简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github也都采用它做的搜索。
更多Elasticsearch的相关知识,请阅读官网《Elasticsearch: 权威指南》。

下面我们重点讲Head插件。
Elasticsearch head是一个用浏览器跟ES集群交互的插件,可以查看集群状态、集群的doc内容、执行搜索和普通的Rest请求等。GitHub地址。
1. ES 5.0+ 版本Head插件安装
ES 5.X 和之前的版本不太一样,elasticsearch-head 做为一个单独的服务,所以就没有了 plugin install,网上大部分文章也都是使用的plugin install安装方式。
1.1 安装NodeJS
使用yum安装
[root@node1 ~]# yum install -y nodejs或者自己下载tar文件解压
wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.5.0-linux-x64.tar.gz
tar -zxvf node-v4.5.0-linux-x64.tar.gz配置下环境变量,编辑/etc/profile添加
export NODE_HOME=/usr/local/node-v4.5.0-linux-x64
export PATH=$PATH:$NODE_HOME/bin/
export NODE_PATH=$NODE_HOME/lib/node_modules执行 source /etc/profile
1.2 安装npm
[root@node1 ~]# npm install -g cnpm --registry=https://registry.npm.taobao.org
1.3 安装grunt
[root@node1 ~]# npm install -g grunt
[root@node1 ~]# npm install -g grunt-cli --registry=https://registry.npm.taobao.org --no-proxy
最后确认检查:
[es@node1 ~]$ node -v
v6.12.0
[es@node1 ~]$ npm -v
3.10.10
[es@node1 ~]$ grunt -version
grunt-cli v1.2.01.4 下载head插件源码
可以下载zip包或者使用git,这里使用git方式
[es@node1 ~]$ git clone git@github.com:mobz/elasticsearch-head.git1.5 安装Head插件
[es@node1 ~]$ npm install- 此处可能会报错,
npm install Err,PhantomJS not found on PATH",可尝试使用taobao镜像安装
[es@node1 elasticsearch-head-master]$ npm install -g cnpm --registry=https://registry.npm.taobao.org2. 配置
2.1 停止ES
如果ElasticSearch已经启动,需要先停止
[es@node1 ~]$ jps
3261 Elasticsearch
3375 Jps
[es@node1 ~]$ kill 32612.2 配置 ElasticSearch,使得HTTP对外提供服务
[es@node1 elasticsearch-6.1.1]$ vi config/elasticsearch.yml
添加如下内容:
# 增加新的参数,这样head插件可以访问es。设置参数的时候:
http.cors.enabled: true
http.cors.allow-origin: "*"注意:后面要有空格
2.3 修改Head plugin 配置文件
[es@node1 elasticsearch-head-master]$ vi Gruntfile.js
找到connect:server,添加hostname一项,如下
connect: {
server: {
options: {
hostname: ':*.*.*.*:',
port: 9100,
base: '.',
keepalive: true
}
}
}3. 启动
3.1 确认es已经启动
[es@node1 elasticsearch-6.1.1]$ bin/elasticsearch -d
[es@node1 elasticsearch-6.1.1]$ jps
3451 Jps
3436 Elasticsearch3.2 启动head
(1) 使用grunt启动
[es@node1 elasticsearch-head-master]$ grunt server
# 需要在head的目录下运行
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://:*.*.*.*:9100(2) 使用npm启动
[es@node1 elasticsearch-head-master]$ npm run start
> elasticsearch-head@0.0.0 start /home/es/elasticsearch-head-master
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://:*.*.*.*:91004. 访问
访问地址 http://:*.*.*.*:9100/

显示集群未连接,修改地址为刚刚配置的地址:...:9200
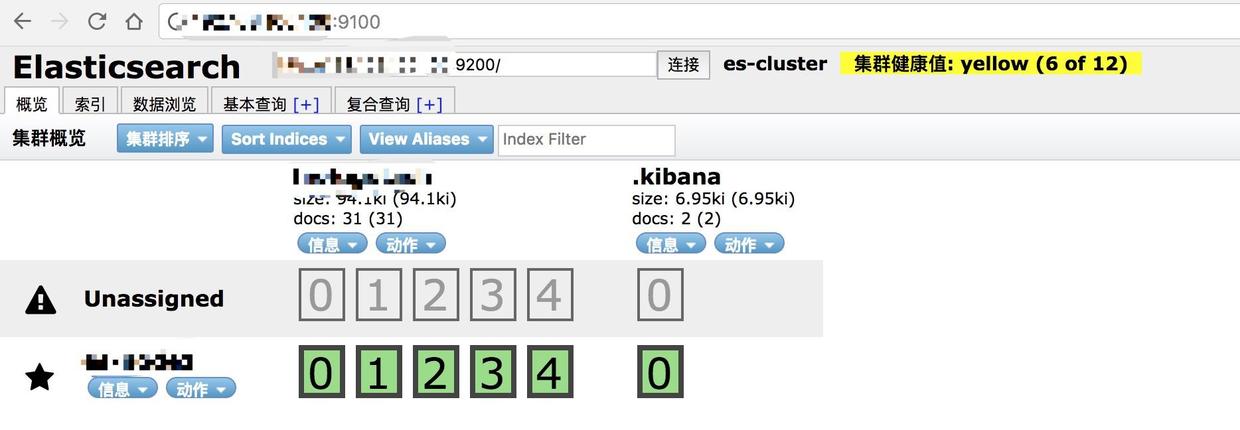
以上内容中
*.*.*.*均为自己的ip地址
5. 安全问题(严重)
因为该插件可以对数据进行,增删改查。故生产环境尽量不要使用,如果要使用,最少要限制IP地址。尽量不要使用。
6. 小结
本文主要介绍了ElasticSearch Head的安装和配置,过程中主要遇到几个坑:
(1)PhantomJS not found on PATH 错误
拉下来head插件的源码进行npm install时会报错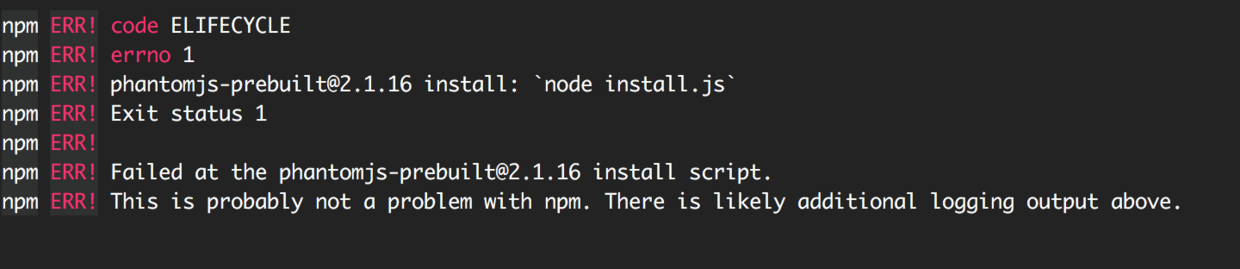
错误日志往上看会看到类似日志:
PhantomJS not found on PATH
Download already available at /tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2
Verified checksum of previously downloaded file
Extracting tar contents (via spawned process)实际是PhantomJS未安装成功引起,使用cnpm通过淘宝镜像安装成功。
(2)配置文件格式
Gruntfile.js和elasticsearch.yml配置文件注意格式,格式错误也会导致错误。Gruntfile.js注意,,elasticsearch.yml注意空格。
