Python小爬虫
2017-09-22
873
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
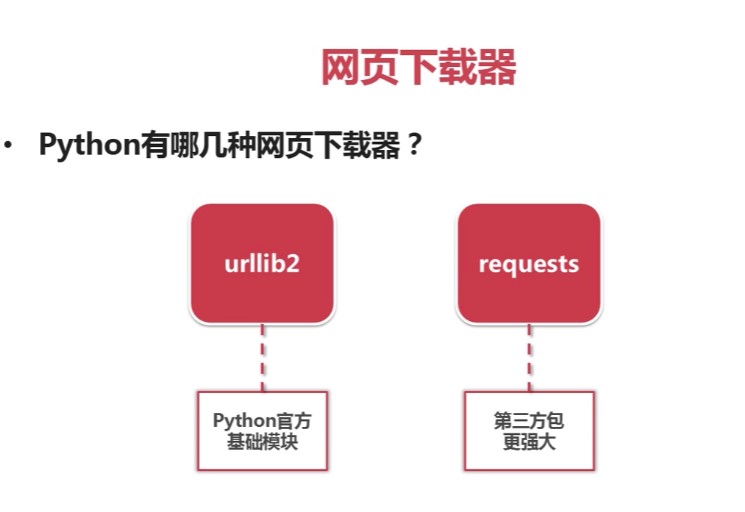
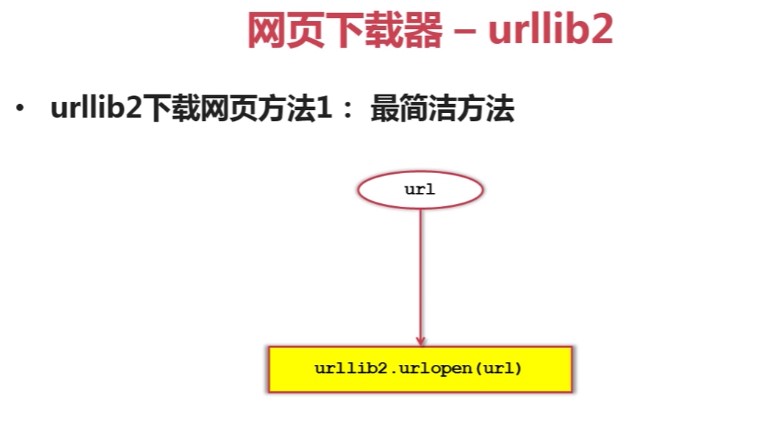
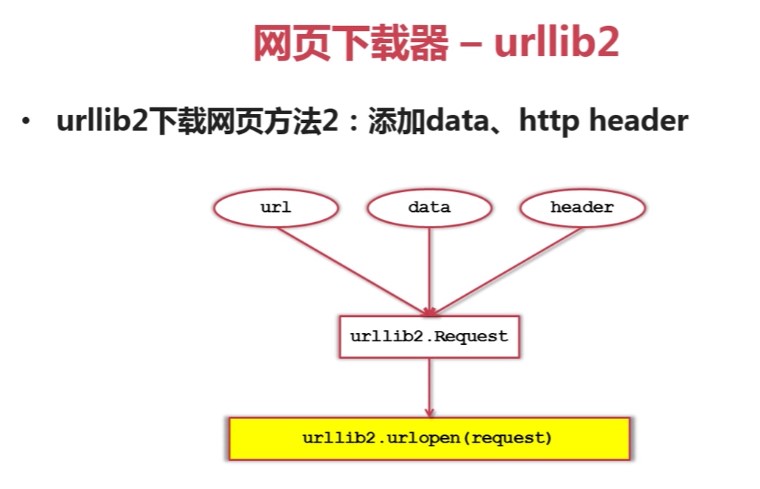
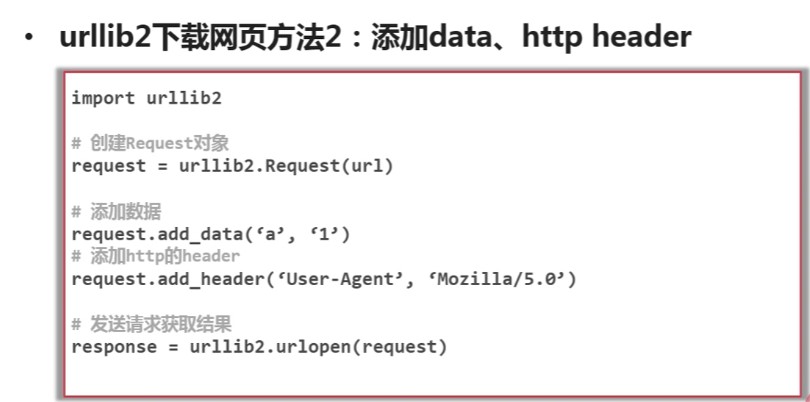
网页解析器下载网址:http://www.crummy.com/software/BeautifulSoup/ ...
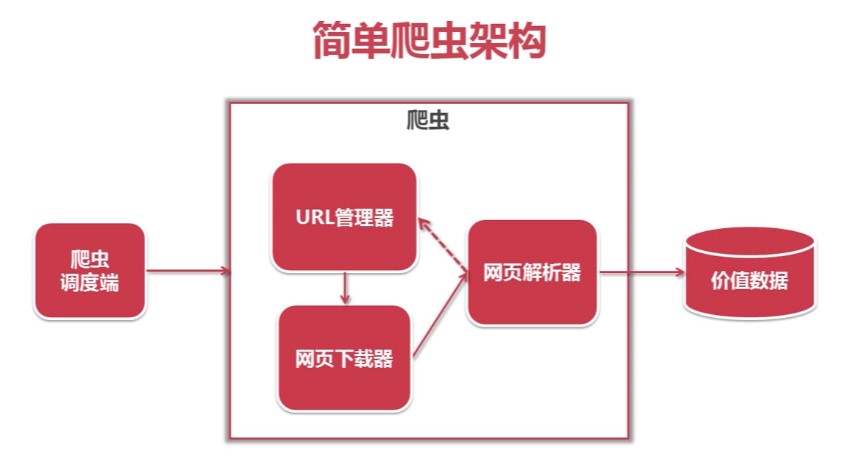
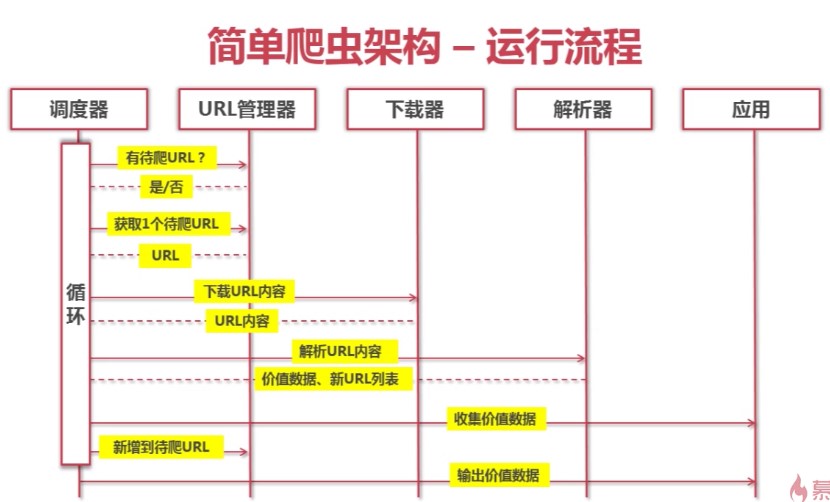
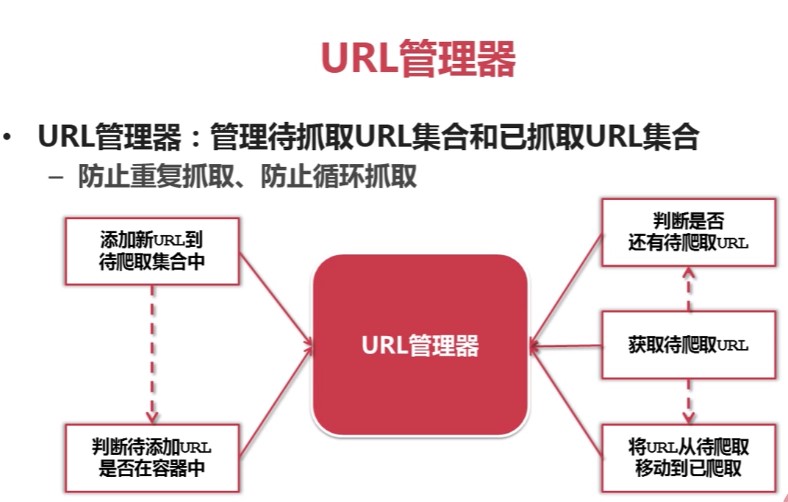
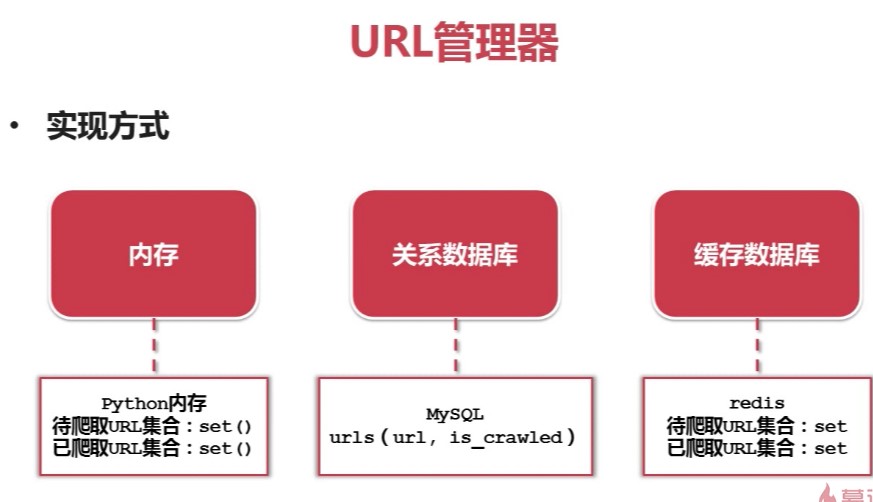

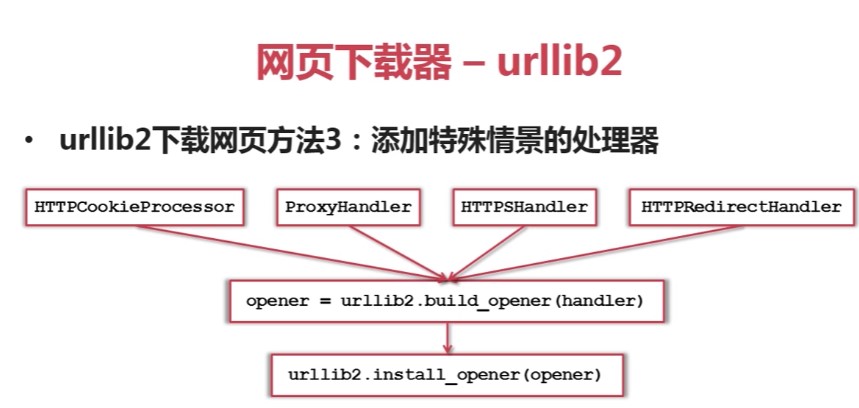
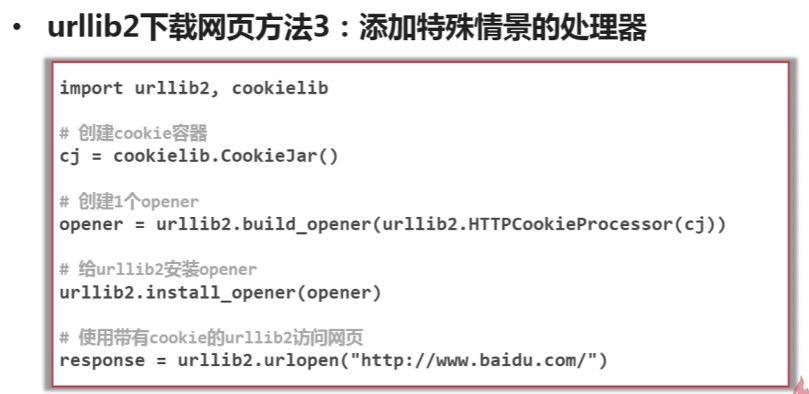
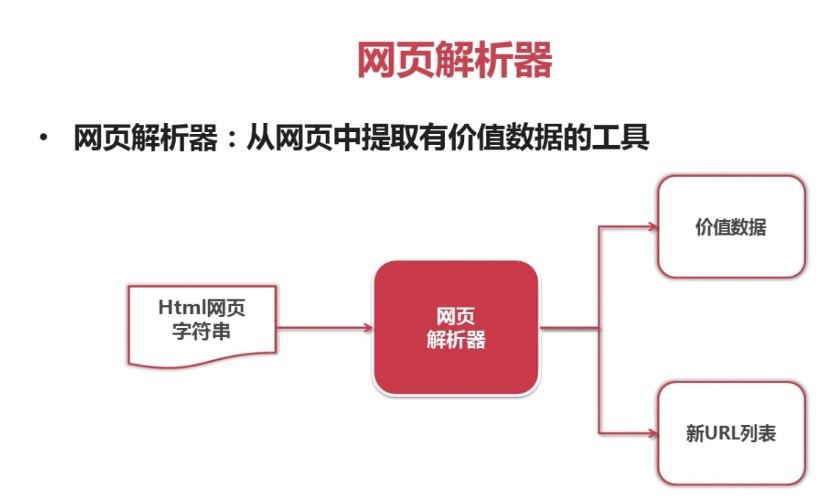
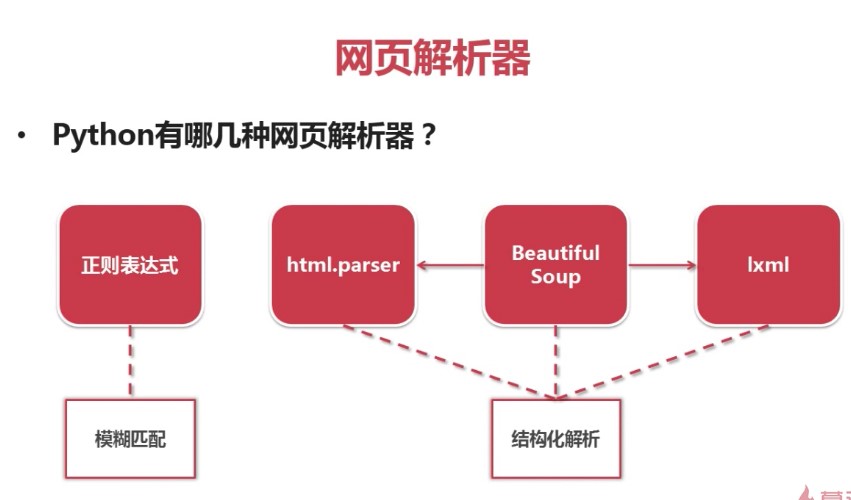
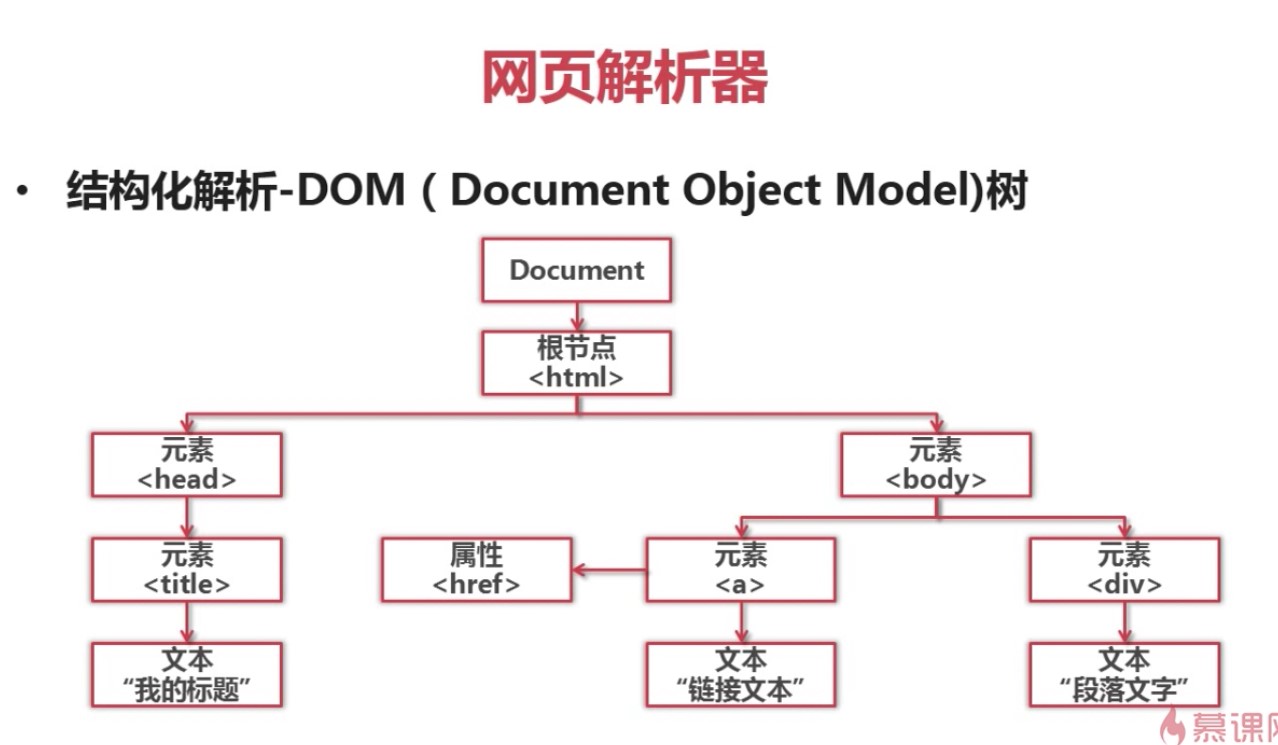
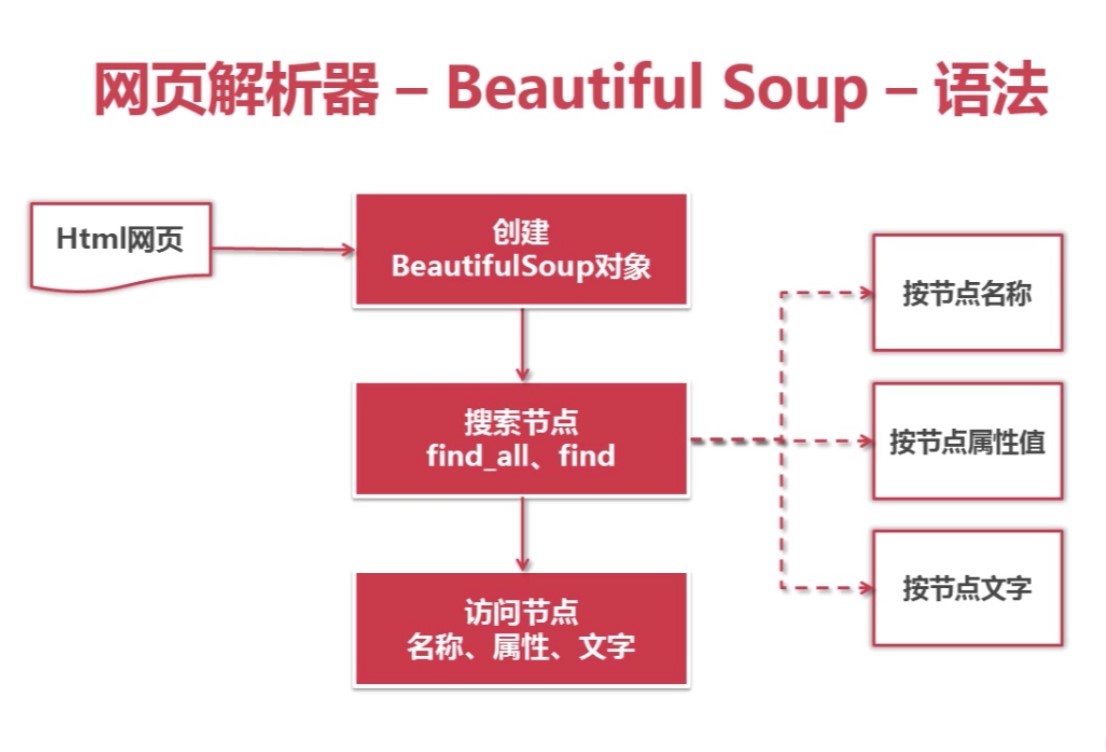
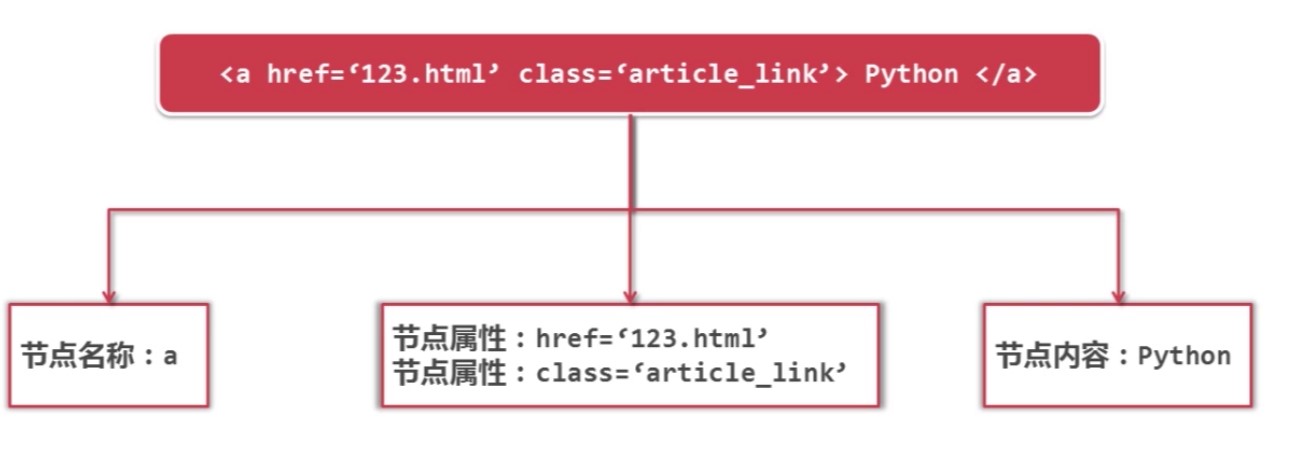

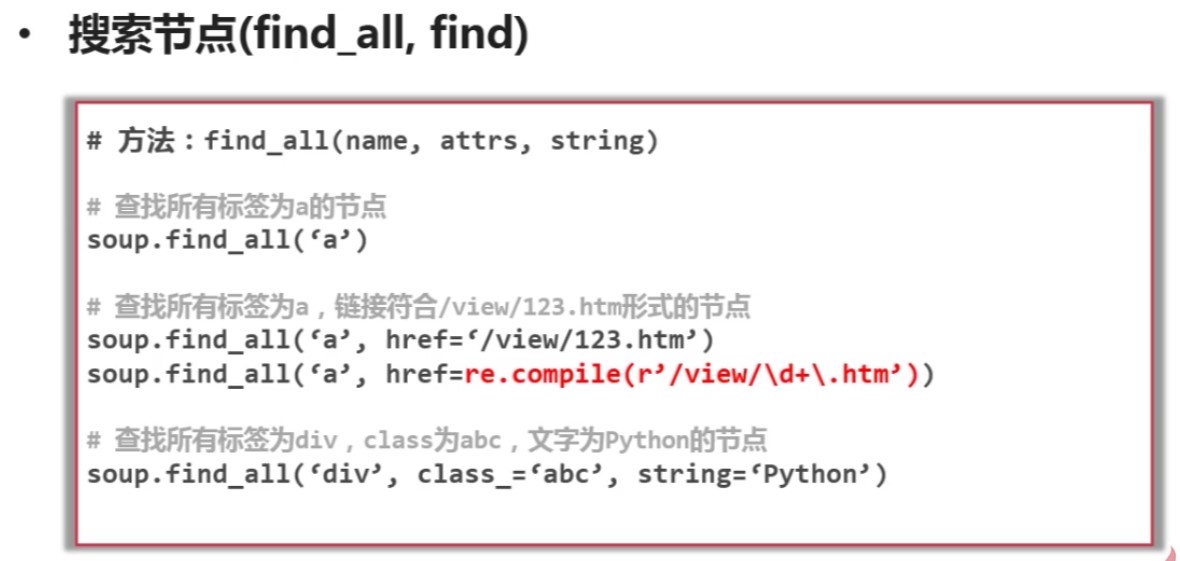


目录
相关文章
|
9天前
|
数据采集
XML
数据处理
使用Python实现简单的Web爬虫
本文将介绍如何使用Python编写一个简单的Web爬虫,用于抓取网页内容并进行简单的数据处理。通过学习本文,读者将了解Web爬虫的基本原理和Python爬虫库的使用方法。
37
13
13
|
26天前
|
数据采集
数据挖掘
Python
使用Python构建简单的Web爬虫:实现网页内容抓取与分析
本文将介绍如何使用Python编写一个简单的Web爬虫,实现对特定网页内容的抓取与分析。通过学习本文,读者将了解到如何利用Python的requests和Beautiful Soup库来获取网页内容,并通过示例演示如何解析HTML结构,提取所需信息。此外,我们还将讨论一些常见的爬虫挑战以及如何避免被网站封禁的策略。
16
1
1
|
27天前
|
数据采集
Python

|
1月前
|
数据采集
Web App开发
数据挖掘
|
6天前
|
数据采集
Web App开发
数据可视化
|
7天前
|
数据采集
存储
大数据
Python爬虫:数据获取与解析的艺术
本文介绍了Python爬虫在大数据时代的作用,重点讲解了Python爬虫基础、常用库及实战案例。Python因其简洁语法和丰富库支持成为爬虫开发的优选语言。文中提到了requests(发送HTTP请求)、BeautifulSoup(解析HTML)、Scrapy(爬虫框架)、Selenium(处理动态网页)和pandas(数据处理分析)等关键库。实战案例展示了如何爬取电商网站的商品信息,包括确定目标、发送请求、解析内容、存储数据、遍历多页及数据处理。最后,文章强调了遵守网站规则和尊重隐私的重要性。
18
2
2
|
11天前
|
数据采集
定位技术
Python
Python爬虫IP代理技巧,让你不再为IP封禁烦恼了!
本文介绍了Python爬虫应对IP封禁的策略,包括使用代理IP隐藏真实IP、选择稳定且数量充足的代理IP服务商、建立代理IP池增加爬虫效率、设置合理抓取频率以及运用验证码识别技术。这些方法能提升爬虫的稳定性和效率,降低被封禁风险。
24
0
0
|
13天前
|
数据采集
存储
JSON
Python爬虫面试:requests、BeautifulSoup与Scrapy详解
【4月更文挑战第19天】本文聚焦于Python爬虫面试中的核心库——requests、BeautifulSoup和Scrapy。讲解了它们的常见问题、易错点及应对策略。对于requests,强调了异常处理、代理设置和请求重试;BeautifulSoup部分提到选择器使用、动态内容处理和解析效率优化;而Scrapy则关注项目架构、数据存储和分布式爬虫。通过实例代码,帮助读者深化理解并提升面试表现。
16
0
0
|
16天前
|
数据采集
Web App开发
开发者
|
17天前
|
存储
数据采集
NoSQL
使用Python打造爬虫程序之数据存储与持久化:从网络到硬盘的无缝对接
【4月更文挑战第19天】本文探讨了爬虫中的数据存储与持久化技术,包括文本文件存储、数据库(关系型与非关系型)、NoSQL数据库和键值存储,以及ORM框架的使用。根据数据类型、规模和访问需求选择合适存储方式,并注意数据安全、备份和恢复策略。正确选择和应用这些技术能有效管理和利用爬取数据。
20
0
0
热门文章
最新文章
1
阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
2
使用Python实现DBSCAN聚类算法
3
Python与NoSQL数据库(MongoDB、Redis等)面试问答
4
流畅的 Python 第二版(GPT 重译)(一)(1)
5
【Python】python天气数据抓取与数据分析(源码+论文)【独一无二】
6
流畅的 Python 第二版(GPT 重译)(十一)(1)
7
【python】Python航空公司客户价值数据分析(代码+论文)【独一无二】
8
Python 数据分析(PYDA)第三版(三)(1)
9
Python速成篇(基础语法)上
10
流畅的 Python 第二版(GPT 重译)(九)(2)
1
在Python中,如何使用装饰器重写类的方法?
24
2
Python中的装饰器:概念、应用与实例
17
3
Python中的JSON模块:从基础到高级应用全解析
85
4
【python】—— python的基本介绍并附安装教程
33
5
Python爬虫-使用代理伪装IP
28
6
python爬虫 Appium+mitmdump 京东商品
32
7
Python教程第10章 | 通俗易懂学装饰器
19
8
Python教程第9章 | 通俗易懂学闭包
15
9
Python教程第8章 | 线程与进程
38
10
登录态数据抓取:Python爬虫携带Cookie与Session的应用技巧
34