福利:
- 国际顶级盛会HBaseCon Asia 2018将于8月在北京举行,目前正免费开放申请中,更多详情参考https://yq.aliyun.com/promotion/631
- 如果你对大数据存储、分布式数据库、HBase等感兴趣,欢迎加入我们,一起做最好的大数据在线存储,职位参考及联系方式
前言
你可曾遇到这种需求,只有几百qps的冷数据缓存,却因为存储水位要浪费几十台服务器?你可曾遇到这种需求,几百G的表,必须纯cache命中,性能才能满足业务需求?你可曾遇到,几十M的小表,由于qps过高,必须不停的split,balance,利用多台服务器来抗热点?
面对繁杂的场景,Ali-HBase团队一直致力于为业务提供更多的选择和更低的成本。本文主要介绍了hbase目前两种提高压缩率的主要方法:压缩和DataBlockEncoding。
无损压缩:更小,更快,更省资源
通用压缩是数据库减少存储的重要手段,在hbase中也存在广泛应用。通常数据库都存在数据块的概念,针对每个块做压缩和解压。块越大,压缩率越高,scan throughput增加;块越小,latency越小。作为一种Tradeoff,线上hbase通常采用64K块大小,在cache中不做压缩,仅在落盘和读盘时做压缩和解压操作。
开源hbase通常使用的LZO压缩或者Snappy压缩。这两种压缩的共同特点是都追求较高的压缩解压速度,并实现合理的压缩率。然而,随着业务的快速增涨,越来越多的业务因为因为存储水位问题而扩容。hbase针对这一情况,采用了基于跨集群分区恢复技术的副本数优化、机型升级等优化手段,但依然无法满足存储量的快速膨胀,我们一直致力于寻找压缩更高的压缩方式。
新压缩(zstd、lz4)上线
Zstandard(缩写为Zstd)是一种新的无损压缩算法,旨在提供快速压缩,并实现高压缩比。它既不像LZMA和ZPAQ那样追求尽可能高的压缩比,也不像LZ4那样追求极致的压缩速度。这种算法的压缩速度超过200MB/s, 解压速度超过400MB/s,基本可以满足目前hbase对吞吐量的需求。经验证,Zstd的数据压缩率相对于Lzo基本可以提高25%-30%,对于存储型业务,这就意味着三分之一到四分之一的的成本减少。
而在另一种情况下,部分表存储量较小,但qps大,对rt要求极高。针对这种场景,我们引入了lz4压缩,其解压速度在部分场景下可以达到lzo的两倍以上。一旦读操作落盘需要解压缩,lz4解压的rt和cpu开销都明显小于lzo压缩。
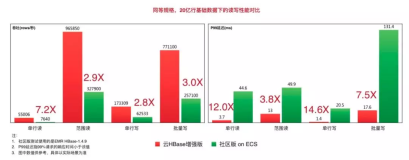
我们通过一张图片直观的展示各种压缩算法的性能:

以线上几种典型数据场景为例,看看几种压缩的实际压缩率和单核解压速度(以下数据均来自于线上)
| 业务类型 | 无压缩表大小 | LZO(压缩率/解压速度MB/s) | ZSTD(压缩率/解压速度MB/s) | LZ4(压缩率/解压速度MB/s) |
|---|---|---|---|---|
| 监控类 | 419.75T | 5.82/372 | 13.09/256 | 5.19/463.8 |
| 日志类 | 77.26T | 4.11/333 | 6.0/287 | 4.16/ 496.1 |
| 风控类 | 147.83T | 4.29/297.7 | 5.93/270 | 4.19/441.38 |
| 消费记录 | 108.04T | 5.93/316.8 | 10.51/288.3 | 5.55/520.3 |
目前,2017年双11,ZSTD已经在线上全面铺开,已累计优化存储超过2.5PB,预计全面推开后,节约存储空间超过15PB。LZ4也已经在部分读要求较高业务上线。
下图为某监控类应用zstd压缩算法后,集群整体存储量的下降情况。数据量由100+T减少到75T。

编码技术:针对结构化数据的即查即解压
hbase作为一种schema free的数据库,相当于传统的关系型数据库更加灵活,用户无需设计好表的结构,也可以在同一张表内写入不同schema的数据。然而,由于缺少数据结构的支持,hbase需要很多额外的数据结构来标注长度信息,且无法针对不同的数据类型采用不同的压缩方式。针对这一问题,hbase提出了编码功能,用来降低存储开销。由于编码对cpu开销较小,而效果较好,通常cache中也会开启编码功能。
旧DIFF Encoding介绍
hbase很早就支持了DataBlockEncoding,也就是是通过减少hbase keyvalue中重复的部分来压缩数据。 以线上最常见的DIFF算法为例,某kv压缩之后的结果:
- 一个字节的flag(这个flag的作用后面解释)
- 如果和上个KV的键长不一样,则写入1~5个字节的长度
- 如果和上个KV的值长不一样,则写入1~5个字节的长度
- 记录和上个KV键相同的前缀长度,1~5个字节
- 非前缀部分的row key
- 如果是第一条KV,写入列族名
- 非前缀部分的的列名
- 写入1~8字节的timestamp或者与上个KV的timestamp的差(是原值还是写与上个KV的差,取决于哪个字节更小)
- 如果和上个KV的type不一样,则写入1字节的type(Put,Delete)
- Value内容
那么在解压缩时,怎么判断和上个KV的键长是否一样,值长是否一样,写入的时间戳究竟是是原值还是差值呢?这些都是通过最早写入的1个字节的flag来实现的,
这个字节中的8位bit,含义是:
- 第0位,如果为1,键长与上个kv相等
- 第1位,如果为1,值长与上个kv相等
- 第2位,如果为1,type与上个kv一样
- 第3位,如果为1,则写入的timestamp是差值,否则为原值
- 第456位,这3位组合起来的值(能表示0~7),表示写入的时间戳的长度
- 第7位,如果为1,表示写入的timestamp差值为负数,取了绝对值。
.png | center | 704x327")
DIFF 编码之后,对某个文件的seek包含以下两步:
- 通过index key找到对应的datablock
- 从第一个完整KV开始,顺序查找,不断decode下一个kv,直到找到目标kv为止。
通过线上数据验证,DIFF encoding可以减少2-5倍的数据量。
新Indexable Delta Encoding上线
从性能角度考虑,hbase通常需要将Meta信息装载进block cache。如果将block大小较小,Meta信息较多,会出现Meta无法完全装入Cache的情况, 性能下降。如果block大小较大,DIFF Encoding顺序查询的性能会成为随机读的性能瓶颈。针对这一情况,我们开发了Indexable Delta Encoding,在block内部也可以通过索引进行快速查询,seek性能有了较大提高。Indexable Delta Encoding原理如图所示:.png | center | 704x320")
在通过BlockIndex找到对应的数据块后,我们从数据块末尾找到每个完整KV的offset,并利用二分查找快速定位到符合查询条件的完整kv,再顺序decode每一个Diff kv,直到找到目标kv位置。
通过Indexable Delta Encoding, HFile的随机seek性能相对于使用之前翻了一倍,以64K block为例,随机seek性能基本与不做encoding相近.在全cache命中的随机Get场景下,相对于Diff encoding rt下降50%,但存储开销仅仅提高3-5%。Indexable Delta Encoding目前已在线上多个场景应用,经受了双十一的考验。以风控集群为例,双集群双十一高峰期访问量接近,但已经上线Indexable Delta Encoding的集群在访问量稍多的情况下,平均读rt减少10%-15%。


未来
性能优化和用户体验,一直是阿里hbase的团队不懈的追求。我们一直在不断丰富自己的武器库,努力做最好的海量数据在线存储产品。欢迎对hbase实现,使用有任何问题的同学联系我们.