为何要去 hack?
在业务开发过程中,往往会依赖一些 Node.js 模块,hack 这些 Node.js 模块的主要目的是在不修改工具源码的情况下,篡改一些特定的功能。可能会是出于以下几种情况的考虑:
- 总是存在一些特殊的本地需求,不一定能作为工具的通用需求来暴露正常的 API 给更多的用户。
- 临时且紧急的需求,提 PR 已经来不及了。
- 为什么不直接去改源码?考虑到工具会不定期升级,想使用工具的最新特性,改源码可维护性太差。
期望
举个栗子:
// a.js |
b 是项目 c 依赖的一个工具模块,b 依赖 a。希望只在项目 c 中,b 调用 a 时,a 的函数里能注入一些方法 injectSomething()
- hack 之前 c 的输出
function(){ |
- 期望:hack 之后 c 的输出
function(){ |
具体案例比如:在做个人自动化工具时,需要 mock 一些工具的手动输入;在本地构建时,需要修改通用的构建流程(后面案例部分会详细说)
主要方法
利用模块 cache 篡改模块对象属性
这是我最早使用的方法,在模块 a 的类型是 object 的时候,可以在自己的项目 c 中提早 require 模块 a,按照你的需求修改一些属性,这样当模块 b 再去 require 模块 a 时,从缓存中取出的模块 a 已经是被修改过的了。
模块 a、b、c 栗子如下:
// a.js |
我想修改 a 的方法 p,在 c 中进行如下修改即可,而无需直接去修改工具 a、b 的源码:
// c.js |
缺陷:在某些模块属性是动态加载的情况,不是那么灵敏,而且只能篡改引用对象。但大部分情况下还是能够满足需求的。
修改require.cache
在遇到模块暴露的是非对象的情况,就需要直接去修改 require 的 cache 对象了。关于修改 require.cache 的有效性,会在后面的原理部分详细说,先来简单的说下操作:
//a.js 暴露的非对象,而是函数 |
缺陷:可能后续调用链路会有人手动去修改 require.cache,例如热加载。
修改 require
这种方法是直接去代理 require ,是最稳妥的方法,但是侵入性相对来说比较强。Node.js 文件中的 require 其实是在 Module 的原型方法上,即 Module.prototype.require。后面会详细说,先简单说下操作:
const Module = require('module'); |
缺陷:对整个 Node.js 进程的 require 操作都具有侵入性。
相关原理
node的启动过程
我们先来看看在运行 node a.js 时发生些什么?node源码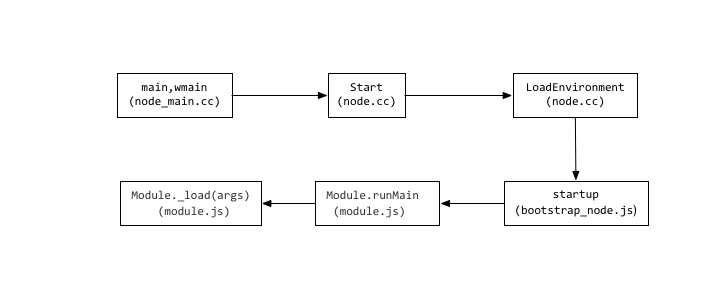
上图是node运行 a.js 的一个核心流程,Node.js 的启动程序 bootstrap_node.js 是在 node::LoadEnvironment 中被立即执行的,bootstrap_node.js 中的 startup() 是包裹在一个匿名函数里面的,所以在一次执行 node 的行为中 startup() 只会被调用了一次,来保证 bootstrap_node.js 的所执行的所有依赖只会被加载一次。C++ 语言部分中:
//node_main.cc 如果在win环境执行wmain(),unix则执行main(),函数最后都执行了node::Start(argc, argv) |
在 bootstrap_node.js 中,会去执行 Module 的静态方法 runMain,而 runMain 中则去执行了 Module._load,也就是模块加载的过程。
// bootstrap_node.js |
一个进程只存在一个 cache 对象?
先来看看 module._load 干了什么?
Module._load = function(request, parent, isMain) { |
可以看到,在 load 的一个模块时,会先读缓存 Module._cache,如果没有就会去 new 一个 Module 的实例,
然后再把实例放到缓存里。由前面的 Node.js 启动过程可以知道, bootstrap_node.js 中的 startup() 只会执行了一次,其中产生的 Module 对象在整个node进程调用链路中只会存在一个,进而 Module._cache 只有一个。
Module._cache 和 require.cache 的关系
可以看下 Module.prototype._compile 这个方法,这里面会对大家写的 Node.js 文件进行一个包装,注入一些上下文,包括 require:
var require = internalModule.makeRequireFunction.call(this); |
而在 internalModule.makeRequireFunction 中我们会发现
// 在 makeRequireFunction 中 |
所以,Module._cache 和 require.cache 是一样的,那么我们直接修改 require.cache 的缓存内容,在一个 Node.js 进程里都是有效的。
require 不同场景的挂载
最开始我以为 require 是挂载在 global 上的,为了图省事,一般用 Node.js repl 来测试:
$ node |
可以看到,repl 下,global.require 是存在的,如果以为可以直接在 Node.js 文件中代理 global.require 那就踩坑了,因为如果在 Node.js 文件中使用会发现:
console.log(global.require); |
从上文可知,Node.js 文件中的 require 其实是来自于 Module.prototype._compile 中注入的 Module.prototype.require, 而最终的指向其实是 Module._load,并没有挂载到 module 上下文环境中的 global 对象上。
而 repl 中也是有 module 实例,于是我尝试在 repl 中打印:
$ node |
结果有点奇怪,于是我继续探究了下。在 bootstrap_node.js 中找到 repl 的调用文件 repl.js
const require = internalModule.makeRequireFunction.call(module); |
得到结论:在 repl 中,module.require 和 global.require 最终的调用方法是一样的,只是函数指向不同而已。
注意点
path路径
require.cache 是一个 key、value 的 map,key 看上去是模块所在的绝对路径,然而是不能用绝对路径直接去用的,需要 require.resolve 来解析路径,解析后才是 cache 中正确的 key 格式。
下面对比下区别:
// 模块的绝对路径 |
多进程的情况
模块间调用的链路比较长,有可能会新建子进程,需要考虑你项目中的入口文件和你需要代理的文件是否在一个进程中,简单的方法就是在入口文件和你需要代理的文件打印 pid:
console.log(process.pid) |
如果一致,那么直接在入口调用前代理即可,否则情况会更复杂点,需要找到相应的进程调用处进行代理。
案例
DEF 是淘宝前端的集成开发环境,支持前端模块创建、构建打包、发布等一系列流程。 在以下案例中,主要 hack 的 Node.js 项目便是 DEF。
篡改输入(prompt)
场景:使用 DEF 创建模块 or 发布模块时
原因:想一键完成批量创建 or 批量发布,不想手动输入。
解决过程:以创建模块为例
-
首先找到 DEF 的入口文件,即一个 bin 目录下的路径,可以通过这个入口文件不断追溯下去,发现创建模块的 generator 用的是 yeoman-generator 的方法。对 prompt 的方法进行代理,可以将该基础库提前 require,更改掉其 prompt 的方法即可。
-
附上示例代码(示例只篡改
def add模块的创建类型,其他输入的篡改方法类似):
|
篡改构建流程(webpackconfig)
场景:一个淘宝的前端组件,需要在使用def本地调试时提前更改一个文件内容。(淘宝组件的构建会按照组件类型统一构建器,并不是每个组件单独去配置)
原因:一般来说,这种情况可以选择注释代码大法,本地调试时打开注释,发布前干掉。但这样造成代码很不美观,也容易引起误操作。不妨在本地调试的 reflect 过程中动态更换掉就好了。
解决过程:
-
追溯
def dev调用链路,找到最终reflect的文件, 在这个构建器@ali/builder-cake-kpm项目里。所使用的webpack的配置项在@ali/cake-webpack-config下。 -
现在就是往 webpack 配置项里动态注入一个 webpack loader 的过程了,我需要的 loader 是一个 preLoader,代码非常简单,我把它放在业务项目的文件里:
module.exports = function(content) { |
-
@ali/cake-webpack-config暴露的是个函数而非对象,所以必须从 require 下手了,最后附上案例的代理过程:
|
结束语
去 hack 一个 Node.js 模块,需要对该 Node.js 模块的调用链路有一定的了解,在很多情况下,不一定是最优的方法,但也不失为一种解决方案。有趣的是,Node.js 源码中其实有一行这样的注释:
// Hello, and welcome to hacking node.js! |
So, just hacking for fun!
作者:宣予
转载自:http://taobaofed.org/blog/2016/10/27/how-to-hack-nodejs-modules/