中也被废弃了,现在使用的是基于Spark内置RPC框架的NettyStreamManager。节点间的Shuffle过程和Block数据的复制与备份这两个部分在Spark2.0.0版本中依然沿用了Netty[3],通过对接口和程序进行重新设计将各个组件间的消息互通、用户文件与Jar包的上传等内容统一纳入到Spark的RPC框架体系中。
我们先来看看RPC框架的基本架构,如图1所示。
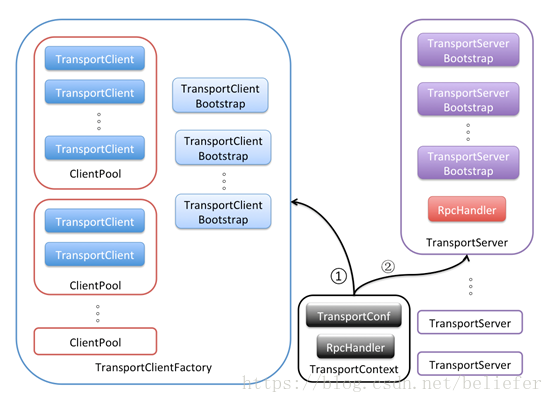
图1 Spark内置RPC框架的基本架构
TransportContext内部包含传输上下文的配置信息TransportConf和对客户端请求消息进行处理的RpcHandler。TransportConf在创建TransportClientFactory和TransportServer时都是必须的,而RpcHandler只用于创建TransportServer。TransportClientFactory是RPC客户端的工厂类。TransportServer是RPC服务端的实现。图中记号的含义如下:
记号①表示通过调用TransportContext的createClientFactory方法创建传输客户端工厂TransportClientFactory的实例。在构造TransportClientFactory的实例时,还会传递客户端引导程序TransportClientBootstrap的列表。此外,TransportClientFactory内部还存在针对每个Socket地址的连接池ClientPool,这个连接池缓存的定义如下:
private final ConcurrentHashMap<SocketAddress, ClientPool> connectionPool;ClientPool的类型定义如下:
private static class ClientPool {
TransportClient[] clients;
Object[] locks;
ClientPool(int size) {
clients = new TransportClient[size];
locks = new Object[size];
for (int i = 0; i < size; i++) {
locks[i] = new Object();
}
}
}由此可见,ClientPool实际是由TransportClient的数组构成,而locks数组中的Object与clients数组中的TransportClient按照数组索引一一对应,通过对每个TransportClient分别采用不同的锁,降低并发情况下线程间对锁的争用,进而减少阻塞,提高并发度。
记号②表示通过调用TransportContext的createServer方法创建传输服务端TransportServer的实例。在构造TransportServer的实例时,需要传递TransportContext、host、port、RpcHandler以及服务端引导程序TransportServerBootstrap的列表。
有了对Spark内置RPC框架的基本架构的了解,现在正式介绍Spark的RPC框架所包含的各个组件:
- TransportContext:传输上下文,包含了用于创建传输服务端(TransportServer)和传输客户端工厂(TransportClientFactory)的上下文信息,并支持使用TransportChannelHandler设置Netty提供的SocketChannel的Pipeline的实现。
- TransportConf:传输上下文的配置信息。
- RpcHandler:对调用传输客户端(TransportClient)的sendRPC方法发送的消息进行处理的程序。
- MessageEncoder:在将消息放入管道前,先对消息内容进行编码,防止管道另一端读取时丢包和解析错误。
- MessageDecoder:对从管道中读取的ByteBuf进行解析,防止丢包和解析错误;
- TransportFrameDecoder:对从管道中读取的ByteBuf按照数据帧进行解析;
- RpcResponseCallback:RpcHandler对请求的消息处理完毕后,进行回调的接口。
- TransportClientFactory:创建传输客户端(TransportClient)的传输客户端工厂类。
- ClientPool:在两个对等节点间维护的关于传输客户端(TransportClient)的池子。ClientPool是TransportClientFactory的内部组件。
- TransportClient:RPC框架的客户端,用于获取预先协商好的流中的连续块。TransportClient旨在允许有效传输大量数据,这些数据将被拆分成几百KB到几MB的块。当TransportClient处理从流中获取的获取的块时,实际的设置是在传输层之外完成的。sendRPC方法能够在客户端和服务端的同一水平线的通信进行这些设置。
- TransportClientBootstrap:当服务端响应客户端连接时在客户端执行一次的引导程序。
- TransportRequestHandler:用于处理客户端的请求并在写完块数据后返回的处理程序。
- TransportResponseHandler:用于处理服务端的响应,并且对发出请求的客户端进行响应的处理程序。
- TransportChannelHandler:代理由TransportRequestHandler处理的请求和由TransportResponseHandler处理的响应,并加入传输层的处理。
- TransportServerBootstrap:当客户端连接到服务端时在服务端执行一次的引导程序。
- TransportServer:RPC框架的服务端,提供高效的、低级别的流服务。
拓展知识:为什么需要MessageEncoder和MessageDecoder?因为在基于流的传输里(比如TCP/IP),接收到的数据首先会被存储到一个socket接收缓冲里。不幸的是,基于流的传输并不是一个数据包队列,而是一个字节队列。即使你发送了2个独立的数据包,操作系统也不会作为2个消息处理而仅仅认为是一连串的字节。因此不能保证远程写入的数据会被准确地读取。举个例子,让我们假设操作系统的TCP/TP协议栈已经接收了3个数据包:ABC、DEF、GHI。由于基于流传输的协议的这种统一的性质,在你的应用程序在读取数据的时候有很高的可能性被分成下面的片段:AB、CDEFG、H、I。因此,接收方不管是客户端还是服务端,都应该把接收到的数据整理成一个或者多个更有意义并且让程序的逻辑更好理解的数据。
本文只是从整体上对Spark内置的RPC框架进行介绍,今后将分别介绍RPC框架的各个组成部分,他们是:
- RPC配置TransportConf
- RPC客户端工厂TransportClientFactory
- RPC服务器TransportServer
- 管道初始化
- RPC传输管道处理器TransportChannelHandler详解
- 服务端RpcHandler详解
- 服务端引导程序TransportServerBootstrap
- 客户端TransportClient详解
[1] Akka是基于Actor并发编程模型实现的并发的分布式的框架。Akka是用Scala语言编写的,它提供了Java和Scala两种语言的API,减少开发人员对并发的细节处理,并保证分布式调用的最终一致性。在附录B中有关于Akka的进一步介绍,感兴趣的读者不妨一读。
[2] Jetty 是一个开源的Servlet容器,它为基于Java的Web容器,例如JSP和Servlet提供运行环境。Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行的Java应用提供网络和Web连接。在附录C中有对Jetty的简单介绍,感兴趣的读者可以选择阅读。
[3] Netty是由Jboss提供的一个基于NIO的客户、服务器端编程框架,使用Netty 可以确保你快速、简单的开发出一个网络应用,例如实现了某种协议的客户,服务端应用。附录G中有对Netty的简单介绍,感兴趣的读者可以一读。
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,基于Spark2.1.0版本的《Spark内核设计的艺术 架构设计与实现》一书现已出版发行,图书如图:

纸质版售卖链接如下:

