1. 导入实例
1.1 登陆数据库查看表
xiaosi@Qunar:~$ mysql -u root -pEnter password:Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 8Server version: 5.6.30-0ubuntu0.15.10.1-log (Ubuntu)Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> use test;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> show tables;+-----------------+| Tables_in_test |+-----------------+| employee || hotel_info |+-----------------+
1.2 导入操作
我们选择employee这张表进行导入。
mysql> select * from employee;+--------+---------+-----------------+| name | company | depart |+--------+---------+-----------------+| yoona | qunar | 创新事业部 || xiaosi | qunar | 创新事业部 || jim | ali | 淘宝 || kom | ali | 淘宝 |
sqoop import --connect jdbc:mysql://localhost:3306/test --table employee --username root -password root -m 1
上面代码是把test数据库下employee表中数据导入HDFS中,运行结果如下:
16/11/13 16:37:35 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/13 16:37:35 INFO mapreduce.Job: Running job: job_local976138588_000116/11/13 16:37:35 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/13 16:37:35 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/13 16:37:35 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter16/11/13 16:37:35 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/13 16:37:35 INFO mapred.LocalJobRunner: Starting task: attempt_local976138588_0001_m_000000_016/11/13 16:37:35 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/13 16:37:35 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/13 16:37:35 INFO db.DBInputFormat: Using read commited transaction isolation16/11/13 16:37:35 INFO mapred.MapTask: Processing split: 1=1 AND 1=116/11/13 16:37:35 INFO db.DBRecordReader: Working on split: 1=1 AND 1=116/11/13 16:37:35 INFO db.DBRecordReader: Executing query: SELECT `name`, `company`, `depart` FROM `employee` AS `employee` WHERE ( 1=1 ) AND ( 1=1 )16/11/13 16:37:35 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/13 16:37:35 INFO mapred.LocalJobRunner:16/11/13 16:37:35 INFO mapred.Task: Task:attempt_local976138588_0001_m_000000_0 is done. And is in the process of committing16/11/13 16:37:35 INFO mapred.LocalJobRunner:16/11/13 16:37:35 INFO mapred.Task: Task attempt_local976138588_0001_m_000000_0 is allowed to commit now16/11/13 16:37:35 INFO output.FileOutputCommitter: Saved output of task 'attempt_local976138588_0001_m_000000_0' to hdfs://localhost:9000/user/xiaosi/employee/_temporary/0/task_local976138588_0001_m_00000016/11/13 16:37:35 INFO mapred.LocalJobRunner: map16/11/13 16:37:35 INFO mapred.Task: Task 'attempt_local976138588_0001_m_000000_0' done.16/11/13 16:37:35 INFO mapred.LocalJobRunner: Finishing task: attempt_local976138588_0001_m_000000_016/11/13 16:37:35 INFO mapred.LocalJobRunner: map task executor complete.16/11/13 16:37:36 INFO mapreduce.Job: Job job_local976138588_0001 running in uber mode : false16/11/13 16:37:36 INFO mapreduce.Job: map 100% reduce 0%16/11/13 16:37:36 INFO mapreduce.Job: Job job_local976138588_0001 completed successfully16/11/13 16:37:36 INFO mapreduce.Job: Counters: 20File System CountersFILE: Number of bytes read=22247770FILE: Number of bytes written=22733107FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=0HDFS: Number of bytes written=120HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=3Map-Reduce FrameworkMap input records=6Map output records=6Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=0Total committed heap usage (bytes)=241696768File Input Format CountersBytes Read=0File Output Format CountersBytes Written=12016/11/13 16:37:36 INFO mapreduce.ImportJobBase: Transferred 120 bytes in 2.4312 seconds (49.3584 bytes/sec)16/11/13 16:37:36 INFO mapreduce.ImportJobBase: Retrieved 6 records.
是不是很眼熟,这就是MapReduce作业的输出日志,说明Sqoop导入数据是通过MapReduce作业完成的,并且是没有Reduce任务的MapReduce。为了验证是否导入成功,查看HDFS的目录,执行如下命令:
xiaosi@Qunar:/opt/hadoop-2.7.2/sbin$ hadoop fs -ls /user/xiaosiFound 2 itemsdrwxr-xr-x - xiaosi supergroup 0 2016-10-26 16:16 /user/xiaosi/datadrwxr-xr-x - xiaosi supergroup 0 2016-11-13 16:37 /user/xiaosi/employee
xiaosi@Qunar:/opt/hadoop-2.7.2/sbin$ hadoop fs -ls /user/xiaosi/employeeFound 2 items-rw-r--r-- 1 xiaosi supergroup 0 2016-11-13 16:37 /user/xiaosi/employee/_SUCCESS-rw-r--r-- 1 xiaosi supergroup 120 2016-11-13 16:37 /user/xiaosi/employee/part-m-00000
其中,_SUCCESS是代表作业成功的标志文件,输出结果是part-m-00000文件(有可能会输出_logs文件,记录了作业日志)。查看输出文件内容:
yoona,qunar,创新事业部xiaosi,qunar,创新事业部jim,ali,淘宝kom,ali,淘宝lucy,baidu,搜索jim,ali,淘宝
xiaosi@Qunar:/opt/sqoop-1.4.6/bin$ ll总用量 116drwxr-xr-x 2 root root 4096 11月 13 16:36 ./drwxr-xr-x 9 root root 4096 4月 27 2015 ../-rwxr-xr-x 1 root root 6770 4月 27 2015 configure-sqoop*-rwxr-xr-x 1 root root 6533 4月 27 2015 configure-sqoop.cmd*-rw-r--r-- 1 root root 12543 11月 13 16:32 employee.java-rwxr-xr-x 1 root root 800 4月 27 2015 .gitignore*-rwxr-xr-x 1 root root 3133 4月 27 2015 sqoop*-rwxr-xr-x 1 root root 1055 4月 27 2015 sqoop.cmd*-rwxr-xr-x 1 root root 950 4月 27 2015 sqoop-codegen*-rwxr-xr-x 1 root root 960 4月 27 2015 sqoop-create-hive-table*-rwxr-xr-x 1 root root 947 4月 27 2015 sqoop-eval*-rwxr-xr-x 1 root root 949 4月 27 2015 sqoop-export*-rwxr-xr-x 1 root root 947 4月 27 2015 sqoop-help*-rwxr-xr-x 1 root root 949 4月 27 2015 sqoop-import*-rwxr-xr-x 1 root root 960 4月 27 2015 sqoop-import-all-tables*-rwxr-xr-x 1 root root 959 4月 27 2015 sqoop-import-mainframe*-rwxr-xr-x 1 root root 946 4月 27 2015 sqoop-job*-rwxr-xr-x 1 root root 957 4月 27 2015 sqoop-list-databases*-rwxr-xr-x 1 root root 954 4月 27 2015 sqoop-list-tables*-rwxr-xr-x 1 root root 948 4月 27 2015 sqoop-merge*-rwxr-xr-x 1 root root 952 4月 27 2015 sqoop-metastore*-rwxr-xr-x 1 root root 950 4月 27 2015 sqoop-version*-rwxr-xr-x 1 root root 3987 4月 27 2015 start-metastore.sh*-rwxr-xr-x 1 root root 1564 4月 27 2015 stop-metastore.sh*
public class employee extends SqoopRecord implements DBWritable, Writable {private final int PROTOCOL_VERSION = 3;public int getClassFormatVersion() { return PROTOCOL_VERSION; }protected ResultSet __cur_result_set;private String name;public String get_name() {return name;}public void set_name(String name) {this.name = name;}public employee with_name(String name) {this.name = name;return this;}private String company;public String get_company() {return company;}public void set_company(String company) {this.company = company;}public employee with_company(String company) {this.company = company;return this;}private String depart;public String get_depart() {return depart;}public void set_depart(String depart) {this.depart = depart;}public employee with_depart(String depart) {this.depart = depart;return this;}public boolean equals(Object o) {if (this == o) {return true;}if (!(o instanceof employee)) {return false;}employee that = (employee) o;boolean equal = true;equal = equal && (this.name == null ? that.name == null : this.name.equals(that.name));equal = equal && (this.company == null ? that.company == null : this.company.equals(that.company));equal = equal && (this.depart == null ? that.depart == null : this.depart.equals(that.depart));return equal;}
2. 导入过程
从前面的样例大致了解到Sqoop是通过MapReducer作业进行导入工作,在做作业中,会从表中读取一行行的记录,然后将其写入HDFS中。
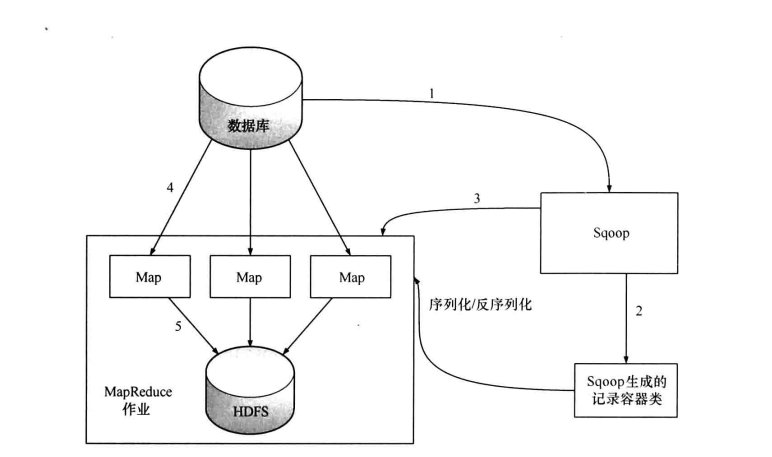
(1)第一步,Sqoop会通过JDBC来获取所需要的数据库元数据,例如,导入表的列名,数据类型等。
(2)第二步,这些数据库的数据类型(varchar, number等)会被映射成Java的数据类型(String, int等),根据这些信息,Sqoop会生成一个与表名同名的类用来完成反序列化工作,保存表中的每一行记录。
(3)第三步,Sqoop启动MapReducer作业
(4)第四步,启动的作业在input的过程中,会通过JDBC读取数据表中的内容,这时,会使用Sqoop生成的类进行反序列化操作
(5)第五步,最后将这些记录写到HDFS中,在写入到HDFS的过程中,同样会使用Sqoop生成的类进行序列化
如上图所示,Sqoop的导入作业通常不只是由一个Map任务完成,也就是说每个任务会获取表的一部分数据,如果只由一个Map任务完成导入的话,那么在第四步时,作业会通过JDBC执行如下SQL:
select col1, col2,... From table;
这样就能获取表的全部数据,如果由多个Map任务来完成,那就必须对表进行水平切分,水平切分的依据通常会是表的主键。Sqoop在启动MapReducer作业时,会首先通过JDBC查询切分列的最大值和最小值,在根据启动任务数(使用-m命令指定)划分出每个任务所负责的数据,实质上在第四步时,每个任务执行的SQL为:
select col1, col2,... From table WHERE id > 0 AND id < 50000;select col1, col2,... From table WHERE id > 5000 AND id < 100000;...
使用sqoop进行并行导入的话,切分列的数据分布会很大程度上会影响性能,如果在均匀分布的情况下,性能最好。在最坏的情况下,数据严重倾斜,所有数据都集中在某一个切分区中,那么此时的性能与串行导入性能没有差别,所以在导入之前,有必要对切分列的数据进行抽样检测,了解数据的分布。
Sqoop可以对导入过程进行精细的控制,不用每次都导入一个表的所有字段。Sqoop允许我们指定表的列,在查询中加入WHERE子句,甚至可以自定义查询SQL语句,并且在SQL语句中,可以任意使用目标数据库所支持的函数。
在开始的例子中,我们导入的数据存放到了HDFS中,将这份数据导入Hive之前,必须在Hive中创建该表,Sqoop提供了相应的命令:
sqoop create-hive-table --connect jdbc:mysql://localhost:3306/test --table employee --username root -password root --fields-terminated-by ','
3. 导出实例
与Sqoop导入功能相比,Sqoop的导出功能使用频率相对较低,一般都是将Hive的分析结果导出到关系数据库中以供数据分析师查看,生成报表等。
在将Hive中表导出到数据库时,必须在数据库中新建一张来接受数据的表,需要导出的Hive表为order_info,如下:
hive (test)> desc order_info;OKuid stringorder_time stringbusiness stringTime taken: 0.096 seconds, Fetched: 3 row(s)
mysql> create table order_info(id varchar(50), order_time varchar(20), business varchar(10));Query OK, 0 rows affected (0.09 sec)
备注:
在Hive中,字符串数据类型为String类型,但在关系性数据库中,有可能是varchar(10),varchar(20),这些必须根据情况自己指定,这也是必须由用户事先将表创建好的原因。
接下来,执行导入操作,执行命令如下:
sqoop export --connect jdbc:mysql://localhost:3306/test --table order_info --export-dir /user/hive/warehouse/test.db/order_info --username root -password root -m 1 --fields-terminated-by '\t'
16/11/13 19:21:43 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/13 19:21:43 INFO mapreduce.Job: Running job: job_local1384135708_000116/11/13 19:21:43 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/13 19:21:43 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.sqoop.mapreduce.NullOutputCommitter16/11/13 19:21:43 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/13 19:21:43 INFO mapred.LocalJobRunner: Starting task: attempt_local1384135708_0001_m_000000_016/11/13 19:21:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/13 19:21:43 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/test.db/order_info/order.txt:0+378516/11/13 19:21:43 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file16/11/13 19:21:43 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start16/11/13 19:21:43 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length16/11/13 19:21:43 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/13 19:21:43 INFO mapred.LocalJobRunner:16/11/13 19:21:43 INFO mapred.Task: Task:attempt_local1384135708_0001_m_000000_0 is done. And is in the process of committing16/11/13 19:21:43 INFO mapred.LocalJobRunner: map16/11/13 19:21:43 INFO mapred.Task: Task 'attempt_local1384135708_0001_m_000000_0' done.16/11/13 19:21:43 INFO mapred.LocalJobRunner: Finishing task: attempt_local1384135708_0001_m_000000_016/11/13 19:21:43 INFO mapred.LocalJobRunner: map task executor complete.16/11/13 19:21:44 INFO mapreduce.Job: Job job_local1384135708_0001 running in uber mode : false16/11/13 19:21:44 INFO mapreduce.Job: map 100% reduce 0%16/11/13 19:21:44 INFO mapreduce.Job: Job job_local1384135708_0001 completed successfully16/11/13 19:21:44 INFO mapreduce.Job: Counters: 20File System CountersFILE: Number of bytes read=22247850FILE: Number of bytes written=22734115FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=3791HDFS: Number of bytes written=0HDFS: Number of read operations=12HDFS: Number of large read operations=0HDFS: Number of write operations=0Map-Reduce FrameworkMap input records=110Map output records=110Input split bytes=151Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=0Total committed heap usage (bytes)=226492416File Input Format CountersBytes Read=0File Output Format CountersBytes Written=016/11/13 19:21:44 INFO mapreduce.ExportJobBase: Transferred 3.7021 KB in 2.3262 seconds (1.5915 KB/sec)16/11/13 19:21:44 INFO mapreduce.ExportJobBase: Exported 110 records.
导出完毕之后,我们可以在mysql中通过order_info表进行查询:
mysql> select * from order_info limit 5;+-----------------+------------+----------+| id | order_time | business |+-----------------+------------+----------+| 358574046793404 | 2016-04-05 | flight || 358574046794733 | 2016-08-03 | hotel || 358574050631177 | 2016-05-08 | vacation || 358574050634213 | 2015-04-28 | train || 358574050634692 | 2016-04-05 | tuan |+-----------------+------------+----------+5 rows in set (0.00 sec)
4. 导出过程
其实在了解了导入过程后,导出过程就变的更容易理解了,如下图所示:
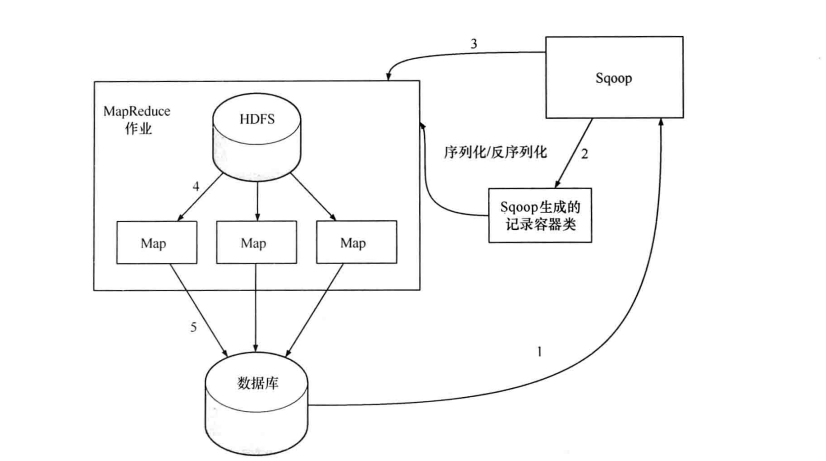
同样,Sqoop根据目标表(数据库)的结构会生成一个Java类(第一步和第二步),该类的作用为序列化和反序列化。接着会启动一个MapReduce作业(第三步),在作业中会用生成的Java类从HDFS中读取数据(第四步),并生成一批INSERT语句,每条语句对会向mysql的目标表插入多条数据(第五步),这样读入的时候是并行的,写入的时候也是并行的,但是其写入性能会受限于目标数据库的写入性能。
来自于:《Hadoop海量数据处理 技术详解与项目实战》