第一篇内容:《车联网上云最佳实践(一)》
二、传统IDC架构介绍及技术详解
俗话说知己知彼百战不殆,我们要上云首先要充分了解自己业务和应用架构。然后在充分了解云上产品的特性,看看哪些产品可以直接被我们使用,哪些是需要我们的应用或架构做出调整的。下面我们来分析下智能车联网平台的相关架构。
下图为公司业务架构图。分为三大业务平台,其中核心是车联网平台,其次是能力资源平台和第三方合作平台。
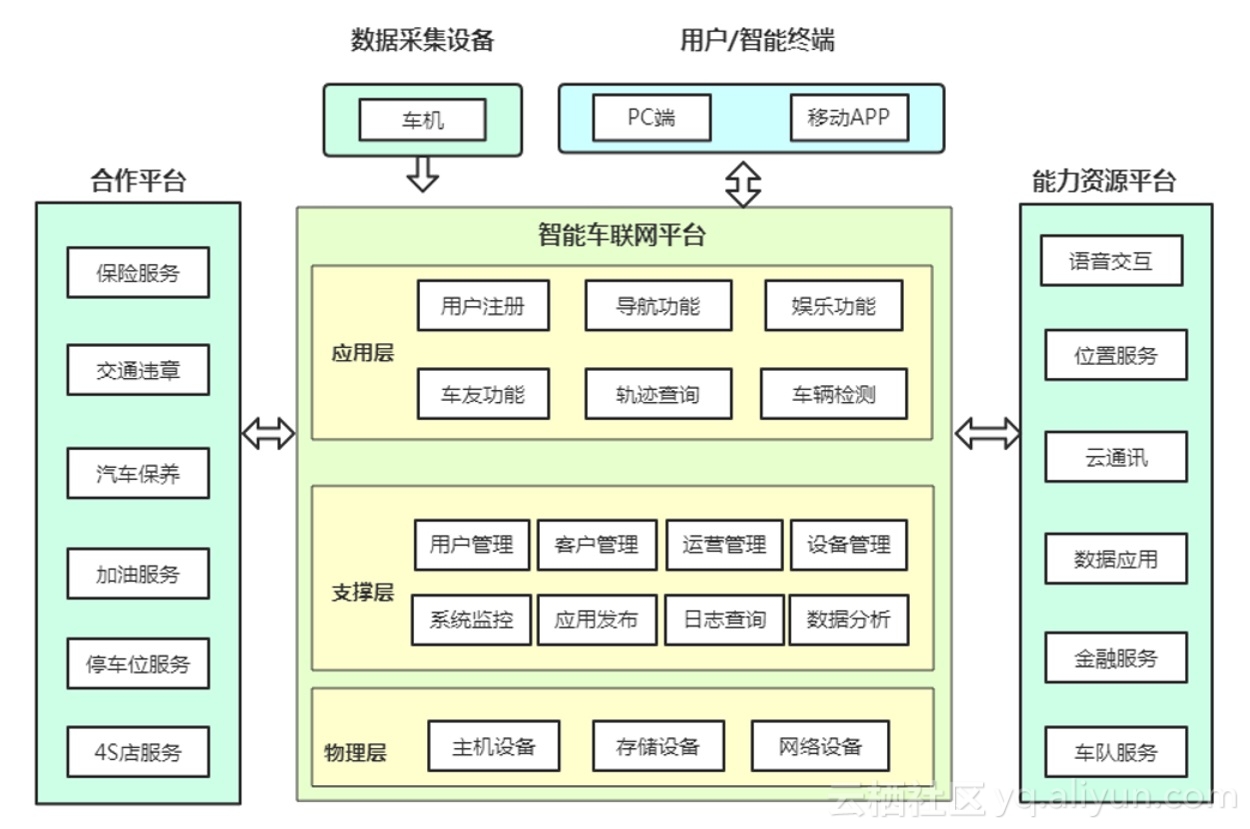
车联网核心平台:主要包含应用层、支持层、物理层等功能,其中应用层包含功能有用户注册,用户登录,导航功能,车友功能,车辆检测功能,轨迹查询功能以及其他娱乐功能。这些是APP的核心功能。其次是支持层的功能,例如运营管理系统,用户管理系统,车辆管理系统等辅助运营和运维的系统和工具。
能力资源平台:是指的公司具备向外界提供的资源和能力,可以利用开放平台将我们的能力提供给外部需要客户和合作伙伴。例如车队服务,数据应用,位置服务等等。
第三方合作平台:是指通过调用第三方平台接口来完成为用户提供部分功能,例如保险服务,违章查询功能,停车位查找功能,4S店服务等功能。
2、应用架构
下图为应用架构,主要分为客户端接入层,负载均衡集群,应用服务器集群,缓存集群,消息队列集群,分布式服务集群,数据存储集群,运维管控集群等。
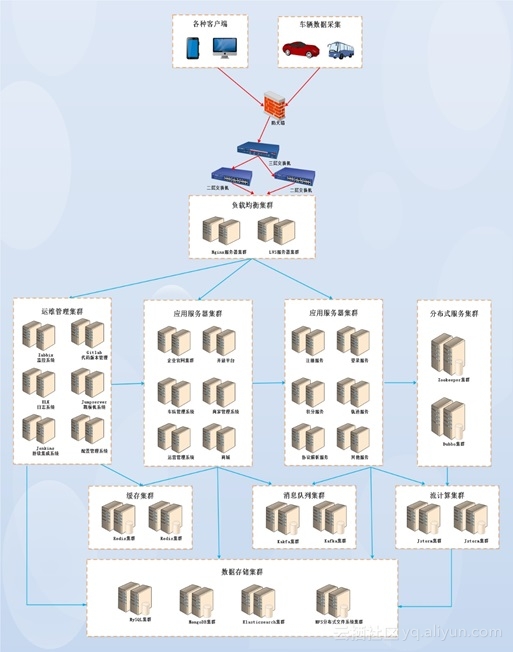
1.1 数据流介绍
数据采集:
首先通过车载智能终端设备收集汽车相关行驶数据,然后通过物联网卡(即sim卡)上报到平台,平台经过协议解析服务将数据转换成可读的数据并进行存储下来,并且需要把原始数据也保存一份。
数据处理:
将解析后的数据放到消息队列中,后端的各种应用服务开始处理不同的数据,例如轨迹服务会去消息队列中取出轨迹数据进行分析和处理。从而生成用户的行驶轨迹等功能;再例如故障检测服务,通过订阅消息队列中有关汽车传感器数值进行分析和判断该车辆是否存在故障。
数据分析:
部分行车数据经过各个模块的处理最终保存在数据库中,通过利用大数据分析进行特定场景的离线分析,例如驾驶行为分析服务通过分析用户每天驾驶行为(例如急加速,急减速,急转弯等行为)来判断用户的驾驶行为是否良好,等等。
数据展示:
用户通过下载并安装手机APP,注册登录App后用户可以在APP 上查看自己车辆的位置,轨迹查询,油耗,车辆故障以及交友,娱乐等功能。
1.2 应用架构介绍
防火墙:
当前在传统IDC机房中应用的最前端是一台防火墙,用来防御一些常见的攻击和访问控制的操作。因为防火墙并不是什么高端防火墙所以防御能力有限。因公司业务快速发展,期间已经更换过2次防火墙,分别是用户规模在10万和100万的时候。每次更换防火墙对业务都会造成不同程度的停服时间。用户体验很不好,但是没办法因为业务刚开始的时候用户不多,系统设计之初为10万级别,用户从0到10万规模用了1年左右时间。但是从10万到100万用户规模只有了7个月时间,用户增非常快,无奈又更换防火墙到能支撑到500万用户规模。再这么发展下去就不敢想象了。一是硬件设备成本越来越贵,往往投入几十万但是因为业务发展超出预期,刚买来的设备使用不到1年,又面临瓶颈又得换,真是费钱又费力。二是防火墙是所有业务的入口,如果防火墙出问题业务必然会挂,更换会导致业务停服,不更换防火墙会挂还是会停服。
负载均衡集群:
四层负载均衡集群采用LVS服务器,主要为后端的协议解析和数据处理服务提供负载均衡功能,因为单台协议解析服务最大每秒只能处理10000台车,所以lvs下挂了很多台数据采集服务器。这样可以满足每秒海量车辆同时在线。
七层负载均衡集群采用Nginx服务器,主要为后端web应用服务器提供负载均衡和反向代理功能,此外Nginx支持正则表达式和其他功能。
这一块我们目前遇到瓶颈是在IDC网络带宽扩容上,目前我们IDC机房如果对需要对网络带宽扩容需要提申请报备,内部走流程做完在到运营商那里走流程,时间往往比较长,最快也要1-2天,无法及对网络带宽做到快速扩容,当然也就无法应对突发流量增长。如果长期购买大量闲置带宽,本身是一种资源的浪费。毕竟目前国内优质的网络带宽资源成本还是相当高的。作为公司的运维同学,如何为公司开源节流,把每一分钱用在刀刃上是责任是义务更是一种能力。
应用服务器集群:
应用服务器操作系统统一采用Centos7,运行环境主要为JAVA环境和PHP环境,还有少部分Node.js环境
Java环境:采用Centos7 + JDK1.7 + Tomcat7
PHP环境:采用Centos7 + PHP5.6.11
Node.js环境:采用Centos7 + Node8.9.3
目前我们的应用开发语言有java 有php 有Python,web环境有tomcat,nginx,Node.js等环境,应用发布自动化程度不够高,大多还是脚本方式进行应用升级发布。通常应用发布升级工作都在半夜进行,加班非常严重。运维重复工作量非常大,导致运维成就感很低。大部分时间不是在解决问题就是在升级发布过程中。没有时间提升自身能力。运维人员开始陷入迷茫找不到方向,运维人员流失率逐渐增高,如果不得到有效解决,必将陷入恶性循环。
分布式服务集群:
分布式服务集群,采用Dubbo + ZooKeeper搭建的分布式服务框架。其中zookeeper的服务器需要保持奇数目的是便于选举。
Dubbo也是比较流行的JAVA应用的分布式服务框架,它是阿里开源的分布式服务框架。但是在使用过程中也发现由于没有一个比较好用的Dubbo监控软件,导致应用出现故障时排查故障很费力,如果有一套比较强大的链路跟踪监控系统对于那分布式应用来说是锦上添花了。
缓存集群:
缓存集群采用的Redis3.0 Cluster集群模式,该架构中有10套Redis缓存集群,每个集群的内存从60G-300G不等。缓存服务器是典型的内存型主机,对CPU开销不大,如果要做持久化,对磁盘IO要求较高,磁盘建议使用SSD。
对于缓存最大痛点在于运维,经常出现因磁盘IO瓶颈导致的redis集群故障,以及因用户快速增长需要经常对Redis集群进行在线扩容等。而且Redis运维都是只能是手动运维,工作量大,且容易误操作。因Redis集群而导致的故障不计其数。当然也跟当时的应用强依赖相关,Redis集群故障就导致整个应用也挂了,这是应用系统设计的缺陷。
消息队列集群:
由于在高并发环境下,系统来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。该架构中采用的是开源的Kafka作为消息队列,它是分布式的,基于发布/订阅的消息系统。具有高吞吐率,同时支持实时数据处理和离线数据处理。
这个消息队列的痛点也是刻骨铭心,kafka是开源软件,曾经遇到几次故障都是跟kafka有关系,在0.8.1,遇到kafka删除topic的功能存在bug,随后升级到09版本,不巧又遇到09版本kafka client的BUG,这个bug导致多分区多consumer时rebalancing可能会导致某个分区阻塞。后来升级kafka10版本,但是10版本的消费方式和08版本有差别,没办法又对消费程序进行改造。总之在我们使用kafka过程中遇到太多kafka的bug而导致的故障了。而我们中小企业技术能力有限没有能力第一时间修复这种开源软件的bug,处于非常被动和无奈的局面。
流计算集群:
流计算采用的阿里巴巴开源的Jstorm,利用流计算平台可以对实时数据进行处理和分析。该架构中使用2套流计算集群,每个流计算集群规模在8台高性能服务器。并且每个集群中包括2个supervisor管控节点,一主一备实现流计算高可用。流计算主要用于车辆告警,行驶轨迹等一些实时计算场景。
数据存储集群:
数据存储集群包含数据库集群和分布式文件系统。
数据库集群又包含多种数据库,例如MySQL数据库集群,MongoDB集群,Elasticsearch集群。
MySQL集群:公司目前拥有几十套大大小小的数据库集群,有的采用一主2从的高可用架构,有的是双主架构,这些MySQL数据库主要用于业务数据库。随着公司业务快速发展以及用户规模的快速增长,对数据库的性能要求也越来越高,从原来的高配虚拟机到后来的高配物理机,后来物理机的本地磁盘IO也满足不了要求,接着就开始上给数据库服务上SSD硬盘。现在勉强能维持着,在不久的将来,即便是目前最高配置的单台数据库服务器性能也不能满足的时候,我们怎么办?数据库团队需要提前掌握和了解未来的解决方案是什么,比如说分布式关系型数据库?
MongoDB集群:公司目前有3套MongoDB集群,主要用来存储车辆上报的原始数据,和解析后的车辆状态、点火、告警、轨迹等数据。采用的是副本集,通常由只是3个节点组成。其中一个是主节点,负责处理客户端请求,其余都是从节点,负责复制主节点上的数据。
Elasticsearch集群:ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。该架构中ES集群采用3个节点,这个3个节点都是候选主节点。这里我们主要用于轨迹查询,信息检索、日志系统等场景。
NFS分布式文件系统:
因为有大量的各类应用图片和用户上传的图片需要保存,所有需要一个高性能的文件存储,这里采用自建NFS分布式文件系统。
但是自建NFS分布式文件系统由于公司投入硬件设备有限,导致本身的扩展性是相当差的,而且需要停机相当影响业务。访问速度因客户端增加而变慢。这是个很影响用户体验的痛点,必须改造。
运维管控集群:
在复杂的系统架构和海量的服务器环境中,需要合适的运维管控软件来提升运维的工作效率。
监控:采用的是Zabbix开源监控系统;
代码管理:采用gitlab进行代码托管;
堡垒机:采用的是Jumpserver开源堡垒机,用于运维人员的操作审计和提升用户登录的安全性;
日志查询和管理:采用ELK,开源日志系统;
持续集成:我们采用的是Jenkins,它是一款开源持续集成工具,利用Jenkins可以实现代码构建,自动部署,自动测试等持续部署。
配置管理系统:提供应用的集中式配置管理,是基于java开发的配置管理。
虽然当前的运维体系还算比较规范,但是大多数运维工具都是开源的产品,只能满足部分功能需求。随着运维管控需求的增加,需要的熟悉的开源产品也越多。运维管理不够统一,运维人员通常需要熟悉和掌握很多运维系统,导致新手很难入手。
1.3 传统IDC架构痛点
随着用户规模与日俱增,慢慢的这套架构也暴露出很多问题来。
痛点1:运维自动化程度低,运维工作繁重且无意义
我们公司运维大部分时间还是处于人肉运维,脚本运维时代,运维自动化程度低,原因一是公司业务发展太快,运维人员每天大部分时间不是在处理应用升级就是在解决系统故障,根本没有时间去做运维自动的工作。其次运维开发方向的人才比较难招,也可能是开的薪水没有竞争力。总之各种原因导致我们公司在运维自动化进程上比较慢,有恶性循环的趋势。
痛点2:没有弹性扩容缩容能力,应对流量高峰代价高
因为车联网行业的一个特点就是早晚高峰和节假日期间车辆在线率飙升,然后进入平稳期。一天24小时有6个小时是早晚高峰,其余18个小时是正常流量,通常高峰期流量是平常的3-5倍。传统IDC通常需要几天时间才能完成一次线上扩容,根本不可能应对突发性的流量暴涨的情况。我们为了保障系统稳定性以及保障用户体验,只能是投入比平时多几倍的资源,整体资源利用率不到30%,产生巨大资源浪费。
痛点3:运维工具零散、运维工作复杂繁琐
我们公司的运维管控软件绝大部分是以开源为主的运维软件,种类繁多,例如开源跳板机Jumpserver,zabbix监控系统,持续集成Jenkins,自动化运维Ansible等等,这些软件都需要配置独立的登录账号。导致账号繁多,管理非常不方便,运维人员需要操作和熟悉很多开源软件。例如zabbix监控在规模不大的时候基本能应付日常的监控告警,但是随着服务器的增加导致监控项的急剧增加之后,数据库性能跟不上,告警延迟或者误报的情况非常多。一些定制监控需求和监控项目仍需要单独开发。所以运维工具种类繁多也直接导致运维工作的复杂繁琐。
痛点4: 硬件设备采购周期长,成本高,扩展性差
我们公司应用刚上线的时候系统各方面的设计比较简单,横向扩展能力不强,随着业务爆发式增长,因为我们很多资源无法及时扩展,导致系统故障,用户体验降低。例如文件存储,刚开始的时候我们是自建的NFS文件存储,用于存放用户头像,驾驶证,朋友圈等图片文件。由于各方面原因当初没有投入足够的资源建设,导致一段时间之后存储就不够用,读写性能下降,用户访问延迟等等。最痛的一点是硬件设备的扩展周期长,从提出采购需求到最后的实施硬件扩展,往往需要5-10天甚至更长,因为这期间需要经历采购审批流程,物流发货,到货验收,机房上架等。
痛点5:基础设施可靠性差,故障频发
传统IDC底层基础设施通常都是企业自己搭建的,这里会有很多原因导致底座基础设施不稳定的因素。例如企业一开始对硬件投入不重视,使用廉价的设备;再例如工程师技术能力有限,搭建的基础设施架构稳定性差强人意;例如遇到运营商网络质量不稳定,也没有BGP接入,这个时候也只能干瞪眼了。另外我们的IDC机房一年当中遇到过3次意外断电,导致大面积系统瘫痪。所以说底层基础设施不稳定会导致后续应用经常出现莫名其妙的故障,而且无法及时定位,找不到原因。随时会出现意想不到的问题,每天都是提心吊胆的。
痛点6:安全防护能力弱,易受攻击
随着公司快速发展和用户规模的增长的同时,很容易被别有用心的人盯上,记得有一天下午3点左右,突然遭受到大量DDOS攻击,我们的防火墙一下就被打垮了,系统瞬间就瘫痪了,没有办法,什么都做不了,防火墙已经跪了,登不上去了,一直持续几个小时,业务也瘫痪了几个小时,一点办法没有。我们的安全防护能力真的很弱,也跟成本有关,高端的防火墙买不起,还有运营商的带宽也很贵。