在2016杭州云栖大会首日,来自华大基因的基因组学数据专家黄树嘉在大数据专场分享了《基于数加MaxCompute的极速全基因组数据分析》,他主要从全基因组测序的背景与原理、传统单机分析流程的挑战、基于MaxCompute的方案三个方面进行了分享,详细介绍了华大基因运用阿里云处理海量的实践。
以下内容根据演讲PPT及现场分享整理。
什么是基因
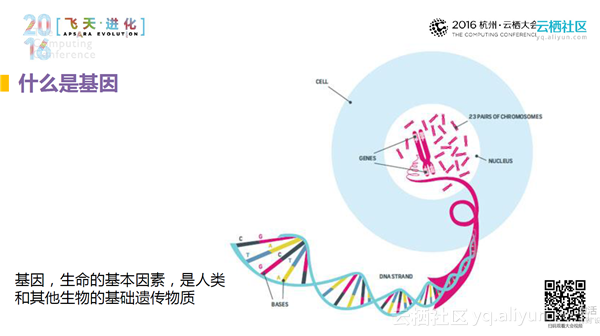
基因是生命的基本因素,是人类和其他生物的基础遗传物质。细胞内有染色体,染色体是由一个一个的DNA碱基组成的,这些DNA碱基表现出来的是一个个的字符串。人共有23对染色体,有30亿个碱基对,我们在处理的过程中可以把它看作30亿量级的字符串。一个人拥有这么大的数据量,我们在对其进行解读的时候,为了保证数据的准确性,需要有几十层数据的解读。30亿个碱基对多么重要?一个人生老病死、健康与否的信息都会存储在基因中,所以,所进行的关于健康数据的研究是更直接的、更加面向这个人的本质。
什么是基因测序
如何获得细胞里面的数据?获得基因数据需要有一定的专用仪器,通过物理或者化学的相应方法,把处于细胞中的相应数据读取出来、数字化,我们才能对其进行相应的解读。
基因数据

为什么基因数据的数据量非常大?从上图中可以看出,我们的基因数据不仅仅是来自细胞核中的基因组,其还包括转录组、表现组(比如肠道卫生基因组、表观基因组等)、宏基因组等。这些数据加起来大约会有10T的数量级。基因数据的分析过程包括:测序,即从化学信号转为数字信号;数据记录成相应的数据格式;解读、比对、数据分析,以此来知道这个人为什么会如此的不同?为什么容易患病?为什么能够千杯不倒?为什么代谢咖啡的速度会特别快?最终形成数据报告。
传统单机分析流程的挑战
挑战1:流程繁杂,标准难统一
由于基因行业是一个比较新的行业,各个企业的标准难以统一。在分析过程中,会有很多步骤,而且每个步骤都会包含很多分析脚本,系统命令和外部工具,工具要被反复手动部署到计算集群,导致分析流程变得比较繁杂。随着基因组测序成本的降低,其测序的数据量不断提升,这种低效的方法已经阻碍了基因行业的发展。
挑战2:命令行操作、交互性差

繁杂的命令行操作导致了交互性能的低下。
挑战3:时间长
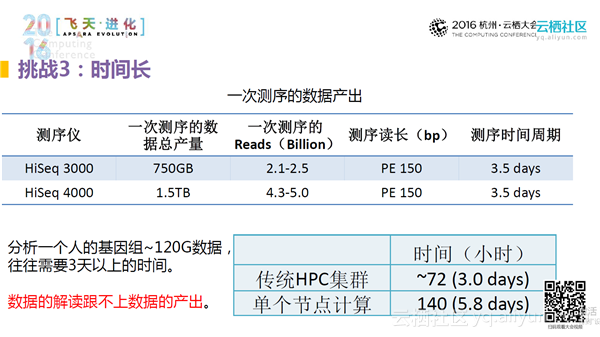
最致命的问题是分析时间过长。目前最先进的测序仪每一次测序的数据产量是1.5TB(大约为150人的数据量),并且产出这些数据的时间为3.5天。用传统的HPC集群进行分析的话,基本需要3天的时间来分析一个人的数据,而单个节点的话则需要5.8天的时间。由此可以看出,数据解读的效率远远跟不上数据的产出速度,这就为精准医疗后续的发展带来了极大的挑战。因为精准医疗就是要精准到个人的个性化用药,每个人的所有性状信息只有通过基因数据的分析才能做到个性化医疗。
基于MaxCompute的方案
如何及时的把这么多的数据解读出来,是现如今面临的挑战。为了解决上述挑战,提出了基于MaxCompute的解决方案。
MaxCompute分布式计算
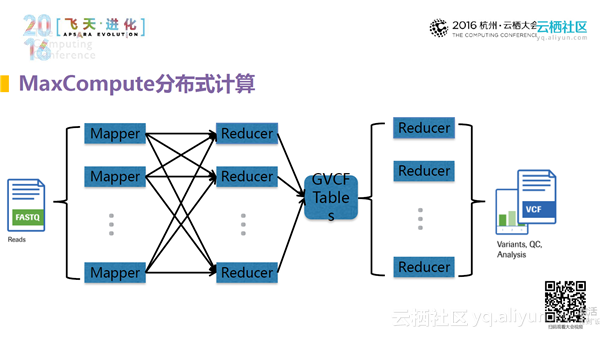
把最常用的基因组的解读放在了MaxCompute上部署,这个过程与单机部署的过程完全不一样。此过程需要把产出数据到得到最终结果的过程中的每一步利用MaxCompute的思维将其分散出去,然后把如何去并行、如何加快有效速度在过程中呈现出来。
加速情形
搭建出这个流程之后,一个人的基因数据总共测了52层(即测试了52倍,大约为120G的数据量),该测试基本在3个小时之内就完成了分析,比单机提升50+倍,比HPC集群提升25+倍,比Hadoop集群提升6+倍。
群体测试
实际上,在基因解析的过程中,是多人同时分析的。每个人都是属于一定的群体的,我们要更好的解读这个人,就必须放在对应的群体中,而且基因组数据只有你将人放在群体中来分析才能够更加准确、更具有表达力。从华大数据中抽取了50个人的基因进行测试,整个测试分解为两大步骤、七万多任务量的提交,只消耗了41.5个小时就完成了50个人的整体基因组的分析,平均每个人只需要花费50分钟进行测试。

为什么单个人需要3个小时,50个人反而是41个小时而不是150个小时?在人群中分析基因组数据时,很多中间的步骤其实可以分散出去,最后并不需要每个人一个一个的去读取,而是群体分析数据情况,因此,时间状态总的来讲是缩短了。如果人数由50人加到更多的话,每个人的平均测试时间可以进一步的降低。
总的来说,50个人处理的数据量大约为2T,最终解读出来的有意义的数据量是21G,这样就实现了从海量计算,从原始数据到精确数据的变异。

