1. HiveServer1
HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果。HiveServer是建立在Apache ThriftTM(http://thrift.apache.org/) 之上的,因此有时会被称为Thrift Server,这可能会导致混乱,因为新服务HiveServer2也是建立在Thrift之上的.自从引入HiveServer2后,HiveServer也被称为HiveServer1。
警告
HiveServer无法处理来自多个客户端的并发请求.这实际上是HiveServer导出的Thrift接口所施加的限制,也不能通过修改HiveServer源代码来解决。
HiveServer2对HiveServer进行了重写,来解决这些问题,从Hive 0.11.0版本开始。建议使用HiveServer2。
从Hive1.0.0版本(以前称为0.14.1版本)开始,HiveServer开始被删除。请切换到HiveServer2。
2. HiveServer2
2.1 引入
HiveServer2(HS2)是一种能使客户端执行Hive查询的服务。 HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃。HiveServer2可以支持多客户端并发和身份认证。旨在为开放API客户端(如JDBC和ODBC)提供更好的支持。
HiveServer2单进程运行,提供组合服务,包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI的Jetty Web服务器。
2.2 架构
基于Thrift的Hive服务是HiveServer2的核心,负责维护Hive查询(例如,从Beeline)。Thrift是构建跨平台服务的RPC框架。其堆栈由4层组成:server,Transport,Protocol和处理器。可以在 https://thrift.apache.org/docs/concepts 找到有关分层的更多详细信息。
2.2.1 Server
HiveServer2在TCP模式下使用TThreadPoolServer(来自Thrift),在HTTP模式下使用Jetty Server。
TThreadPoolServer为每个TCP连接分配一个工作线程。即使连接处于空闲状态,每个线程也始终与连接相关联。因此,由于大量并发连接产生大量线程,从而导致潜在的性能问题。在将来,HiveServer2可能切换到TCP模式下的另一个不同类型的Server上,例如TThreadedSelectorServer。
2.2.2 Transport
如果客户端和服务器之间需要代理(例如,为了负载均衡或出于安全原因),则需要HTTP模式。这就是为什么它与TCP模式被同样支持的原因。可以通过Hive配置属性hive.server2.transport.mode指定Thrift服务的传输模式。
2.2.3 Protocol
协议责序列化和反序列化。HiveServer2目前正在使用TBinaryProtocol作为Thrift的协议进行序列化。 在未来,可以更多考虑其他协议,如TCompactProtocol,可以考虑更多的性能评估。
2.2.4 处理器
处理流程是处理请求的应用程序逻辑。例如,ThriftCLIService.ExecuteStatement()方法实现了编译和执行Hive查询的逻辑。
2.3 依赖
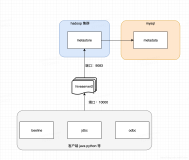
- Metastore metastore可以配置为嵌入式(与HiveServer2相同的过程)或远程服务器(也是基于Thrift的服务)。 HS2与查询编译所需的元数据相关。
- Hadoop cluster HiveServer2准备了各种执行引擎(MapReduce/Tez/Spark)的物理执行计划,并将作业提交到Hadoop集群执行。
3. JDBC Client
推荐使用JDBC驱动程序让客户端与HiveServer2进行交互。请注意,有一些用例(例如,Hadoop Hue),直接使用Thrift客户端,而没有使用JDBC。 以下是进行第一次查询所涉及的一系列API调用:
- JDBC客户端(例如,Beeline)通过初始化传输连接(例如,TCP连接),再调用OpenSession API来获取SessionHandle来创建HiveConnection。 会话是从服务器端创建的。
- 执行HiveStatement(遵循JDBC标准),并且Thrift客户端调用ExecuteStatement API。 在API调用中,SessionHandle信息与查询信息一起传递给服务器。
- HiveServer2服务器接收请求,并让驱动程序(CommandProcessor)进行查询解析和编译。该驱动程序启动后台工作,将与Hadoop交互,然后立即向客户端返回响应。这是ExecuteStatement API的异步设计。响应包含从服务器端创建的OperationHandle。
- 客户端使用OperationHandle与HiveServer2交互以轮询查询执行的状态。