# 写一个类 定义100个对象
# 拥有三个属性 name age sex
# 如果两个对象的name 和 sex完全相同
# 我们就认为这是一个对象
# 忽略age属性
# 做这100个对象的去重工作
class Person:
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
def __hash__(self):
# hash算法本身就存在了 且直接在python中就能调用
# 姓名相同 性别相同的对象的hash值应该相等才行
# 姓名性别都是字符串
return hash(self.name+self.sex)
def __eq__(self, other):
if self.name == other.name and self.sex == other.sex:
return True
# python2.7
# 去重 set
# hash方法
# set([obj,obj]) unhashable
# hash算法 一个值 进行一系列的计算得出一个数字在一次程序执行中总是不变
#来让每一个不同的值计算出的数字都不相等
obj_lst = []
obj_lst.append(Person('alex',80,'male'))
obj_lst.append(Person('alex',70,'male'))
obj_lst.append(Person('alex',60,'male'))
obj_lst.append(Person('boss_jin',50,'male'))
obj_lst.append(Person('boss_jin',40,'male'))
obj_lst.append(Person('boss_jin',30,'male'))
obj_lst.append(Person('nezha',20,'male'))
obj_lst.append(Person('nezha',10,'male'))
obj_lst = set(obj_lst)
for obj in obj_lst:print(obj.name)
这段代码为什么能够实现这个功能:因为object类中是带hash方法和eq方法的,这里重新定义了定义了hash方法和eq方法,让这个方法按自己的意愿来执行我们想要的结果。我们在类中实例化这些对象之后,集合在对这些对象的去重的时候,
因为我们定义的hash方法就是去比较self.name + self.sex 的hash值 所以在去重的时候只要这两个属性时相同的的,的出来的hash值就一样所以就可有过滤掉。
由此我们可以知道集合去重的的底层原理,为什么他可以那么快。因为集合既用了hash方法金还用了eq方法,把每个元素存在一个内存地址,然后通过每个元素的hash值去找他,当出现了两个元素的相同的时候,就出现了一样的hash值,就指向了同一个内存地址
这时候就用到eq比较的方法,两个元素如果是一模一样又指向同一内存地址,自然就会删除一个。
json 和 pickle 模块
# dumps序列化 loads反序列化 只在内存中操作数据 主要用于网络传输 和多个数据与文件打交道
# dump序列化 load反序列化 主要用于一个数据直接存在文件里—— 直接和文件打交道
import json dic= {'name':'fuck','age':22} ret = json.dumps(dic) 序列化 print(ret) r = json.loads(ret) 反序列化 print(r) #### {"name": "fuck", "age": 22} {'name': 'fuck', 'age': 22}
连续写入文件 然后再输出
dic1 = {"大表哥":(190,90,'捏脚')}
dic2 = {"2表哥":(190,90,'捏脚')}
dic3 = {"3表哥":(190,90,'捏脚')}
str1 = json.dumps(dic1)
f = open('大表哥','a',encoding='utf-8')
str1 = json.dumps(dic1)
f.write(str1+'\n')
str2 = json.dumps(dic2)
f.write(str2+'\n')
str3 = json.dumps(dic3)
f.write(str3+'\n')
f.close()
f = open('大表哥','r',encoding='utf-8')
for line in f:
print(json.loads(line.strip()))
f.close()
pickle
f = open('hehe','wb')
dic1 = {"大表哥":(190,90,'捏脚')}
pickle.dump(dic1,f)
dic2 = {"2表哥":(190,90,'捏脚')}
pickle.dump(dic2,f)
dic3 = {"3表哥":(190,90,'捏脚')}
pickle.dump(dic3,f)
f.close()
f1 = open('hehe','rb')
# print(pickle.load(f1))
# print(pickle.load(f1))
while True:
try:
print(print(pickle.load(f1)))
except EOFError:
break
# json 在写入多次dump的时候 不能对应执行多次load来取出数据,pickle可以
# json 如果要写入多个元素 可以先将元素dumps序列化,f.write(序列化+'\n')写入文件
# 读出元素的时候,应该先按行读文件,在使用loads将读出来的字符串转换成对应的数据类型
还可以把类的对象写进去
class A():
def __init__(self,name,age):
self.name = name
self.age = 23
f = open('hehe','bw')
a = A('yy',20)
pickle.dump(a,f)
f.close()
s = open('hehe','br')
k = pickle.load(s)
print(k.name)
hashlib 摘要算法
是一种算法的集合,只要是相同的字符串或者数字,在任何一个机器上,无论什么所得出来的数值是相等的 且摘要过程不可逆
文件一致性校验
md5算法 通用的算法
# sha算法 安全系数更高,sha算法有很多种,后面的数字越大安全系数越高,
# 得到的数字结果越长,计算的时间越长
# 加盐
m = hashlib.md5('wahaha'.encode('utf-8'))
m.update('123456'.encode('utf-8'))
print(m.hexdigest()) # d1c59b7f2928f9b1d63898133294ad2c
# 123456
m = hashlib.md5('wahaha'.encode('utf-8'))
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
# 动态加盐
# 500 用户名 和 密码
# 123456
# 111111 d1c59b7f2928f9b1d63898133294ad2c
# pwd username
username = 'alex'
m = hashlib.md5(username[:2:2].encode('utf-8'))
m.update('123456'.encode('utf-8'))
print(m.hexdigest()) # d1c59b7f2928f9b1d63898133294ad2c
hashlib的另外一个作用 验证文件的一致性 比如下载了英雄联盟,要校验文件的一致性
比如说有一段文字'helloworldthanks'
import hashlib
str = 'helloword33333'
m = hashlib.md5()
m.update(b'helloword')
m.update('33333'.encode('utf-8'))
k = m.hexdigest()
l =hashlib.md5()
l.update(str.encode('utf-8'))
print(l.hexdigest(),k)
####
b8086ba0cb64fc06a4cb3624bdcba171 b8086ba0cb64fc06a4cb3624bdcba171
由上面的代码可以看出,一段相同的内容,不管直接摘要还是分段摘要结果都是一样的。当一个很大的文件进行校验的时候我们就应该分开校验
ef func(filename): with open(filename,'rb') as f: while True: s = f.read(2048) m = hashlib.md5() if s : m.update(s) else:break return m.hexdigest() print(func('hehe'))
configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
创建文件
来看一个好多软件的常见文档格式如下:

[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as configfile:
config.write(configfile)
查找文件
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read('example.ini')
print(config.sections()) # ['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print('bitbucket.org' in config) # True
print(config['bitbucket.org']["user"]) # hg
print(config['DEFAULT']['Compression']) #yes
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org>
for key in config['bitbucket.org']: # 注意,有default会默认default的键
print(key)
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
增删改操作
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('yuan')
config.remove_section('bitbucket.org')
config.remove_option('topsecret.server.com',"forwardx11")
config.set('topsecret.server.com','k1','11111')
config.set('yuan','k2','22222')
config.write(open('new2.ini', "w")) 操作完了之后一定要写入一个新文件
logging日志操作文件
有两种操作模式
第一种:简单模式
logging.basicConfig(level=logging.DEBUG, # format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', # datefmt='%a, %d %b %y %H:%M:%S', # filename = 'userinfo.log' # ) # logging.debug('debug message') # debug 调试模式 级别最低 # logging.info('info message') # info 显示正常信息 # logging.warning('warning message') # warning 显示警告信息 # logging.error('error message') # error 显示错误信息 # logging.critical('critical message') # critical 显示严重错误信息
这种方式存在两种问题,第一是编码问题,在文件输入 会乱码
第二就是不能够同时既在屏幕输出,又在文件输出。
第二种
import logging logger = logging.getLogger() # 实例化了一个logger对象 fh = logging.FileHandler('test.log',encoding='utf-8') # 实例化了一个文件句柄 sh = logging.StreamHandler()#屏幕句柄 fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') 格式化可以写也可以不写 fh.setFormatter(fmt) # 格式和文件句关联 sh.setFormatter(fmt) #格式文件与屏幕句柄关联 sh.setLevel(logging.DEBUG) 设置屏幕打印等级 fh.setLevel(logging.DEBUG) 设置文件打印等级 # 吸星大法 logger.addHandler(fh) # 和logger关联的只有句柄 logger.addHandler(sh) #和logger关联的屏幕句柄 # logger.setLevel(logging.ERROR) 这个可以设置也可以不设置,但是都以等级高的为准 logger.debug('debug message') # debug 调试模式 级别最低 logger.info('info message') # info 显示正常信息 logger.warning('warning message') # warning 显示警告信息 logger.error('小子出错了把') # error 显示错误信息 logger.critical('critical message')
如果都没有设置打印等级则默认从wraning等级开始打印
顺序:1,先实例化一个logger对象
2.实例化文件句柄和屏幕句柄,两者按需求来实例化
3.设置格式化句柄,也是按需求来写
4.若设置了格式化 则需要跟文件句柄 和屏幕句柄关联
5.分别设置打印等级
6,句柄分别和logger关联
7.设置打印等级,可设置也可不设值,这个设置的等级与前面等级相比较按等级高的执行,并且这个设置是对两个句柄都有效
8,使用(logger.debug().......
collection模块 这个模块就是在我们原有的数据类型上又提供了一些新的数据类型
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
nametuple
from collections import namedtuple
# point= namedtuple('point',['x','y'])
# p =point(1,2)
# print(p)
# print(p.x)
deque 可以两边删除 和增加
# from collections import deque
# a = deque()
# a.append(1)
# a.appendleft(0)
# a.appendleft(9)
# a.popleft()
# print(a)
OrderedDict 有序字典
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的顺序返回 ['z', 'y', 'x']
defaultdic 默认字典
l = [11,22,33,44,55,66,77,88,99,90] from collections import defaultdict dic = defaultdict(list) l = [11,22,33,44,55,66,77,88,99,90] for i in l : if i > 66: dic['k1'].append(i) else: dic['k2'].append(i) print(dict(dic))
这种默认字典的特点是永远不会在你使用key去取值的时候报错,即使字典里没有这个key值,也会去创建一个新的键值对,值为空的数据类型 。
time模块
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
now_time = time.time()
now_time_tuple = time.localtime(now_time) #时间戳转为结构化时间
ft = time.strftime('%Y-%m-%d',now_time_tuple) #结构化时间转为为格式化时间
print(ft)
ret = time.strptime('2015-7-30','%Y-%m-%d') #由格式化时间转为结构化时间
a = time.mktime(ret) #由结构化时间转为时间戳
print(ret)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
random
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
练习:生成随机验证码 复制代码 import random def v_code(): code = '' for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) add=random.choice([num,alf]) code="".join([code,str(add)]) return code print(v_code()) 复制代码
面试题:生成一个指定个数的验证码:要求有数字和大小写,且数字和取到大小写字母的概率一致
number= int(input('请输入你要的验证码位数:))
# def id_check(number):
# ret = ''
# for i in range(number):
# num = str(random.randint(0,9))
# alpha_upper = random.randrange(65,90)
# alpha = random.randrange(97,122)
# choice = random.choice([chr(alpha_upper),chr(alpha)])
# a = random.choice([choice,num])
# ret+=a
# return ret
# print(id_check(number))
sys模块
sys模块是与python解释器交互的一个接口

# print(sys.argv) # 列表 列表的第一项是当前文件所在的路径 # if sys.argv[1] == 'alex' and sys.argv[2] == '3714': # print('登陆成功') # else: # sys.exit() # user = input('>>>') # pwd = input('>>>') # if user == 'alex' and pwd == '3714': # print('登陆成功') # else: # sys.exit() # print('我能完成的功能')
在这段代码在cmd中执行的时候 在后面可以加上用户名和密码 这样用户名和密码,这样用户名和密码就成为了sys.argv列表的后两个元素,
所以这种模式下是可以与运用这种方式来直接传值验证,不需要再外面再次验证方便操作。
第二种应用场景
# import logging # print(sys.path) # inp = sys.argv[1] if len(sys.argv)>1 else 'DEBUG' # logging.basicConfig(level=getattr(logging,inp)) # DEBUG # num = int(input('>>>')) # logging.debug(num) # a = num * 100 # logging.debug(a) # b = a - 10 # logging.debug(b) # c = b + 5 # print(c) # 3000
我们做出的项目不是都跑在pycharm里面的,当我们需要在别的环境下我们需要看到代码运行的细节的时候,而不能再pycharm里面dubug的时候就需要用到这种方法。
OS模块
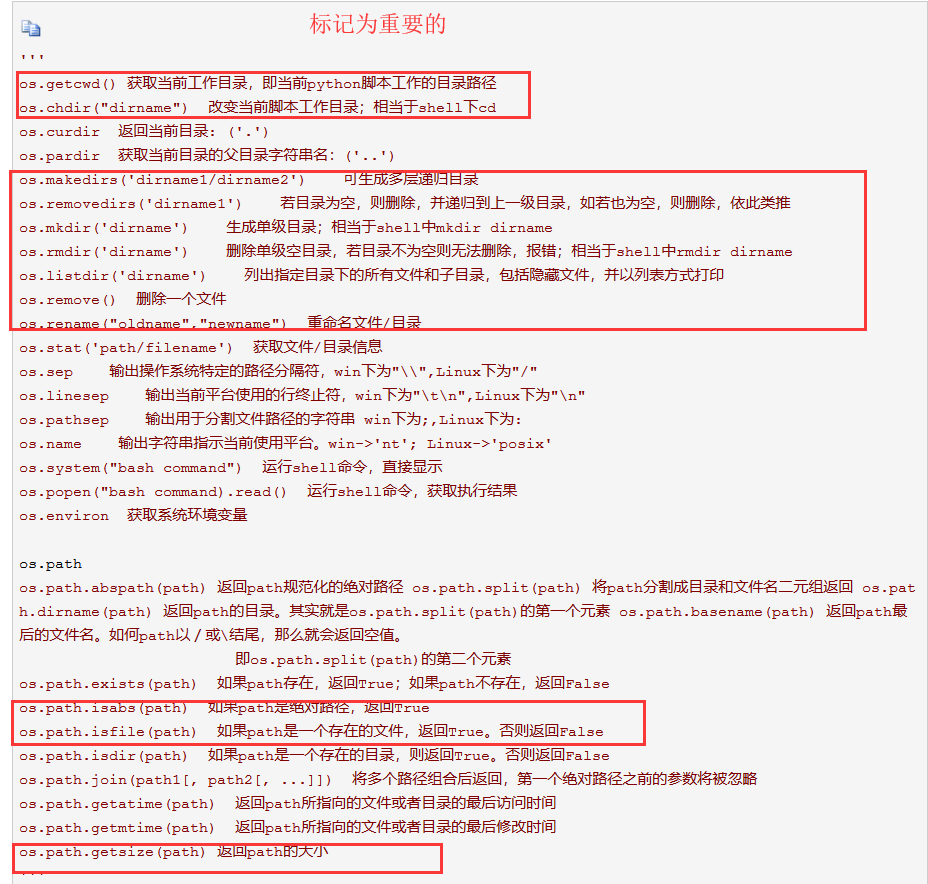
import
import py文件名
引用自定义模块,调用模块里面的方法和变量名字,模块名.方法名() 模块名.变量名
import 模块名 as 变量名
这个重新定义模块的名字
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse')
#test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db
db.sqlparse()
示例用法1
这样重新命名可以只判断一次,不用多次判断。
from 模块名 import 方法名(或者变量名)这种调用方法,只是引用了模块中的变量或者方法。这种引用方式不会再想import那样,执行方法和变量,这样:模块名.方法名()来执行,可以直接引用。但是也会存在覆盖效果。
也有as 用法。




