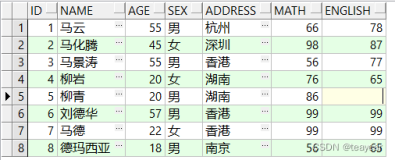
看看开源j2ee 框架bbossgroups 中的dbutil,batchutil 标签来如何实现数据库的 预编译/普通insert , update , delete ,预编译/普通批处理操作 ,比较简单也比较使用。
文章分三部分介绍:
预编译/普通insert , update , delete 操作
执行预编译/普通批处理操作标签
连接池配置
下面分别介绍。
[1] 预编译/普通insert , update , delete 操作
1.1.1 Insert 操作
<%@ page contentType = "text/html; charset=GBK" language = "java" import = "java.sql.*,java.util.List" errorPage = "" %>
1.1.1.1 导入标签定义文件
<%@ taglib uri = "/WEB-INF/pager-taglib.tld" prefix = "pg" %>
<!--
dbutil 标签实现 insert 操作
statement: 数据库 insert 语句
dbname:insert 的相应数据库名称,在 poolman.xml 文件中进行配置
-->
1.1.1.2 定义预编译 sql 语句
<%
String object_id = "1" ;
String owner = "duoduo" ;
String object_name = "table_insert" ;
String created = "2010-03-12 16:52:10" ;
String last_ddl_time = "2010-03-12 16:52:11" ;
String sql = "insert into sqltest(object_id,owner,object_name,created,last_ddl_time) values(#[object_id],#[owner],#[object_name],#[created],#[last_ddl_time])" ;
%>
Sql 语句中的变量 #[object_id],#[owner],#[object_name],#[created],#[last_ddl_time]
的值和类型将在标签 pg:sqlparam 中指定
< html >
< head >
< title > 测试在 dbutil 标签上直接执行数据库插入操作 </ title >
</ head >
< body >
< table >
1.1.1.3 Dbutil 执行预编译插入操作
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = "insert" >
statement 属性指定了先前定义的预编译插入语句
dbname 为数据库连接池的名称
pretoken = "#\\[" endtoken = "\\]" 分别指定了变量的分界符
action=insert 指定了本次执行的是 insert 操作。
1.1.1.4 指定各变量的值和类型
< pg:sqlparam name = "object_id" value = "<%= object_id %> " type = "int" />
< pg:sqlparam name = "owner" value = "<%= owner %> " type = "string" />
< pg:sqlparam name = "object_name" value = "<%= object_name %> " type = "string" />
< pg:sqlparam name = "created" value = "<%= created %> " type = "date" />
< pg:sqlparam name = "last_ddl_time" value = "<%= last_ddl_time %> " type = "timestamp" />
</ pg:dbutil >
<%= dbutil_result %>
Name 属性指定变量的名称,
Value 属性指定变量的值
Type 属性指定变量的类型,如果没有指定那么默认为字符串类型
dbutil_result 存放 insert 操作所插入的记录数
</ table >
</ body >
</ html >
上面说明的是预编译操作,要进行普通插入操作:
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = "insert" >
</ pg:dbutil >
<%= dbutil_result %>
其中的 sql 为一条完成的插入语句即可。例如: insert into table ( name ) values(‘duoduo’) 。
1.1.2 update 操作
<%@ page contentType = "text/html; charset=GBK" language = "java" import = "java.sql.*,java.util.List" errorPage = "" %>
1.1.2.1 导入标签定义文件
<%@ taglib uri = "/WEB-INF/pager-taglib.tld" prefix = "pg" %>
<!--
dbutil 标签实现 update 操作
statement: 数据库 update 语句
dbname:update 的相应数据库名称,在 poolman.xml 文件中进行配置
-->
1.1.2.2 定义预编译 sql 语句
<%
String object_id = "1" ;
String created = "2010-03-12 12:43:54" ;
String sql = "update sqltest set created=#[created] where object_id=#[object_id]" ;
%>
Sql 语句中的变量 #[created], #[object_id] 的值和类型将在标签 pg:sqlparam 中指定
< html >
< head >
< title > 测试在 dbutil 标签上直接执行数据库 update 操作 </ title >
</ head >
< body >
< table >
1.1.2.3 Dbutil 执行预编译修改操作
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = "update" >
statement 属性指定了先前定义的预编译 update 语句
dbname 为数据库连接池的名称
pretoken = "#\\[" endtoken = "\\]" 分别指定了变量的分界符
action=update 指定了本次执行的是 update 操作。
1.1.2.4 指定各变量的值和类型
< pg:sqlparam name = "object_id" value = "<%= object_id %> " type = "int" />
< pg:sqlparam name = "created" value = "<%= created %> " type = "timestamp" />
</ pg:dbutil >
<%= dbutil_result %>
Name 属性指定变量的名称,
Value 属性指定变量的值
Type 属性指定变量的类型,如果没有指定那么默认为字符串类型
dbutil_result 存放 update 操作所修改的记录数
</ table >
</ body >
</ html >
上面说明的是预编译操作,要进行普通 update 操作:
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = "update" >
</ pg:dbutil >
<%= dbutil_result %>
其中的 sql 为一条完整的 update 语句即可。例如: update table set name=‘duoduo’ 。
1.1.3 Delete 操作
<%@ page contentType = "text/html; charset=GBK" language = "java" import = "java.sql.*,java.util.List" errorPage = "" %>
1.1.3.1 导入标签定义文件
<%@ taglib uri = "/WEB-INF/pager-taglib.tld" prefix = "pg" %>
<!--
dbutil 标签实现 delete 操作
statement: 数据库查询语句
dbname: delete 的相应数据库名称,在 poolman.xml 文件中进行配置
-->
1.1.3.2 定义预编译 sql 语句
<%
String object_id = "15" ;
String sql = "delete from sqltest where object_id=#[object_id] " ;
%>
Sql 语句中的变量 #[object_id] 的值和类型将在标签 pg:sqlparam 中指定
< html >
< head >
< title > 测试在 dbutil 标签上直接执行数据库 delete 操作 </ title >
</ head >
< body >
< table >
1.1.3.3 Dbutil 执行预编译 delete 操作
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = " delete" >
statement 属性指定了先前定义的预编译 delete 语句
dbname 为数据库连接池的名称
pretoken = "#\\[" endtoken = "\\]" 分别指定了变量的分界符
action= delete 指定了本次执行的是 delete 操作。
1.1.3.4 指定各变量的值和类型
< pg:sqlparam name = "object_id" value = "<%= object_id %> " type = "int" />
</ pg:dbutil >
<%= dbutil_result %>
Name 属性指定变量的名称,
Value 属性指定变量的值
Type 属性指定变量的类型,如果没有指定那么默认为字符串类型
dbutil_result 存放 delete 操作所删除记录数
</ table >
</ body >
</ html >
上面说明的是预编译操作,要进行普通 delete 操作:
< pg:dbutil statement = "<%= sql %> "
dbname = "bspf"
pretoken = "#\\[" endtoken = "\\]"
action = " delete" >
</ pg:dbutil >
<%= dbutil_result %>
其中的 sql 为一条完整的 delete 语句即可。例如: delete frome table where name=‘duoduo’ 。
[2]执行预编译/普通批处理操作标签
相关的一组标签:batchutil,statement,batch,sqlparam
通过这组标签我们可以实现以下功能:
普通批处理操作
预编译批处理操作
下面详细说明上述功能。
1.1.1 普通批处理操作
<%@ page contentType="text/html; charset=GBK" language="java"%>
1.1.1.1 导入标签定义文件
<%@ taglib uri="/WEB-INF/pager-taglib.tld" prefix="pg"%>
<!--
batchutil标签实现数据库批处理操作
statement:指定批处理语句
dbname:批处理语句执行的对应的数据库连接池名称,在poolman.xml文件中进行配置
-->
1.1.1.2 定义一组要进行批处理操作的sql语句
<% String sql = "update sqltest set batch='1' where object_id=1";
String sql1 = "update sqltest set batch='2' where object_id=1";
String sql2 = "update sqltest set batch='3' where object_id=1";
String sql3 = "update sqltest set batch='4' where object_id=1";
String sql4 = "update sqltest set batch='5' where object_id=1";
%>
<html>
<head>
<title>测试在batchutil标签上直接执行数据库批处理操作</title>
</head>
<body>
<table>
1.1.1.3 使用batchutil标签执行批处理操作
<pg:batchutil dbname="bspf" type="common">
<pg:statement sql="<%=sql %>" />
<pg:statement sql="<%=sql1 %>" />
<pg:statement sql="<%=sql2 %>" />
<pg:statement sql="<%=sql3 %>" />
<pg:statement sql="<%=sql4 %>" />
</pg:batchutil>
</table>
</body>
</html>
1.1.2 预编译批处理操作
<%@ page contentType="text/html; charset=GBK" language="java"%>
1.1.2.1 导入标签定义文件
<%@ taglib uri="/WEB-INF/pager-taglib.tld" prefix="pg"%>
<!--
batchutil标签实现数据库预编译批处理操作
statement:指定预编译批处理语句
dbname:预编译批处理语句执行的对应的数据库连接池名称,在poolman.xml文件中进行配置
-->
1.1.2.2 定义一组要进行预编译批处理操作的sql语句和参数组
预编译批处理操作可以是多条不同的预编译sql语句,也可以是同一条sql语句的多个不同的绑定变量参数组,也可以是混合的情况。下面我们使用一条sql语句和5组不同的绑定参数的情况做为示例来说明各种不同的情况。
<%
String object_id = "1";
String created = "2010-03-12 12:43:54";
String created1 = "2010-03-13 12:43:54";
String created2 = "2010-03-14 12:43:54";
String created3 = "2010-03-15 12:43:54";
String created4 = "2010-03-16 12:43:54";
String sql = "update sqltest set created=#[created] where object_id=#[object_id]";
%>
<html>
<head>
<title>测试在batchutil标签上直接执行数据库预编译批处理操作</title>
</head>
<body>
<table>
1.1.2.3 使用batchutil标签执行预编译批处理操作
<pg:batchutil dbname="bspf" type="prepared">
<pg:statement sql="<%=sql %>" pretoken="#\\[" endtoken="\\]">
1.1.2.3.1 多组不同的参数用batch标签来组织
<pg:batch>
<pg:sqlparam name="object_id" value="<%=object_id %>" type="int" />
<pg:sqlparam name="created" value="<%=created %>" type="timestamp" />
</pg:batch>
</pg:statement>
<pg:statement sql="<%=sql %>" pretoken="#\\[" endtoken="\\]">
<pg:batch>
<pg:sqlparam name="object_id" value="<%=object_id %>" type="int" />
<pg:sqlparam name="created" value="<%=created1 %>"
type="timestamp" />
</pg:batch>
</pg:statement>
<pg:statement sql="<%=sql %>" pretoken="#\\[" endtoken="\\]">
1.1.2.3.2 如果只有一组参数,那么不需要使用batch标签
<pg:sqlparam name="object_id" value="<%=object_id %>" type="int" />
<pg:sqlparam name="created" value="<%=created2 %>" type="timestamp" />
</pg:statement>
<pg:statement sql="<%=sql %>" pretoken="#\\[" endtoken="\\]">
<pg:batch>
<pg:sqlparam name="object_id" value="<%=object_id %>" type="int" />
<pg:sqlparam name="created" value="<%=created3 %>"
type="timestamp" />
</pg:batch>
<pg:batch>
<pg:sqlparam name="object_id" value="<%=object_id %>" type="int" />
<pg:sqlparam name="created" value="<%=created4 %>"
type="timestamp" />
</pg:batch>
</pg:statement>
</pg:batchutil>
</table>
</body>
</html>
如果要引入事务的话,可以在执行sql的标签代码的外围包一个事务即可使用的方法如下:
import com.frameworkset.orm.transaction.TransactionManager;
<%
TransactionManager tm = new TransactionManager();
try
{
tm.begin();//开始事务
%>
放置操作数据库的标签代码
<%
tm.commit();//提交事务
}
catch(Exception e)
{
try {
tm.rollback();//回滚事务
} catch (Exception e1) {
e1.printStackTrace();
}
}
%>
[3]连接池配置
概述
bboss persistent的配置文件为poolman.xml,位于classes目录下即可
1.bboss persistent框架支持多个数据源配置
2.bboss persistent框架默认采用apache common dbcp作为数据库连接池
3.bboss persistent框架可以引用外部数据源,例如tomcat,weblogic和WebSphere平台提供的datasource
基本配置实例,只配置了一个datasource,如果需要配置多个datasource,只需要按照相应格式再加数据源就可以了:
<?xml version="1.0" encoding="gb2312"?>
<poolman>
<datasource>
<!--
连接池的逻辑名称,
应用程序通过该名称获取对应的数据库连接池的链接
持久层接口通过指定该名称在相应的数据库上执行增删改查操作
import java.sql.Connection;
import java.sql.SQLException;
import com.frameworkset.common.poolman.DBUtil;
.....
Connection con = DBUtil.getConection(“bspf”);
-->
<dbname>bspf</dbname>
<!--
数据库链接池启动时是否加载数据库表和视图的元数据 ,应用程序可以调用以下接口获取这些数据:
import com.frameworkset.common.poolman.DBUtil;
import com.frameworkset.common.poolman.sql.TableMetaData;
TableMetaData tableMetaData = DBUtil.getTableMetaData("V_VCH_FIXED_TAX_CF");
System.out.println(DBUtil.getTableMetaData("V_VCH_FIXED_TAX_CF"));
-->
<loadmetadata>false</loadmetadata>
<!--
datasource的jndi查找名称,如果指定了jndiName参数
bboss persistent框架将链接池绑定为datasource,应用程序可以通过
jndi查找获取数据库链接,例如:
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("bspf_datasource_jndiname");
-->
<jndiName>bspf_datasource_jndiname</jndiName>
<!--
autoprimarykey
true表示启用insert自动补全功能,如果在insert sql语句中没有指定主键字段,那么bboss persistent将自动补全该条语句
首先分析sql语句得到table name,然后根据该表名到tableinfo表中查找表的主键信息,找到后根据主键配置生成一个主键,补全到sql语句中
当执行插入操作的方法时,该主键将作为方法的返回值返回给调用程序。
false表示不自动生成,默认值,这样避免分析sql语句,提高系统性能。
-->
<autoprimarykey>false</autoprimarykey>
<!--
cachequerymetadata 是否缓冲查询语句中查询列表中的字段信息
true表示缓冲,提高系统新能,一旦系统内存不够时,将自动释放这些缓冲
false,表示不缓冲
-->
<cachequerymetadata>false</cachequerymetadata>
<!--
driver 指定数据库驱动程序
-->
<driver>oracle.jdbc.driver.OracleDriver</driver>
<!--
url 指定数据库连接串
-->
<url>jdbc:oracle:thin:@//localhost:1521/orcl</url>
<!--
username 指定数据库用户
-->
<username>cmsnew</username>
<!--
password 指定数据库用户口令
-->
<password>cmsnew</password>
<!--
txIsolationLevel 指定数据库事务隔离级别
-->
<txIsolationLevel>READ_COMMITTED</txIsolationLevel>
<!--
initialConnections 指定数据库连接池初始连接数
-->
<initialConnections>2</initialConnections>
<!--
minimumSize 指定数据库连接池最小连接数
-->
<minimumSize>2</minimumSize>
<!--
maximumSize 指定数据库连接池最大连接数
-->
<maximumSize>8</maximumSize>
<!--控制connection达到maximumSize是否允许再创建新的connection
true:允许,缺省值
false:不允许-->
<maximumSoft>false</maximumSoft>
<!--
是否检测超时链接(事务超时链接),当数据库连接资源不够时,才会检测,否则不检测
true-检测,如果检测到有事务超时的链接,系统将强制回收(释放)该链接
false-不检测,默认值
-->
<removeAbandoned>true</removeAbandoned>
<!--
链接使用超时时间(事务超时时间)
单位:秒
-->
<userTimeout>120</userTimeout>
<!--
系统强制回收链接时,是否输出后台日志
true-输出,默认值
false-不输出
-->
<logAbandoned>true</logAbandoned>
<!--
数据库会话是否是readonly,缺省为false
-->
<readOnly>true</readOnly>
<!--
对应属性:timeBetweenEvictionRunsMillis
the amount of time (in seconds) to sleep between examining idle objects for eviction
空闲链接超时检测处理启动间隔时间
单位:秒
-->
<skimmerFrequency>86400</skimmerFrequency>
<!--对应于minEvictableIdleTimeMillis 属性:
minEvictableIdleTimeMillis the minimum number of milliseconds
an object can sit idle in the pool before it is eligable for evcition
单位:秒
空闲链接回收时间,空闲时间超过指定的值时,将被回收
-->
<connectionTimeout>120</connectionTimeout>
<!--
numTestsPerEvictionRun
the number of idle objects to
examine per run within the idle object eviction thread (if any)
每次检测时,检测的空闲链接个数 ,为零时检测所有的空闲链接
-->
<shrinkBy>4</shrinkBy>
<!--
/**
* 检测空闲链接处理时,是否对空闲链接进行有效性检查控制开关
* true-检查,都检查到有无效链接时,直接销毁无效链接
* false-不检查,缺省值
*/
-->
<testWhileidle>false</testWhileidle>
<!--
(1) 在tableinfo表中配置了sequence时,以下机制不起作用,
定义数据库主键生成机制
缺省的采用系统自带的主键生成机制,
外步程序可以覆盖系统主键生成机制
由值来决定
auto:自动,一般在生产环境下采用该种模式,
解决了单个应用并发访问数据库添加记录产生冲突的问题,效率高,如果生产环境下有多个应用并发访问同一数据库时,必须采用composite模式
composite:结合自动和实时从数据库中获取最大的主键值两种方式来处理,开发环境下建议采用该种模式,
解决了多个应用同时访问数据库添加记录时产生冲突的问题,效率相对较低, 如果生产环境下有多个应用并发访问同一数据库时,必须采用composite模式
(2)通过以下方法获取主键
DBUtil中的下述方法获取主键
DBUtil.getNextPrimaryKey(Connection, tablename)
DBUtil.getNextPrimaryKey(Connection, dbname, tablename)
DBUtil.getNextPrimaryKey(tablename)
DBUtil.getNextPrimaryKey(dbname, tablename)
DBUtil.getNextStringPrimaryKey(Connection, tablename)
DBUtil.getNextStringPrimaryKey(Connection, dbname, tablename)
DBUtil.getNextStringPrimaryKey(tablename)
DBUtil.getNextStringPrimaryKey(dbname, tablename)
前提是tablename对应的表的主键信息必须配置在tableinfo表中,tableinfo表的结构为:
名称 是否为空? 类型 描述
----------------------------------------- -------- ----------------------------
TABLE_NAME NOT NULL VARCHAR2(255) 表名称
TABLE_ID_NAME VARCHAR2(255) 表的主键名称
TABLE_ID_INCREMENT NUMBER(5) 表主键的自增值
TABLE_ID_VALUE NUMBER(20) 表主键当前值,已经不使用
TABLE_ID_GENERATOR VARCHAR2(255) 表主键生成机制,只有TABLE_ID_TYPE为sequence时才需填为相应sequence的名称
TABLE_ID_TYPE VARCHAR2(255) 表主键的数值类型,int,long,string,sequence,如果为sequence时必须指定TABLE_ID_GENERATOR为对应的sequence的名称
TABLE_ID_PREFIX VARCHAR2(255) 为表主键添加统一的前缀,默认为null,只有表主键类型为string时才能指定前缀。
-->
<keygenerate>composite</keygenerate>
<!-- 请求链接时等待时间,单位:秒
客服端程序请求链接等待时间,超过指定值时后台包报待超时异常
-->
<maxWait>10</maxWait>
<!--
链接有效性检查sql语句
-->
<validationQuery>select 1 from dual</validationQuery>
<!-- 如果在tableinfo表中配置了表的主键信息,而且主键通过sequence生成,则synsequence元素
用来控制是否同步sequence的当前值为最大的未使用的表的主键值+1。
-->
<synsequence>false</synsequence>
<!-- 每个connection预编译statement池化标记
true:池化
false:不池化,默认值
-->
<poolingPreparedStatements>false</poolingPreparedStatements>
<!--
每个connection最大打开的预编译statements数-1
-->
<maxOpenPreparedStatements>-1</maxOpenPreparedStatements>
<!--
设置为true,则相关的增删改查,批处理,预编译处理,存储函数调用sql语句将全部被输出的系统后台
否则不输出
-->
<showsql>true</showsql>
</datasource>
</poolman>
外部数据源实例
<?xml version="1.0" encoding="gb2312"?>
<poolman>
<datasource external=“true”>
<!--
连接池的逻辑名称,
应用程序通过该名称获取对应的数据库连接池的链接
持久层接口通过指定该名称在相应的数据库上执行增删改查操作
import java.sql.Connection;
import java.sql.SQLException;
import com.frameworkset.common.poolman.DBUtil;
.....
Connection con = DBUtil.getConection(“bspf”);
-->
<dbname>bspf</dbname>
<!--
数据库链接池启动时是否加载数据库表和视图的元数据 ,应用程序可以调用以下接口获取这些数据:
import com.frameworkset.common.poolman.DBUtil;
import com.frameworkset.common.poolman.sql.TableMetaData;
...
TableMetaData tableMetaData = DBUtil.getTableMetaData("V_VCH_FIXED_TAX_CF");
System.out.println(DBUtil.getTableMetaData("V_VCH_FIXED_TAX_CF"));
-->
<loadmetadata>false</loadmetadata>
<!--
datasource的jndi查找名称,如果指定了jndiName参数
bboss persistent框架将链接池绑定为datasource,应用程序可以通过
jndi查找获取数据库链接,例如:
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("bspf_datasource_jndiname");
-->
<jndiName>bspf_datasource_jndiname</jndiName>
<!--
当dataSource的external属性指定为true时,必须指定外部数据源jndi绑定名称
如果系统需要通过内部的jndi查找该数据源,还必须指定jndiName名称,比如系统管理中hibernate
必需通过内部jndi访问数据源来获取数据库的链接,以及应用hibernate产生自定义数据库主键机制
-->
<externaljndiName>external_bspf_datasource_jndiname</externaljndiName>
<!--
autoprimarykey
true表示启用insert自动补全功能,如果在insert sql语句中没有指定主键字段,那么bboss persistent将自动补全该条语句
首先分析sql语句得到table name,然后根据该表名到tableinfo表中查找表的主键信息,找到后根据主键配置生成一个主键,补全到sql语句中
当执行插入操作的方法时,该主键将作为方法的返回值返回给调用程序。
false表示不自动生成,默认值,这样避免分析sql语句,提高系统性能。
-->
<autoprimarykey>false</autoprimarykey>
<!--
cachequerymetadata 是否缓冲查询语句中查询列表中的字段信息
true表示缓冲,提高系统新能,一旦系统内存不够时,将自动释放这些缓冲
false,表示不缓冲
-->
<cachequerymetadata>false</cachequerymetadata>
<!--
driver 指定数据库驱动程序,外部数据源需要指定数据库的驱动程序是为了识别不同类型的数据库
-->
<driver>oracle.jdbc.driver.OracleDriver</driver>
<!--
(1) 在tableinfo表中配置了sequence时,以下机制不起作用,
定义数据库主键生成机制
缺省的采用系统自带的主键生成机制,
外步程序可以覆盖系统主键生成机制
由值来决定
auto:自动,一般在生产环境下采用该种模式,
解决了单个应用并发访问数据库添加记录产生冲突的问题,效率高,如果生产环境下有多个应用并发访问同一数据库时,必须采用composite模式
composite:结合自动和实时从数据库中获取最大的主键值两种方式来处理,开发环境下建议采用该种模式,
解决了多个应用同时访问数据库添加记录时产生冲突的问题,效率相对较低, 如果生产环境下有多个应用并发访问同一数据库时,必须采用composite模式
(2)通过以下方法获取主键
DBUtil中的下述方法获取主键
DBUtil.getNextPrimaryKey(Connection, tablename)
DBUtil.getNextPrimaryKey(Connection, dbname, tablename)
DBUtil.getNextPrimaryKey(tablename)
DBUtil.getNextPrimaryKey(dbname, tablename)
DBUtil.getNextStringPrimaryKey(Connection, tablename)
DBUtil.getNextStringPrimaryKey(Connection, dbname, tablename)
DBUtil.getNextStringPrimaryKey(tablename)
DBUtil.getNextStringPrimaryKey(dbname, tablename)
前提是tablename对应的表的主键信息必须配置在tableinfo表中,tableinfo表的结构为:
名称 是否为空? 类型 描述
----------------------------------------- -------- ----------------------------
TABLE_NAME NOT NULL VARCHAR2(255) 表名称
TABLE_ID_NAME VARCHAR2(255) 表的主键名称
TABLE_ID_INCREMENT NUMBER(5) 表主键的自增值
TABLE_ID_VALUE NUMBER(20) 表主键当前值,已经不使用
TABLE_ID_GENERATOR VARCHAR2(255) 表主键生成机制,只有TABLE_ID_TYPE为sequence时才需填为相应sequence的名称
TABLE_ID_TYPE VARCHAR2(255) 表主键的数值类型,int,long,string,sequence,如果为sequence时必须指定TABLE_ID_GENERATOR为对应的sequence的名称
TABLE_ID_PREFIX VARCHAR2(255) 为表主键添加统一的前缀,默认为null,只有表主键类型为string时才能指定前缀。
-->
<keygenerate>composite</keygenerate>
<!-- 如果在tableinfo表中配置了表的主键信息,而且主键通过sequence生成,则synsequence元素
用来控制是否同步sequence的当前值为最大的未使用的表的主键值+1。
-->
<synsequence>false</synsequence>
<!--
设置为true,则相关的增删改查,批处理,预编译处理,存储函数调用sql语句将全部被输出的系统后台
否则不输出
-->
<showsql>true</showsql>
</datasource>
</poolman>