最近机器学习很热,作为机器学习在图像识别方面最火的研究领域,神经网络将图像识别带入了新的高度,很多之前还只能在实验室中的理想情况下的成果,目前已经大量的运用在了实际生产环境中了,了解一些神经网络的知识,不仅能拓宽自己的视野,关键时刻这还是一种很好的省钱省力的解决方案。最近在做端到端的识别的研究,刚刚将模型搭建完毕,想着用什么方式测试一下呢?目前网上最多的就是验证码图片了,随便一个网站都能拔下来一堆,借助一些打码平台,能很快的完成数据的标注工作,正好把刚刚搭建完成的end-to-end的识别模型在这些验证码上一试。
好了背景介绍完了,为了接下来介绍一些原理性的东西,一些基本术语的概念需要先明晰一下:
机器学习解决问题主要是分类问题和回归问题
回归问题:概括的讲就是用于分析两个变量X和Y之前的关系。希望能找到一个模型来尽量的表示Y=f(X),其中的f就是需要学习的模型。例如X:表示房屋大小,Y:表示房屋价格,当你获取多组数据以后,就要尽量建模来拟合X和Y之间的关系。

分类问题:根据物体一系列的特征,通过模型对问题进行分类。例如通过图像的像素,判断图像中的物体,这就是典型的图像识别问题。例如根据组人口袋中钱的数量将其分类为高富帅或是屌丝。
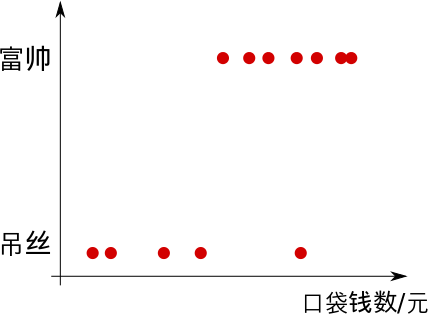
分类和回归的根本区别就在于分类是已经划定了最终结果的数量(离散值),而回归的结果是一串可能的值(连续值)。具体到下面介绍的神经网路,主要是用来解决分类问题。
卷积:卷积就是一种数学运算,主要是用来提取特征。左侧绿色的部分的5×5矩阵就象征着我们输入图片的像素值,然后上面的3×3黄色部分矩阵就是我们的卷积核,让卷积核在输入矩阵上进行从左到右,从上到下滑动,然后每一次滑动,两个矩阵对应位置就进行内积,对应的结果就转化为右边矩阵的一个元素值。
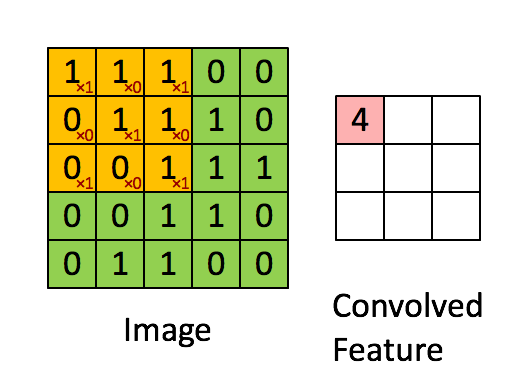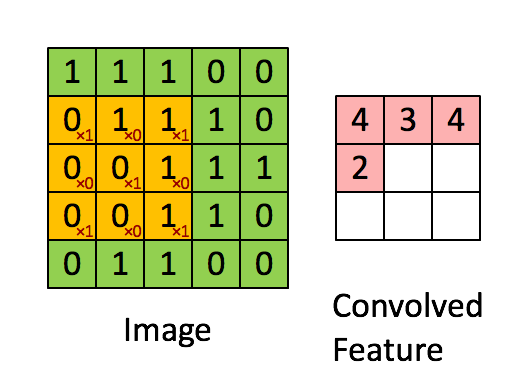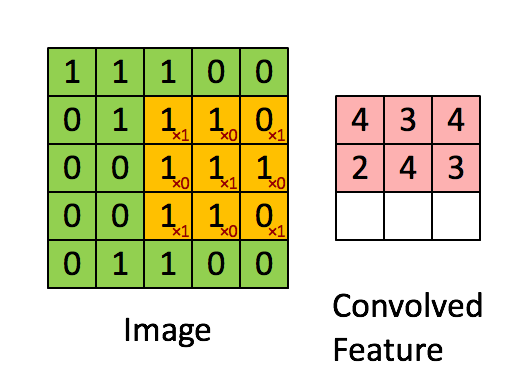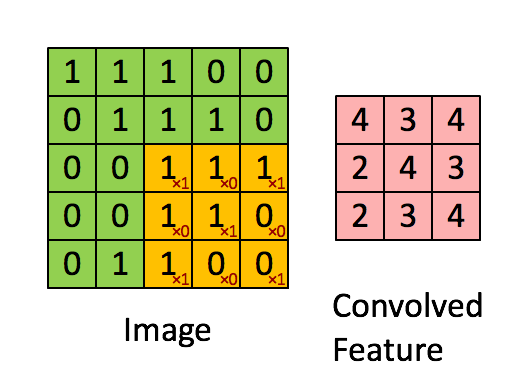
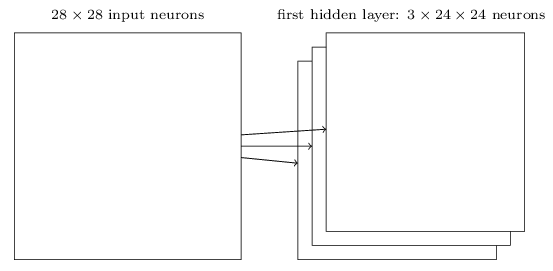
当然进行一次卷积运算就能得到右边的特征,要是进行多次呢,当然就提取到多个特征了,多个特征以多层(又叫通道或者feature map)的方式表示,提取的特征越多表达能力就越强,当然也可能越来越陷入过拟合。例如下图通过三个5×5大小的卷积核,对一张28 × 28像素的图片进行卷积操作,最终会得到三个特征层。
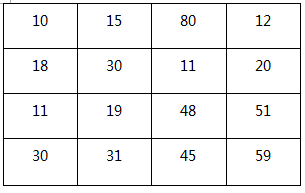
池化:也叫下采样,通常有Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping (重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样),主要是用来减少计算量(减少参数个数)和旋转不变性(抗噪)。其中最经典的Max pooling(最大值采样)的过程是,对于左边的4×4大小的像素块,通过进行2×2大小的MAX POOLING区域块,每次取值都取相隔一个POOLING的区域块中的最大值,最终变为右侧2×2大小的像素块。这样参数个数减少了一倍,而且由于是区域的最值,也保留这个区域的特征,微小的改变不会影响它的结果。

全连接:顾名思义就是输出的神经元和输入的每个神经元都连接,如图左所示,用于将提取到的每一部分的特征进行汇总。当然这样的问题就是计算量非常的大,如果我们有1000x1000像素的图像,有1百万个隐层神经元,每个隐层神经元都连接图像的每一个像素点,就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数,可以看到全连接的方式会产生大量的参数,因此一般都是在网络的最后,此时经过卷积和池化的特征已经比最开始的时候少了很多,此时才进行全连接。减少这些参数的方式是使用局部连接,每一个节点仅与上层节点同位置附件10x10的窗口相连接,则1百万个隐层神经元就只有100w乘以100,即10^8个参数。其权值连接个数比原来减少了四个数量级,这就是“稀疏连接”的思想。更进一步的,假如这些链接中的参数都是一样的呢,那么就只需要100个参数就好了,比之前的天文数字降低了好多,这就是“权值共享”的思想。这就是上边卷积操作的由来,因此卷积也能看做是特殊的全链接。这些思想有效的降低了问题规模,使得训练深度神经网络成为可能。

说到神经网络,尤其是图像识别领域,一个很基础也是很重要的例子就是MNIST手写数字识别,他是由60000张训练数据和10000张测试数据组成的数据集,每张图片大小为32*32的灰度图(也就是像素点用0-255个色阶表示)。他就相当于我们学习每种语言的时候,最开始的例子都是Hello Word一样。学习他的原理可以最快的了解神经网络中所用方法的基本知识。

LeNet-5是对MNIST集合学习的重要模型(当年美国大多数银行就是用它来识别支票上面的手写数字的。能够达到这种商用的地步,它的准确性可想而知),这个模型虽然只有七层,但它包含了卷积神经网络中主要的步骤和流程。

C1层:首先对于输入的32×32大小的图片,用6个5×5大小的卷积核进行卷积运算,获取C1层6个28×28大小的特征图。
S2层:之后也就是下采样层,通过MAX POOLING的方式,选取2×2大小的POOLING大小,相当于进行分块,这样就得到了14×14个块的S2了。
C3层:也是类似C1层的卷积操作,不过这16层可不是用16个卷积核,而使用上面6层的组合得来的,这里就不详细解释了,有兴趣的朋友可以查一下。
S4层:就是类似S2层的下采样,这时候我们发现之前的32×32的图片,经过处理已经变成了16张大小为5×5的特征图了。
C5 C6层:之后的就是全连接层还有输出了,网络会根据提取到的特征判断输入的图片最可能分成什么类。
那么到底他是怎么利用这些特征判断的呢,有一个不太恰当但是利于理解的例子是假如对下图“0”,从提取到的以下特征就可以发现,他们组合起来就是一个0。说他不太恰当是因为最终的特征都是机器自己总结归纳的,到底是不是这样图像的我们就不得而知了,这里仅仅是为了易于理解的展示。实际上神经网络进行的就是“编解码”工作,将训练样本的特征进行抽象的编码,之后根据提取到的特征再次尝试进行解码还原,学习每一层的参数。这也恰恰是神经网络强大的地方,传统的做法会去人为的提取图像特征,像是GIST、HOG、SIFT特征,这些精心设计的特征很难去泛化,往往在新的数据集上的效果急剧下降,而卷积神经网络是在大量的数据集上自学习的特征提取,泛化性能强大。



说了这么多MNIST的手写字符的识别,和今天的主题是不是有点跑题啊,其实一点都不跑题,既然已经能准确的识别一个字符了,那么其实验证码就是多个字符的识别,本质是一样的道理,识别一个字符的时候每次的输出结果都是一个0-9或者a/A-z/Z的字符,输出空间为10 + 26 × 2,那么识别多个字符比如4位的验证码呢?实际上就是输出4个字符对应的样本空间4 × (10 + 26 × 2)。我们使用Tensorflow这个机器学习的开发框架,Tensorflow是谷歌于2015年开源的一个机器学习的框架,自己开发了这么好的框架就直接开源了,很佩服google的战略眼光和技术能力,经过一年时间它也确实不负众望的成为了git上最火的开源项目。需要识别的验证码就如下图一样,由于需要预先的训练,验证码的命名方式是“label_uuid”,前面的label用来训练,后面的uuid避免相同的label不同样子的图片命名冲突。

tensorflow中构造的模型代码如下(mode.py):
def convolutional_layers():
"""
Get the convolutional layers of the model.
"""
x = tf.placeholder(tf.float32, [None, None, None])
# First layer
W_conv1 = weight_variable([5, 5, 1, 16])
b_conv1 = tf.Variable(tf.zeros([16]))
x_expanded = tf.expand_dims(x, 3)
h_conv1 = tf.nn.relu(conv2d(x_expanded, W_conv1) + b_conv1)
h_pool1 = max_pool(h_conv1, ksize=(2, 2), stride=(2, 2))
# Second layer
W_conv2 = weight_variable([5, 5, 16, 32])
b_conv2 = bias_variable([32])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool(h_conv2, ksize=(2, 2), stride=(2, 2))
# Third layer
W_conv3 = weight_variable([5, 5, 32, 48])
b_conv3 = bias_variable([48])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
h_pool3 = max_pool(h_conv3, ksize=(2, 2), stride=(2, 2))
return x, h_pool3, [W_conv1, b_conv1,
W_conv2, b_conv2,
W_conv3, b_conv3]def get_model(train=False, ):
x, conv_layer, conv_vars = convolutional_layers()
# Densely connected layer
W_fc1 = weight_variable([48 * 7 * 5, 256])
b_fc1 = bias_variable([256])
conv_layer_flat = tf.reshape(conv_layer, [-1, 48 * 7 * 5])
h_fc1 = tf.nn.relu(tf.matmul(conv_layer_flat, W_fc1) + b_fc1)
if train:
h_fc1 = tf.nn.dropout(h_fc1, 0.9, seed=SEED)
# Output layer
W_fc2 = weight_variable([256, 1 + 4 * len(common.CHARS)])
b_fc2 = bias_variable([1 + 4 * len(common.CHARS)])
y = tf.matmul(h_fc1, W_fc2) + b_fc2
return (x, y, conv_vars + [W_fc1, b_fc1, W_fc2, b_fc2])前三层(layer)的结构类似于上面LeNet-5前几层的结构,都是卷积层接着MAX POOLING,主要是用于提取图像的特征,后两层也是类似的全连接层,用于组合这些特征以便获取结果,最后一层的输出是1+4 × len(common.CHARS),1表示输出的“是否”验证码图片,4 × len(common.CHARS)表示的就是上面所说的样本空间了。返回的信息中,x指代输入的内容tensor(Tensorflow中的基本数据结构),y表明最终的预测结果,之后的列表中存储的是各层中用到的参数,训练的目的就是学习这些参数的值,一旦完成训练,就可以通过这些参数直接预测图片。
用8000多张验证码的图片进行训练,由于不可避免的少量的标注有错误会影响一些最后的效果,最终在500张测试集图片上验证的准确率达到了87%,当然随着训练数据的增多和网络的进一步优化,这个准确率是可以进一步提升的,虽然没有达到99%的准确率,但是我们工业上和实验上一个很重要的区别就是我们能用策略弥补不足之处,加入反复请求3次的策略,这样最终的准确率就是(1-0.13×0.13×0.13)×100% =99.7803%,完全达到使用标准,通过图表可以直观的对比一下训练的网络和打码平台的效果,可以看到正确率直接上了一个等级。

当然这种类型的验证码属于很好识别的,更复杂的例如google的验证码,其中包含了更多的字符还有很多字符的形变和粘连,就需要更大量的训练样本和更复杂的网络,目前来看双向RNN的网络可以通过更少的样本取得更好的效果,那又是一个CTC的故事,不过鉴于篇幅有限这个留着下次再来分享吧。
总结一下,其实这次的文章仅仅很粗略的介绍了一下神经网络的相关知识,很多关键的点如损失函数,激活函数和权重更新等虽然代码中也有所涉及,但是由于篇幅有限都没有说,还有一些数学公式也没有列出,希望这次全作为一个抛砖引玉,喜欢的同学能在网上找到很多的类似资料学习,让我们共同学习,让机器更加聪明,让人们更加轻松。
更多的公式以及公式的图像表示的学习建议查看:https://www.zhihu.com/question/31497611?location=35