近期因公司在各云产品使用上的一些情况,与阿里云各专家们进行了交流,从中深入的了解了阿里云安全WAF与DB两款产品,以此分享出来给大家参考。
阿里云MVP 云集 基础服务技术负责人 张强
1、web应用攻击防护
主要作用:防护常见的攻击手段,如SQL注入攻击,XSS跨站攻击等、配置后实时生效;
实现原理:根据URL请求参数实时校验,若发现URL中带有SQL或者JS等脚本语句,直接在网络层拦截。
2、恶意IP惩罚
主要作用:若发现同一IP在短时间内发生多次WEB攻击,自动将该IP拉黑一段时间,目前时间间隔与攻击次数只能由阿里云配置。
实现原理:结合WEB应用攻击防护,统计单位时间内的攻击频率,实现原理较简单。
3、CC安全防护
主要作用:基于IP+URL的组合防护策略,如针对某个IP在某个URL单位时间内的请求频率统计限制,规则可以自己指定,单目前不支持一个URL多个规则,阿里云正在优化。
实现原理:记录某个IP在某个URL上单位时间内的请求频率,跟恶意IP惩罚原理类似。
4、精准访问控制
主要作用:可对常见的HTTP请求字段进行条件组合,适用于对某个请求有特殊严格限制的操作。
实现原理:将HTTP请求中的IP、URL、Referer、Cookie、Header、Content-Type、X-forwarded-For等信息获取出来,根据用户指定的规则触发动作,相对于web攻击、IP惩罚、CC防护来说控制的条件粒度可以更细。
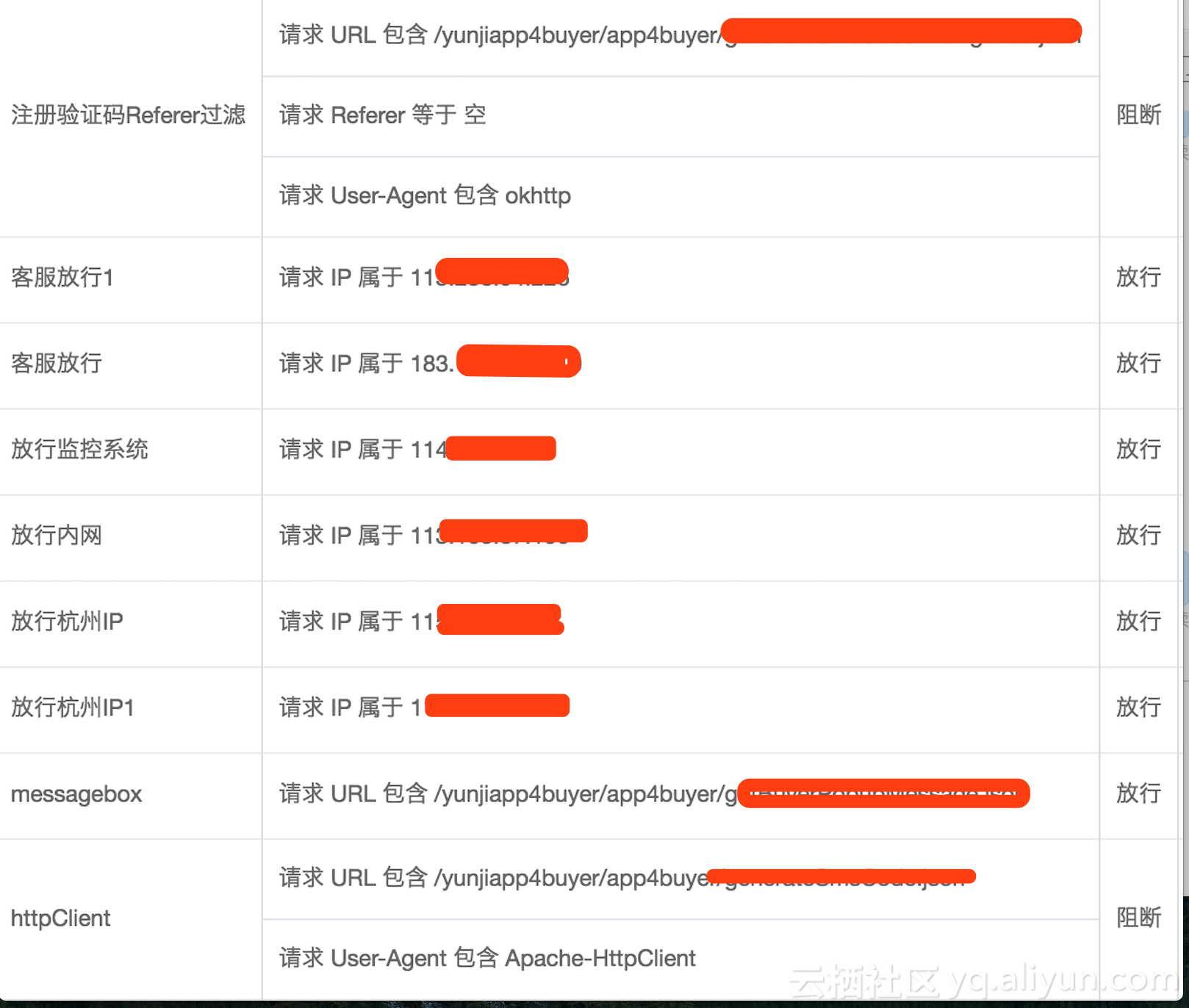
注意入坑:精准访问控制的匹配规则是根据列表,从上到下的匹配,若匹配上一条规则,则按照匹配上的条件来执行动作,不会继续往下执行,所以注意规则列表中的排列顺序;
e.g: 如下图排序,当杭州IP与客服IP访问注册验证码地址时,若匹配上规则,照样被拦截,IP放行将失效。
5、禁封地区
主要作用:禁止某个地区的IP请求访问。
实现原理:根据IP段来限制请求访问,实现原理比较简单。
6、网页防篡改
主要作用:锁定页面内容,防止人员手动误改或者黑客入侵后篡改,多应用于.org等类似政府网站。
实现原理:将设置的某个页面缓存处理。在设置的时间内返回固定的内容,实现比较简单。
7、数据风控
主要作用:识别黑白请求,如批量注册,批量刷某个接口等,防止非法跳跃式请求,目前数据风控只支持H5或网页端。
实现原理:在HTML页面插入token,正常请求链路都会有token附加信息,并且有效期只有一次,若直接跳跃请求,没有token信息或者token信息失效则断定为恶意请求;如A---B,从A正常跳转到B是带有token信息的,直接访问到B则链路上不会有token信息。
8、防敏感信息泄露
主要作用:避免重要信息泄露,如银行卡、身份证、手机号码等,针对返回报文信息做拦截处理。
实现原理:针对返回报文进行识别处理,若返回的接口不在白名单,并且有明感信息,则将报文中明感信息剔除,可能对前端样式内容等产生影响。
DB:
DB这块主要咨询了阿里云2个产品与RDS日常使用中遇到问题,包括注意点、排查思路、解决方案、SQL索引相关等,分开来介绍。
DB产品这块阿里云官方介绍有,但是写的比较商业化,按照个人的理解与阿里云的介绍来描述下:
1)、POLADB
阿里云自研的一款DB,其核心原理是一写多读、分布式存储、看下阿里云的设计架构图:
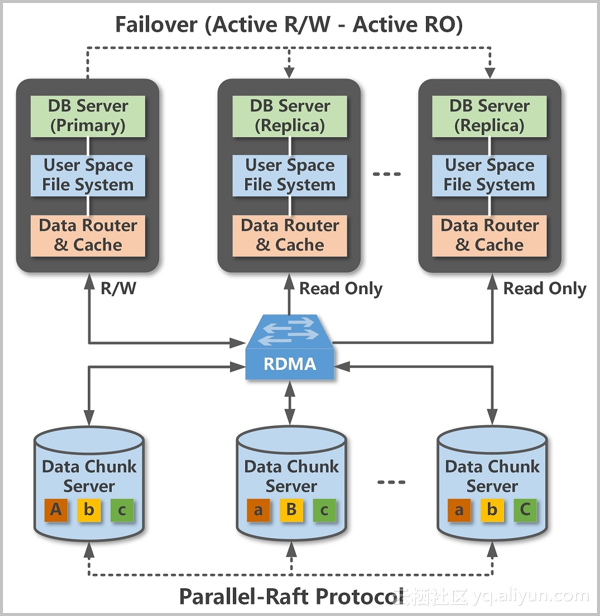
采用计算与存储分离的设计理念,满足公有云计算环境下用户业务弹性扩展的刚性需求。数据库的计算节点(DB Server)仅存储元数据,而将数据文件、Redo Log等存储于远端的存储节点(Chunk Server)。各计算节点之间仅需同步Redo Log相关的元数据信息,极大降低了主实例和只读实例间的延迟,而且在主实例故障时,只读实例可以快速切换为主服务器,由于是分布式存储,是的I/O不在是瓶颈点,支持上百TB级别数据。
PS:同开源MYSQL相比,拥有高性能(读写分离),阿里云号称比开源MYSQL性能提高6倍,100%兼容原生态MYSQL,支持数据量存储的同时保证了读写性能,主要用户大数据下OLTP类型的等值计算。
官方资料:https://help.aliyun.com/product/58609.html?spm=a2c4g.11186623.3.1.Arp1jP
2、HybridDB
设计思想就是链路、计算和存储分离,实现松耦合分布式架构的HTAP数据库云服务,架构图如下:
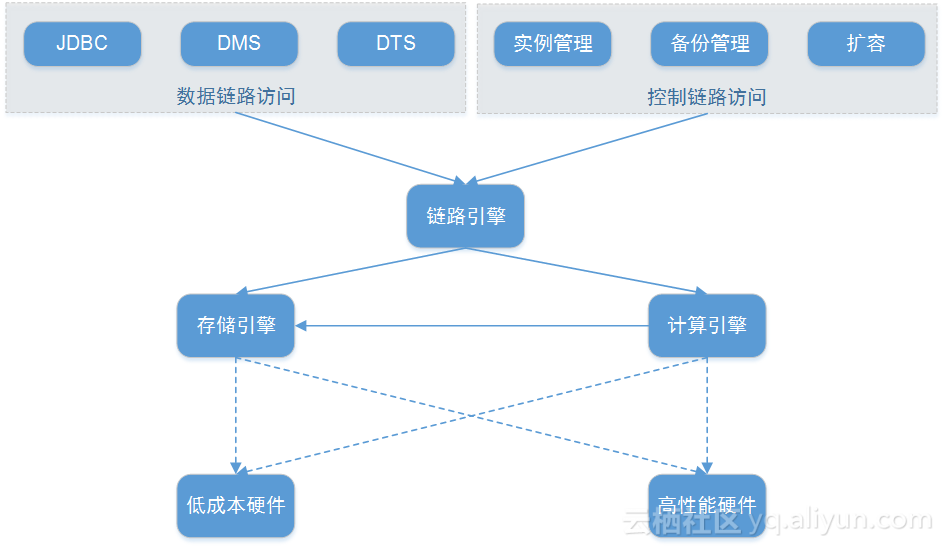
可以这么来理解,大数据下分库分表的封装,类似云集现有的订单sharding库,只不过阿里云做了更全面的封装,如面对用户的只有一个库,其实内部是做了路由的,用户只要在创建表的时候指定路由规则即可,后续操作跟单台MYSQL完全一样,不用管路由算法,另外封装了多库连表查询,如where后面跟的是时间区间,数据散落在不同的分片时候,链路引擎会将不同节点的数据汇总后呈现给用户,让用户无感知的操作,可以基于一份数据OLTP与OLAP混合处理;由于面对用户的只是个proxy,所以可以做到无缝隙的动态扩容;了解的过程中可以拿POLADB与云集的order Sharding进行对比理解。
PS:虽然封装完美,但也有自身痛点,总结一句话叫:上云容易下云难,下云后继续使用阿里云的POLADB能顶住,但如果自建MYSQL,数据层需要大改,并且自己写路由规则。
3、RDS使用问题与解决
这块描述下日常使用RDS需要注意的事项:
1、高可用切换原理:现将Master置为readOnly,Slave完成binlog同步与数据迁移后,Slave成为Master,Master停用,如果RDS前有挂proxy,闪短时间30内,若没挂,闪短时间约为10分钟左右,闪短期间数据库状态为readOnly状态。
2、设置 loose_max_statement_time:超时时间指的是SQL的执行处理时间,不包含排队等待时间。
3、若出现KILL不掉某种SQL进程时候(批量来源),可以使用SQL限流来处理,以免出现一条SQL拖垮整库的情况。
SQL Filter
SET GLOBAL sql_select_filter = '+,{CONC},KEY1~KEY2~KEY3.....';
e.g.
SET GLOBAL sql_select_filter = '+,10,a=1~b=2';
作用:
对同时包含 a=1 和 b=2 两个关键字的SQL,限制最高并发线程为10;
注意:一般只对select进行限制如慢SQL,竞争锁等,注意关键字,如where等。
PS:阿里云RDS封装后的功能,原生态开源MYSQL没有此功能。
4、联合索引创建的优先顺序:如果出现有表需要建立联合索引的情况,可以通入如下方式来排列优先级
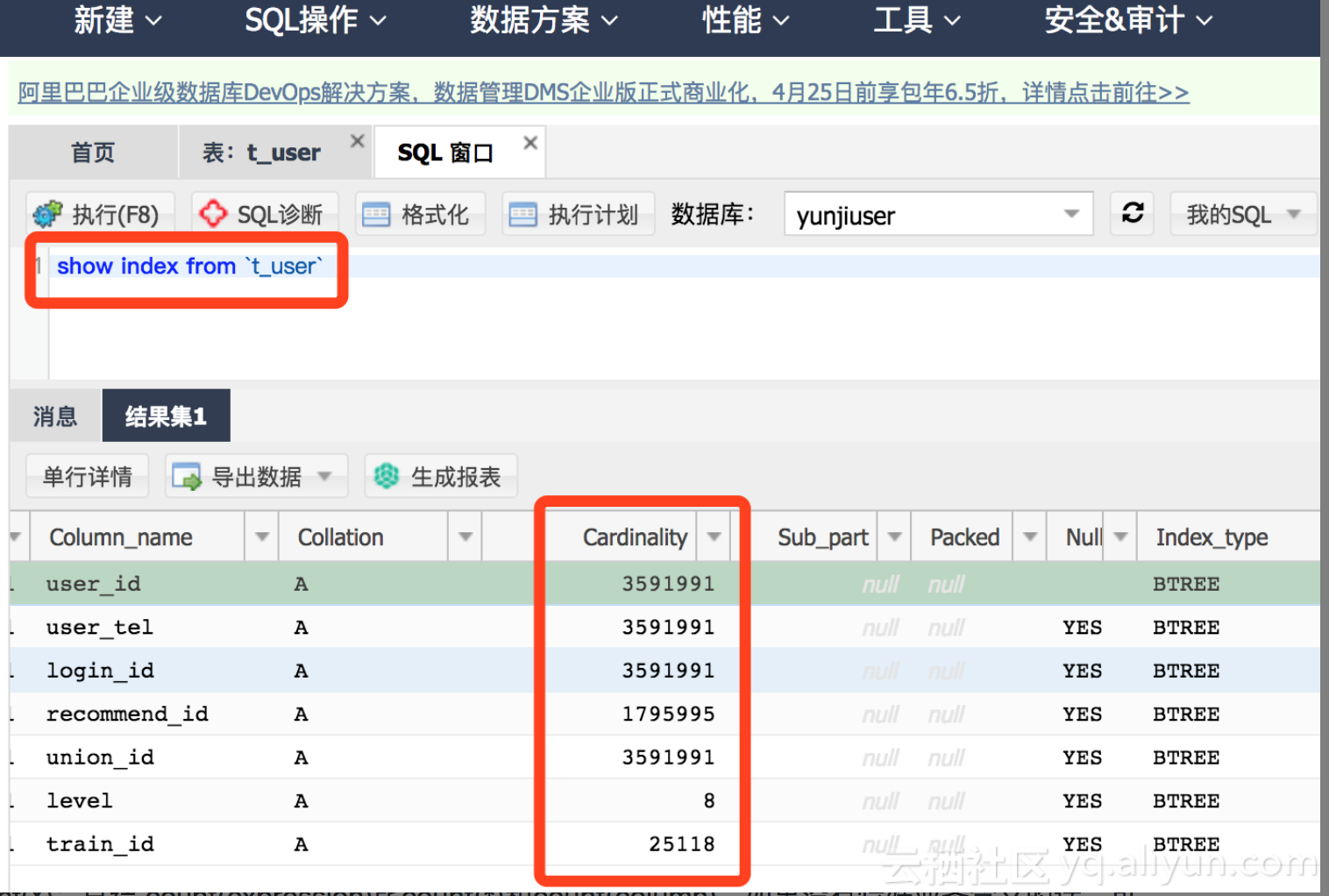
方法一:
show index from `t_user` --查看t_user表索引
select count(DISTINCT(`user_id`)) /count(*) from t_user;--若等于1,说明user_id建立所以的优先级最高
select count(DISTINCT(concat(`user_name` ,`user_id`))) /count(*) from t_user; --哪个值越接近1,则优先级越高,从左到右排列。
方法二:如下图,数值越高则优先级越高。
5、count(*) VS count(X):总结 count(expression)比count(*)和count(column),如果没有特殊业务含义的话,可以优先使用,具体可参考阿里云测试说明https://yq.aliyun.com/articles/379946?spm=a2c4e.11155435.0.0.16813312gMppl0
6、补天临时参数设置:
1、 rds_max_tmp_disk_space:控制 MySQL 能够使用的临时文件的大小,适用于一个 SQL 语句就消耗掉整个数据库的磁盘空间;
2、tokudb_buffer_pool_ratio:控制 TokuDB 引擎能够使用的 buffer 内存大小,适用于选择了 tokudb 作为存储引擎的场景;
3、loose_max_statement_time:控制单个 SQL 语句的最长执行时间,适用于控制数据库中的慢 SQL 数量;
4、rds_threads_running_high_watermark:控制 MySQL 并发的查询数目,常用于秒杀场景的业务;
7、其他参考资料
https://yq.aliyun.com/articles/348692?spm=a2c4e.11155435.0.0.7ec533128qCgdf
https://yq.aliyun.com/articles/348688?spm=a2c4e.11155435.0.0.7ec533128qCgdf
https://github.com/alibaba/AliSQL/wiki/Changes-in-AliSQL-5.6.32-(2016-09-15)#10-sql-filter
https://github.com/alibaba/AliSQL/wiki/Changes-in-AliSQL-5.6.32-(2016-10-14)#2-hint-solution-for-inventory
https://github.com/alibaba/AliSQL/wiki/Changes-in-AliSQL-5.6.32-(2017-05-04)#2-thread-pool
https://github.com/alibaba/AliSQL/wiki/Changes-in-AliSQL-5.6.32-(2016-09-15)#3-ddl-fast-fail
总结:以上内容总结到此结束,若有疑问欢迎各位咨询;另,学到并且能用到,能解决问题才是王道。