欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
在上一篇文章中,已经介绍了Keras对文本数据进行预处理的一般步骤。预处理完之后,就可以使用深度学习中的一些模型进行文本分类。在这篇文章中,将介绍text-CNN模型以及使用该模型对imdb影评数据集进行情感分析。
正如上篇文章所说,文本分类的关键在于准确提炼文档或者句子的中心思想,而提炼中心思想的方法是抽取文档或句子的关键词作为特征,基于这些特征去训练分类器并分类。每个类别可以理解为一种中心思想,如情感分析中,分类器将样本分为两类,一类为正面评论,另一类为负面评论,而正面和负面评论正是该文本或句子的中心思想。对于思维敏锐的读者来说,当说到提取特征的时候,可能就能想到为什么卷积神经网络可以很好进行自然语言处理。没错,就是因为卷积和池化过程就是一个抽取特征的过程,当我们可以准确抽取关键词的特征时,就能准确的提炼出文档或句子的中心思想。
卷积神经网络首次应用于文本分类可以说是在2004年Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文中提出(虽然第一个用的并不是他,但是在这篇文章中提出了4种Model Variations,并有详细的调参),本文也是基于对这篇文章的理解。接下来将介绍text-CNN模型,并使用Keras搭建该模型对imdb数据集进行情感分析。
text-CNN模型
由于上篇文章已经将Embedding层讲过了,在这里就不再叙述。主要讲解卷积层、池化层和全连接层。
1.卷积层
在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致!!!这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度,如果我们使用卷积核的宽度小于词向量的维度就已经不是以词作为最小粒度了。而高度和CNN一样,可以自行设置(通常取值2,3,4,5)。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。(类似于skip-gram和CBOW模型的思想)。
详细讲解卷积的过程:卷积层输入的是一个表示句子的矩阵,维度为n*d,即每句话共有n个词,每个词有一个d维的词向量表示。假设Xi:i+j表示Xi到Xi+j个词,使用一个宽度为d,高度为h的卷积核W与Xi:i+h-1(h个词)进行卷积操作后再使用激活函数激活得到相应的特征ci,则卷积操作可以表示为:(使用点乘来表示卷积操作)
因此经过卷积操作之后,可以得到一个n-h+1维的向量c形如:
以上是一个卷积核与输入句子的卷积操作,同样的,我们也可以使用更多高度不同的卷积核,且每个高度的卷积核多个,得到更多不同特征。
2.池化层
因为在卷积层过程中我们使用了不同高度的卷积核,使得我们通过卷积层后得到的向量维度会不一致,所以在池化层中,我们使用1-Max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当我们对所有特征向量进行1-Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
3.全连接层
全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上’relu’作为激活函数,第二层则使用softmax激活函数得到属于每个类的概率。如果处理的数据集为二分类问题,如情感分析的正负面时,第二层也可以使用sigmoid作为激活函数,然后损失函数使用对数损失函数’binary_crossentropy’。
4.text-CNN的小变种
在词向量构造方面可以有以下不同的方式:
CNN-rand: 随机初始化每个单词的词向量通过后续的训练去调整。
CNN-static: 使用预先训练好的词向量,如word2vec训练出来的词向量,在训练过程中不再调整该词向量。
CNN-non-static: 使用预先训练好的词向量,并在训练过程进一步进行调整。
CNN-multichannel: 将static与non-static作为两通道的词向量。
使用网上的一张经典图进一步讲解text-CNN
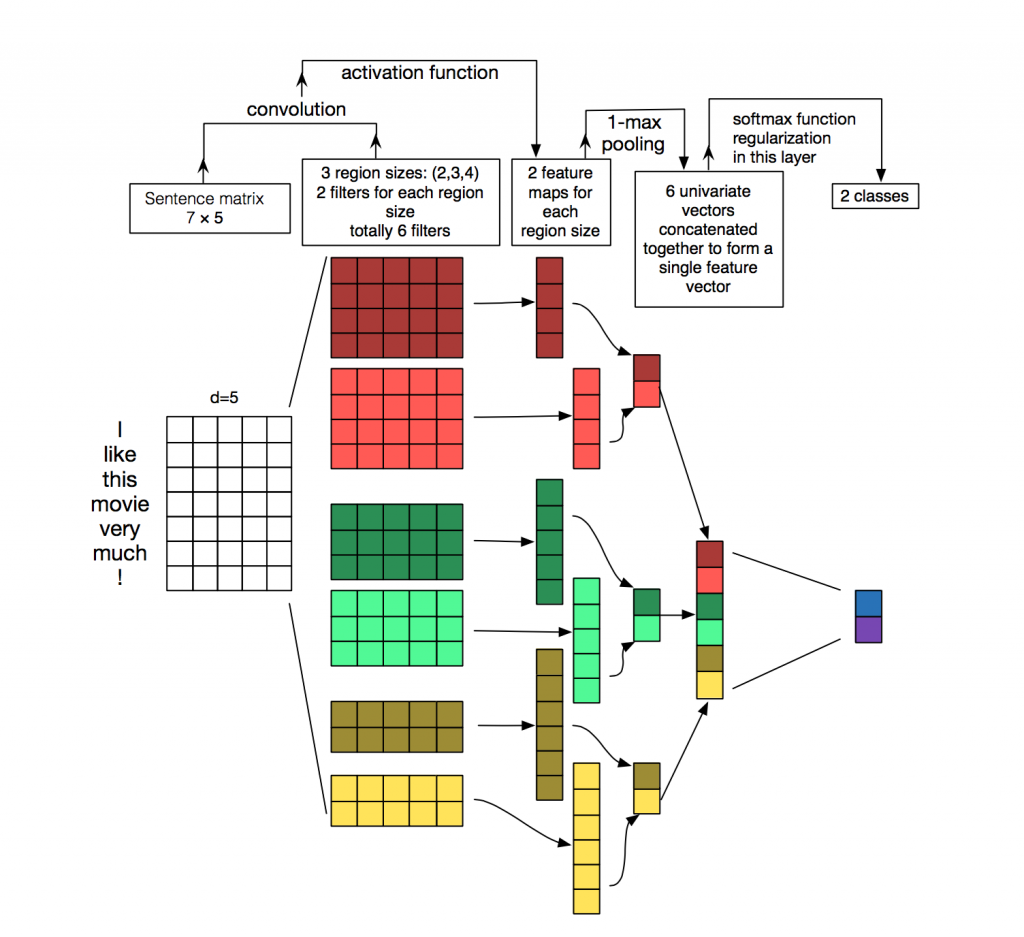
在上图中,输入了一句话”I like this movie very much!”,其对应的句子矩阵维度为7*5,每个词用维度为5的词向量表示。在卷积层中,分别使用高度为4,3,2的卷积核,且每种卷积核有2个。卷积之后得到6个对应的特征向量,维度从上往下分别为4,4,5,5,6,6,然后对每个向量进行1-Max-pooling,再拼接起来一个维度为6的特征向量。最后通过全连接层,激活函数为softmax得到2个类别的概率。
使用text-CNN模型对imdb数据集进行情感分析
从上文对text-cnn模型的介绍,想必读者对该模型已经有了初步的理解了。趁热打铁,我们将利用Keras搭建该模型并对imdb数据集进行情感分析。由于数据集预处理部分上一篇文章已经讲解,在此将不再叙述。在搭建模型之前,先讲解用到的一些主要函数:
卷积过程由于只是沿着高度方向进行卷积,即只在一个维度卷积所以使用Conv1d。
Conv1d(filters, kernel_size, activation):
filters: 卷积核的个数
kernel_size: 卷积核的宽度
activation: 卷积层使用的激活函数
池化过程使用的在一个维度上的池化,使用MaxPooling1D
MaxPooling1D(pool_size):
pool_size: 池化窗口的大小,由于我们要将一个卷积核得到特征向量池化为1个值,所以池化窗口可以设为(句子长度-卷积核宽度+1)
池化过程最后还需要对每个值拼接起来,可以使用concatenate函数实现。
concatenate(inputs, axis):
inputs: inputs为一个tensor的list,所以需要将得到1-MaxPooling得到每个值append到list中,并把该list作为inputs参数的输入。
axis: 指定拼接的方向。
了解了这几个函数的用法之后,我们就可以搭建我们的模型如下图。
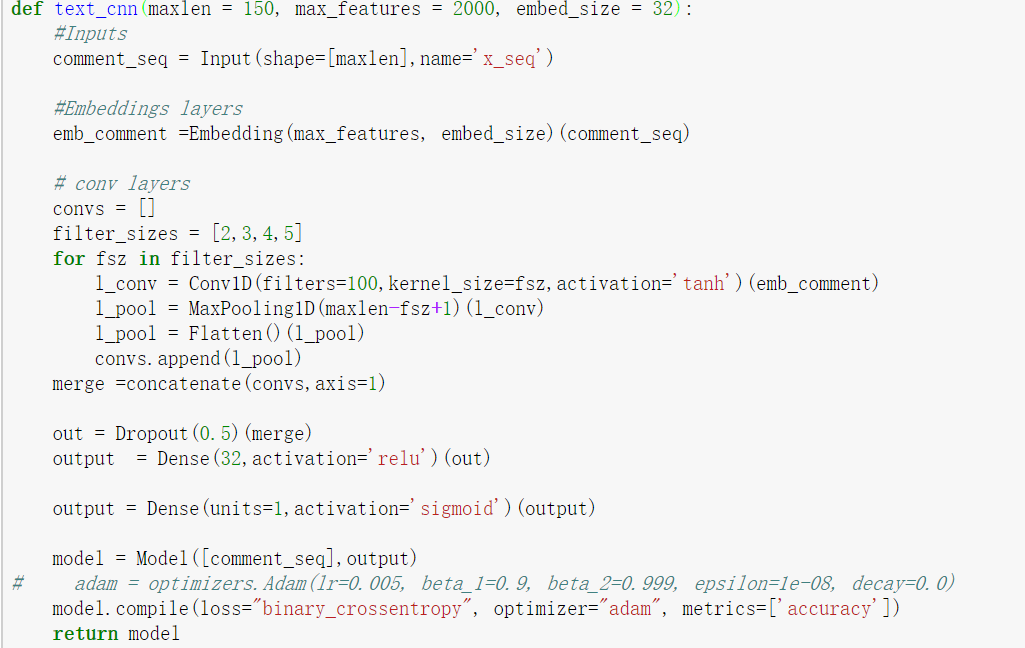
基于上篇文章对imdb数据集中影评处理后,得到每个句子长度(maxlen)为150,共有2000个词(max_features),词向量维度为32(embed_size)。在该模型中,使用了高度分别为2,3,4,5的四种卷积核,每种卷积核100个,最后使用sigmoid作为激活函数,损失函数使用对数损失函数。

模型训练过程batch_size设为64,epochs为10,最终可以在验证集可以得到86.5%的准确率。
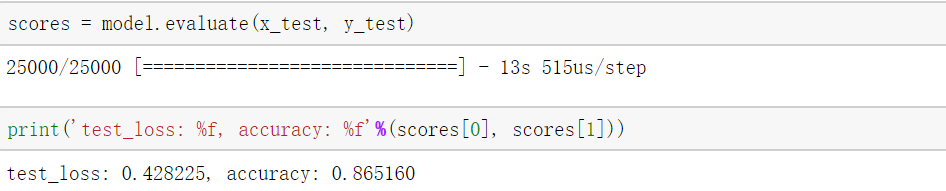
至此我们已经实现了使用text-CNN模型对imdb数据集进行情感分析,准确率还算可以,有兴趣的读者可以基于该模型进行改进,得到更高的准确率。
完整代码可到以下链接下载:
https://github.com/hongweijun811/wjgit/blob/master/text_cnn_demo.py
