以下内容根据演讲PPT以及现场分享整理而成。
本次分享的主要内容
一、数据上云面对的问题
二、解决方案
三、方案优势
一、数据上云面对的问题
现在大家在使用云数据库的时候,可能会遇到的一个很大的问题就是:如何将海量的数据迁移到云端上去。当然在数据迁移的过程中还有可能会遇到网络问题,当网络时好时坏,可能数据上传过程中网络突然断掉,那么几个G或者几十个G的任务就挂掉了,需要重新再导入一遍。还有一个问题就是使用阿里云的各个数据产品时,如何在这些数据产品之间进行数据互通。
二、解决方案
面对这些问题,阿里云也为大家提供了一些解决方案和工具。
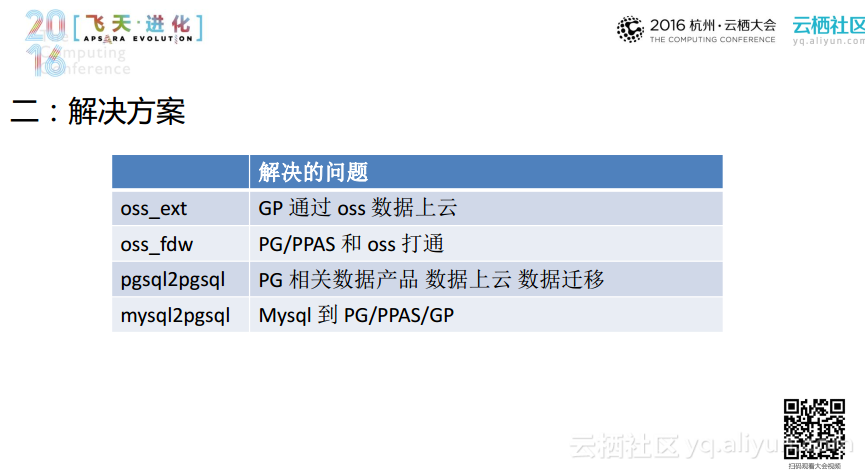
- 第一个工具是oss_ext,它在Greenplum上支持OSS的外表,这个OSS外表将数据通道从OSS打通到Greenplum,其表现形式是在Greenplum中创建一张表,而这张表可以从OSS中导入数据,并且以文本文件的形式存储在OSS上面,并且可以通过文件名进行前缀匹配。简单来说,使用几条SQL语句就可以将OSS上面的数据导入到Greenplum上面去。
- 第二个工具是oss_fdw,通过它可以将OSS和PG以及PPAS打通,在交易型业务上获取的数据可以很容易地存储到OSS上并且最终导入到Greenplum上,所以通过云做交易业务的用户能够很容易地将数据导入到Greenplum进行数据分析。
- 第三个工具是pgsql2pgsql,它支持了整个Postgre家族,从PPAS到Greenplum都是兼容的,只需要经过简单的配置就可以将数据从一端保存到另一端。
- 第四个工具就是mysql2pgsql,它可以使MySQL数据库的数据很容易地导入到Greenplum上面来。
对于整个解决方案而言,每个工具都具有一些特点。
首先,OSS是阿里云上非常廉价的存储服务,它可以和云上所有的数据产品进行打通,并且其收费非常便宜,按照存储量和请求次数进行收费,具体的收费规则在阿里云官网上大家可以看到。
总体而言,使用OSS的成本是相当低的。
- oss_ext的特点是使用驱动segment对于数据进行装载和导入,并且也支持Greenplum,其数据导入导出性能非常高。
- 对于oss_fdw来说,它可以支持PG和PPAS,而且数据的格式完全和之前的数据格式兼容,对数据进行读写没有任何障碍。
- pgsql2pgsql的特点是数据可以在整个PG家族之间进行来回迁移,值得一提的就是在某些场景下还能够支持增量。
- mysql2pgsql的特点就是,MySQL上面的数据通过它可以很容易迁移到PG家族中去。
整个方案都是以OSS为存储中心,交易型的业务都可以使用OSS作为数据的中间介质进行导入导出。
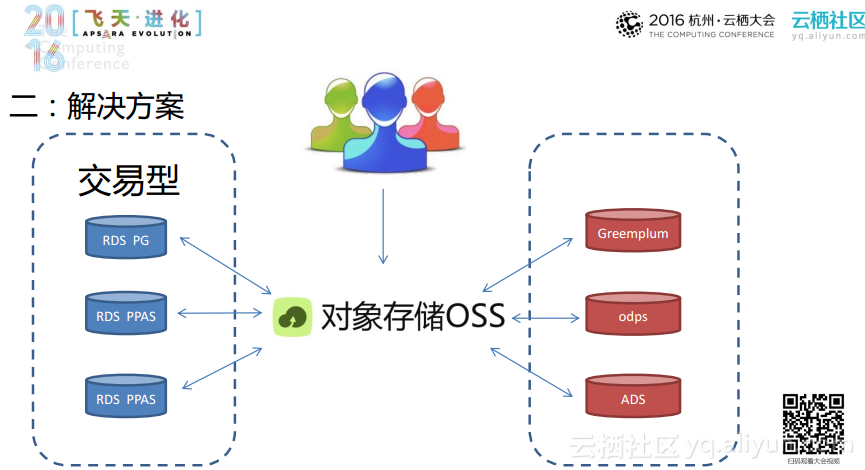
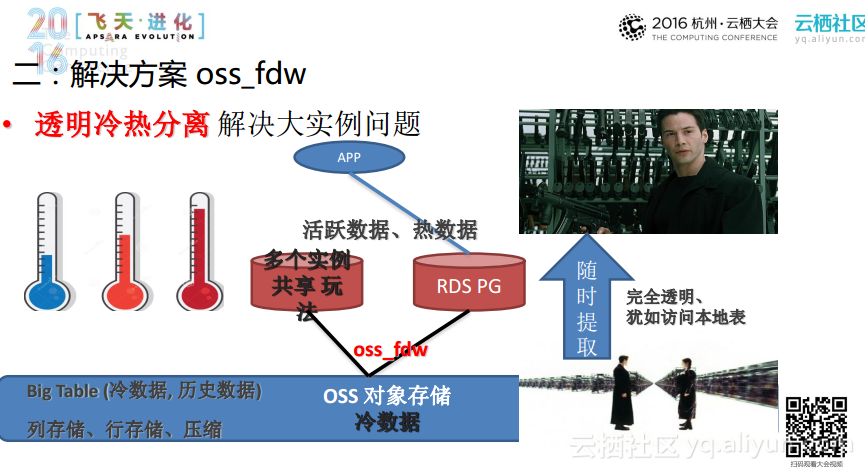
之前在单节点的RDS上面可能会遇到问题就是:购买实例的存储是有限制的。一般而言存储就是几个T,但是一些含有历史数据的表会非常庞大,占据了大量的存储空间,但是对于这些表格查询的次数往往比较少,也就是属于常说的冷数据。面对这样的场景,可以使用OSS对其进行存储,以此将这些冷数据原本占据的大量的存储空间释放掉,当需要的时候再将其导入到数据库中。其实当数据表存储到OSS上面时,也可以非常容易地访问到,只不过性能稍微弱一点,花费的时间稍微长一些。
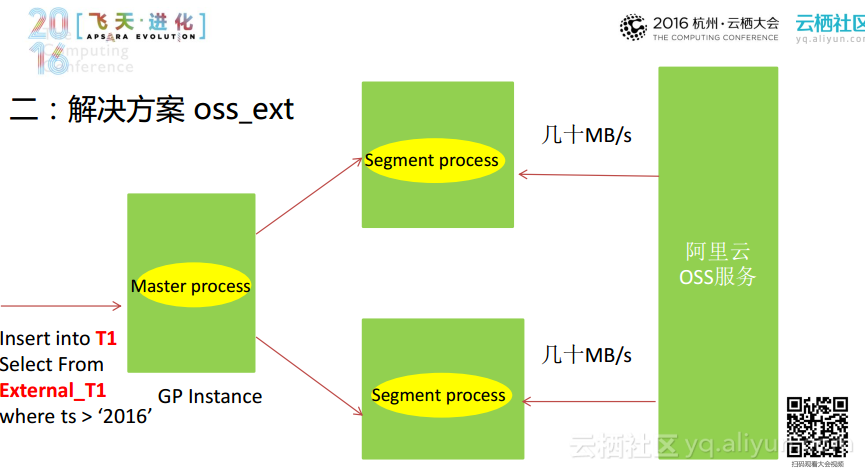
接下来分享一下Greenplum上的OSS插件的工作原理,我们都知道这样的架构主要由一个主节点和多个计算节点组成。读写的过程中完全让segment进行计算,充分利用segment上面的计算资源、内存和网络。
Greenplum上的OSS插件有很多丰富的特性。
- 支持分布式并行数据加载,读写数据的性能随集群segment节点数线性增长,集群越大,性能越强。
- 支持自定义格式的文本文件,可以自定义分隔符,自定义数据格式。
- 支持多种OSS文件匹配模式,存放非常灵活。
- oss_fdw、oss_ext都支持容错模式,对于一个含有上亿条数据的任务而言,当发现几条或者几十条错误的时候,任务会继续执行,并且将错误记录下来,不会由于某些错误而使得整个过程终止。
- 支持丰富的性能调优参数。
- 支持网络超时自动重试。
- 安全特性支持OSS id key 加密存储和隐藏显示。
OSS插件在未来还会支持更多的特性,很多的特性都是根据阿里云客户在实际使用中挖掘出来的,未来阿里云OSS将会对这些特性进行更好地支持。
- 未来会支持读写多种压缩文件,进一步降低使用成本。
- 扩展多样的读写模式,比如覆盖写模式和追加写模式。
- 面对现实场景下的CPU性能导致的数据导入导出瓶颈,未来OSS将会采取一些方案来优化CPU,提高数据的导入和导出速度。
- 未来会做同一个外表放在同一个目录,使用OSS文件前缀进行匹配,使文件命名更加方便。
Greenplum已经支持的其他特性
三、方案优势
使用Greenplum上的OSS插件的方案具有很多优势。
1.使用OSS
OSS的使用成本比较低,并且可以跨各数据库产品进行支持,可以跨可用区进行数据同步。对于冷数据转存到OSS,依然可以当做表访问,只不过性能表现略微降低。
2.并行导入性能高于常规数据导入导出方式
充分利用每个数据节点的CPU、内存、网络等硬件资源,举个例子对于650G的数据,大约20亿行文本数据需要导入到32个segment的Greenplum集群只需要大约35分钟。
3.各数据产品间灵活的交换数据
4.pgsql2pgsql
可以支持不落地数据迁移,pg、ppas大于9.4的版本可以支持基于逻辑复制的增量迁移。
5.mysql2pgsql
可以支持不落地数据迁移,支持多表并发,支持基于条件的增量。
6.工具现在已开源到GitHub
https://github.com/aliyun/rds_dbsync

