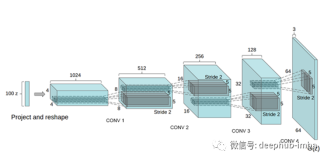
之前在DCGAN文章简单解读里说明了DCGAN的原理。本次来实现一个DCGAN,并在数据集上实际测试它的效果。本次的代码来自github开源代码DCGAN-tensorflow,感谢carpedm20的贡献!
1. 代码结构
代码结构如下图1所示:

我们主要关注的文件为download.py,main.py,model.py,ops.py以及utils.py。其实看文件名字就大概可以猜出各个文件的作用了。
- download.py主要下载数据集到本地,这里我们需要下载三个数据集:MNIST,lsun以及celebA。
- main.py是主函数,用于配置命令行参数以及模型的训练和测试。
- model.py 是定义DCGAN模型的地方,也是我们要重点关注的代码。
- ops.py 定义了很多构造模型的重要函数,比如batch_norm(BN操作),conv2d(卷积操作),deconv2d(翻卷积操作)等。
-
utils.py 定义很多有用的全局辅助函数。
2. 代码简单解读
2.1 download.py
download.py代码如下:
"""
Modification of https://github.com/stanfordnlp/treelstm/blob/master/scripts/download.py
Downloads the following:
- Celeb-A dataset
- LSUN dataset
- MNIST dataset
"""
from __future__ import print_function
import os
import sys
import gzip
import json
import shutil
import zipfile
import argparse
import requests
import subprocess
from tqdm import tqdm
from six.moves import urllib
parser = argparse.ArgumentParser(description='Download dataset for DCGAN.')
parser.add_argument('datasets', metavar='N', type=str, nargs='+', choices=['celebA', 'lsun', 'mnist'],
help='name of dataset to download [celebA, lsun, mnist]')
def download(url, dirpath):
filename = url.split('/')[-1]
filepath = os.path.join(dirpath, filename)
u = urllib.request.urlopen(url)
f = open(filepath, 'wb')
filesize = int(u.headers["Content-Length"])
print("Downloading: %s Bytes: %s" % (filename, filesize))
downloaded = 0
block_sz = 8192
status_width = 70
while True:
buf = u.read(block_sz)
if not buf:
print('')
break
else:
print('', end='\r')
downloaded += len(buf)
f.write(buf)
status = (("[%-" + str(status_width + 1) + "s] %3.2f%%") %
('=' * int(float(downloaded) / filesize * status_width) + '>', downloaded * 100. / filesize))
print(status, end='')
sys.stdout.flush()
f.close()
return filepath
def download_file_from_google_drive(id, destination):
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params={ 'id': id }, stream=True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params=params, stream=True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination, chunk_size=32*1024):
total_size = int(response.headers.get('content-length', 0))
with open(destination, "wb") as f:
# 显示进度条
for chunk in tqdm(response.iter_content(chunk_size), total=total_size,
unit='B', unit_scale=True, desc=destination):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
def unzip(filepath):
print("Extracting: " + filepath)
dirpath = os.path.dirname(filepath)
with zipfile.ZipFile(filepath) as zf:
zf.extractall(dirpath)
os.remove(filepath)
def download_celeb_a(dirpath):
data_dir = 'celebA'
# ./data/celebA
if os.path.exists(os.path.join(dirpath, data_dir)):
print('Found Celeb-A - skip')
return
filename, drive_id = "img_align_celeba.zip", "0B7EVK8r0v71pZjFTYXZWM3FlRnM"
# ./data/img_align_celeba.zip
save_path = os.path.join(dirpath, filename)
if os.path.exists(save_path):
print('[*] {} already exists'.format(save_path)) # 文件已经存在
else:
download_file_from_google_drive(drive_id, save_path)
zip_dir = ''
with zipfile.ZipFile(save_path) as zf:
zip_dir = zf.namelist()[0] # 解压以后默认文件夹的名字
zf.extractall(dirpath) # 提取文件到该文件夹
os.remove(save_path) # 移除压缩文件
# 重命名文件夹
os.rename(os.path.join(dirpath, zip_dir), os.path.join(dirpath, data_dir))
def _list_categories(tag):
url = 'http://lsun.cs.princeton.edu/htbin/list.cgi?tag=' + tag
f = urllib.request.urlopen(url)
return json.loads(f.read())
def _download_lsun(out_dir, category, set_name, tag):
# locals(),Return a dictionary containing the current scope's local variables
url = 'http://lsun.cs.princeton.edu/htbin/download.cgi?tag={tag}' \
'&category={category}&set={set_name}'.format(**locals())
print(url)
if set_name == 'test':
out_name = 'test_lmdb.zip'
else:
out_name = '{category}_{set_name}_lmdb.zip'.format(**locals())
# out_path:./data/lsun/xxx.zip
out_path = os.path.join(out_dir, out_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading', category, set_name, 'set')
# 调用linux命令
subprocess.call(cmd)
def download_lsun(dirpath):
data_dir = os.path.join(dirpath, 'lsun')
if os.path.exists(data_dir):
print('Found LSUN - skip')
return
else:
os.mkdir(data_dir)
tag = 'latest'
#categories = _list_categories(tag)
categories = ['bedroom']
for category in categories:
_download_lsun(data_dir, category, 'train', tag)
_download_lsun(data_dir, category, 'val', tag)
_download_lsun(data_dir, '', 'test', tag)
def download_mnist(dirpath):
data_dir = os.path.join(dirpath, 'mnist')
if os.path.exists(data_dir):
print('Found MNIST - skip')
return
else:
os.mkdir(data_dir)
url_base = 'http://yann.lecun.com/exdb/mnist/'
file_names = ['train-images-idx3-ubyte.gz',
'train-labels-idx1-ubyte.gz',
't10k-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz']
for file_name in file_names:
url = (url_base+file_name).format(**locals())
print(url)
out_path = os.path.join(data_dir,file_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading ', file_name)
subprocess.call(cmd)
cmd = ['gzip', '-d', out_path]
print('Decompressing ', file_name)
subprocess.call(cmd)
def prepare_data_dir(path = './data'):
if not os.path.exists(path):
os.mkdir(path)
if __name__ == '__main__':
args = parser.parse_args()
prepare_data_dir()
# 如果datasets参数是 ['CelebA', 'celebA', 'celebA'] 其中之一
if any(name in args.datasets for name in ['CelebA', 'celebA', 'celebA']):
download_celeb_a('./data')
if 'lsun' in args.datasets:
download_lsun('./data')
if 'mnist' in args.datasets:
download_mnist('./data')- 首先需要导入的包中,gzip和zipfile用于文件压缩和解压缩相关;argparse用于构建命令行参数;requests用于http请求下载网络文件资源;subprocess用于运行shell命令;tqdm用于进度条显示;six包用于python2和python3的兼容,比如 from six.moves import urllib 这句就是导入python2.x的urllib库。
- 上面的代码除了原作者加的注释之外,我也已经加了一部分注释,意思应该比较好理解了。主要做的事情,就是利用requests库从网络上将mnist,lsun以及celebA这三个数据集下载下来,保存在data目录下。注意mnist和celebA数据集下载下来之后还进行了解压缩。
- 上面的三个数据集,mnist是著名的手写数字数据库,大家应该都已经很熟悉了;lsun是大型场景理解数据集(large-scale-scene-understanding);celebA是一个开源的人脸数据库。除了mnist之外,其余两个数据集体积都较大,celebA大概有20w+的图像,压缩文件体积为1.4G;而lsun有很多个场景不同的数据集,如果按照上面的脚本下载,下载的文件为bedroom数据集,压缩文件有46G之大,而且其实下载下来的文件解压后为mdb(Access数据库)格式,不是原始图片格式,不方便处理。所以我们实际会下载其他的数据集作为替代,比如这个room layout estimation(2G)数据。如果使用download.py脚本下载速度较慢的话,可以自行下载好数据集,然后放在data目录下即可。
2.2 main.py
main.py代码如下:
import os
import scipy.misc
import numpy as np
from model import DCGAN
from utils import pp, visualize, to_json, show_all_variables
import tensorflow as tf
# tensorflow 定义命令行参数
flags = tf.app.flags
# flag_name, default_value, docstring
flags.DEFINE_integer("epoch", 25, "Epoch to train [25]")
flags.DEFINE_float("learning_rate", 0.0002, "Learning rate of for adam [0.0002]")
flags.DEFINE_float("beta1", 0.5, "Momentum term of adam [0.5]")
flags.DEFINE_float("train_size", np.inf, "The size of train images [np.inf]")
flags.DEFINE_integer("batch_size", 64, "The size of batch images [64]")
flags.DEFINE_integer("input_height", 108, "The size of image to use (will be center cropped). [108]")
flags.DEFINE_integer("input_width", None, "The size of image to use (will be center cropped). If None, same value as input_height [None]")
flags.DEFINE_integer("output_height", 64, "The size of the output images to produce [64]")
flags.DEFINE_integer("output_width", None, "The size of the output images to produce. If None, same value as output_height [None]")
flags.DEFINE_integer("print_every",100,"print train info every 100 iterations")
flags.DEFINE_integer("checkpoint_every",500,"save checkpoint file every 500 iterations")
flags.DEFINE_string("dataset", "celebA", "The name of dataset [celebA, mnist, lsun]")
flags.DEFINE_string("input_fname_pattern", "*.jpg", "Glob pattern of filename of input images [*]")
flags.DEFINE_string("checkpoint_dir", "checkpoint", "Directory name to save the checkpoints [checkpoint]")
flags.DEFINE_string("data_dir", "./data", "Root directory of dataset [data]")
flags.DEFINE_string("sample_dir", "samples", "Directory name to save the image samples [samples]")
flags.DEFINE_boolean("train", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("crop", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("visualize", False, "True for visualizing, False for nothing [False]")
flags.DEFINE_integer("generate_test_images", 100, "Number of images to generate during test. [100]")
FLAGS = flags.FLAGS
def main(_):
pp.pprint(flags.FLAGS.__flags)
# 如果宽度没有指定,那么和高度一样
if FLAGS.input_width is None:
FLAGS.input_width = FLAGS.input_height
if FLAGS.output_width is None:
FLAGS.output_width = FLAGS.output_height
if not os.path.exists(FLAGS.checkpoint_dir):
os.makedirs(FLAGS.checkpoint_dir)
if not os.path.exists(FLAGS.sample_dir):
os.makedirs(FLAGS.sample_dir)
#gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
run_config = tf.ConfigProto()
run_config.gpu_options.allow_growth=True
with tf.Session(config=run_config) as sess:
if FLAGS.dataset == 'mnist':
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
y_dim=10,
z_dim=FLAGS.generate_test_images,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir)
else:
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
z_dim=FLAGS.generate_test_images,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir)
show_all_variables()
if FLAGS.train:
dcgan.train(FLAGS)
else:
# dcgan.load return:True,counter
if not dcgan.load(FLAGS.checkpoint_dir)[0]: #没有成功加载checkpoint file
raise Exception("[!] Train a model first, then run test mode")
# to_json("./web/js/layers.js", [dcgan.h0_w, dcgan.h0_b, dcgan.g_bn0],
# [dcgan.h1_w, dcgan.h1_b, dcgan.g_bn1],
# [dcgan.h2_w, dcgan.h2_b, dcgan.g_bn2],
# [dcgan.h3_w, dcgan.h3_b, dcgan.g_bn3],
# [dcgan.h4_w, dcgan.h4_b, None])
# Below is codes for visualization
OPTION = 4
visualize(sess, dcgan, FLAGS, OPTION)
if __name__ == '__main__':
tf.app.run()- 这里需要注意的是 flags = tf.app.flags 用于tensorflow构建命令行参数, flags.DEFINE_xxx(param,default,description) 用于定义命令行参数及其取值,第一个参数param是具体参数值,第二个参数default是参数默认取值,第三个参数description是参数描述字符串。
- 在构建了sess之后,我们需要区分数据集是mnist还是其他数据集。因为mnist比较特殊,它有10个类别的数字图像,所以我们在构建DCGAN的时候需要额外多传递一个y_dim=10参数。 show_all_variables 函数用于显示model所有变量的具体信息。
- 接下来如果是训练状态( FLAGS.train == True ),则进行模型训练( dcgan.train(FLAGS) ;否则进行测试,即加载之前训练时候保存的checkpoint文件,然后调用 visualize 函数进行test(该函数可以生成image或者gif,可视化展示训练的效果)。
- tf.app.run() 是常用的tensorflow运行的起始命令。
2.3 model.py
model.py代码如下:
from __future__ import division
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
from six.moves import xrange
from ops import *
from utils import *
def conv_out_size_same(size, stride):
return int(math.ceil(float(size) / float(stride)))
class DCGAN(object):
def __init__(self, sess, input_height=108, input_width=108, crop=True,
batch_size=64, sample_num = 64, output_height=64, output_width=64,
y_dim=None, z_dim=100, gf_dim=64, df_dim=64,
gfc_dim=1024, dfc_dim=1024, c_dim=3, dataset_name='default',
input_fname_pattern='*.jpg', checkpoint_dir=None, sample_dir=None, data_dir='data'):
"""
Args:
sess: TensorFlow session
batch_size: The size of batch. Should be specified before training.
y_dim: (optional) Dimension of dim for y. [None]
z_dim: (optional) Dimension of dim for Z. [100]
# 生成器第一个卷积层 filters size
gf_dim: (optional) Dimension of gen filters in first conv layer. [64]
# 鉴别器第一个卷积层filters size
df_dim: (optional) Dimension of discrim filters in first conv layer. [64]
# 生成器全连接层units size
gfc_dim: (optional) Dimension of gen units for for fully connected layer. [1024]
# 鉴别器全连接层units size
dfc_dim: (optional) Dimension of discrim units for fully connected layer. [1024]
# image channel
c_dim: (optional) Dimension of image color. For grayscale input, set to 1. [3]
"""
self.sess = sess
self.crop = crop
self.batch_size = batch_size
self.sample_num = sample_num
self.input_height = input_height
self.input_width = input_width
self.output_height = output_height
self.output_width = output_width
self.y_dim = y_dim
self.z_dim = z_dim
self.gf_dim = gf_dim
self.df_dim = df_dim
self.gfc_dim = gfc_dim
self.dfc_dim = dfc_dim
# batch normalization : deals with poor initialization helps gradient flow
self.d_bn1 = batch_norm(name='d_bn1')
self.d_bn2 = batch_norm(name='d_bn2')
if not self.y_dim:
self.d_bn3 = batch_norm(name='d_bn3')
self.g_bn0 = batch_norm(name='g_bn0')
self.g_bn1 = batch_norm(name='g_bn1')
self.g_bn2 = batch_norm(name='g_bn2')
if not self.y_dim:
self.g_bn3 = batch_norm(name='g_bn3')
self.dataset_name = dataset_name
self.input_fname_pattern = input_fname_pattern
self.checkpoint_dir = checkpoint_dir
self.data_dir = data_dir
if self.dataset_name == 'mnist':
self.data_X, self.data_y = self.load_mnist()
self.c_dim = self.data_X[0].shape[-1]
else:
# dir *.jpg
self.data = glob(os.path.join(self.data_dir, self.dataset_name, self.input_fname_pattern))
imreadImg = imread(self.data[0])
if len(imreadImg.shape) >= 3: #check if image is a non-grayscale image by checking channel number
self.c_dim = imread(self.data[0]).shape[-1] # color image,get image channel
else:
self.c_dim = 1
self.grayscale = (self.c_dim == 1) # 是否是灰度图像
self.build_model()
def build_model(self):
if self.y_dim:
self.y = tf.placeholder(tf.float32, [self.batch_size, self.y_dim], name='y')
else:
self.y = None
if self.crop:
image_dims = [self.output_height, self.output_width, self.c_dim]
else:
image_dims = [self.input_height, self.input_width, self.c_dim]
# self.inputs shape:(batch_size,height,width,channel)
self.inputs = tf.placeholder(
tf.float32, [self.batch_size] + image_dims, name='real_images')
inputs = self.inputs
self.z = tf.placeholder(
tf.float32, [None, self.z_dim], name='z')
# 直方图可视化
self.z_sum = histogram_summary("z", self.z)
self.G = self.generator(self.z, self.y)
self.D, self.D_logits = self.discriminator(inputs, self.y, reuse=False)
self.sampler = self.sampler(self.z, self.y)
self.D_, self.D_logits_ = self.discriminator(self.G, self.y, reuse=True)
self.d_sum = histogram_summary("d", self.D)
self.d__sum = histogram_summary("d_", self.D_)
self.G_sum = image_summary("G", self.G)
def sigmoid_cross_entropy_with_logits(x, y):
try:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
except:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, targets=y)
self.d_loss_real = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
# scalar_summary:Outputs a `Summary` protocol buffer containing a single scalar value
# 返回一个scalar
self.d_loss_real_sum = scalar_summary("d_loss_real", self.d_loss_real)
self.d_loss_fake_sum = scalar_summary("d_loss_fake", self.d_loss_fake)
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss_sum = scalar_summary("g_loss", self.g_loss)
self.d_loss_sum = scalar_summary("d_loss", self.d_loss)
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'd_' in var.name] # 鉴别器相关变量
self.g_vars = [var for var in t_vars if 'g_' in var.name] # 生成器相关变量
self.saver = tf.train.Saver()
def train(self, config):
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
self.g_sum = merge_summary([self.z_sum, self.d__sum,
self.G_sum, self.d_loss_fake_sum, self.g_loss_sum])
self.d_sum = merge_summary(
[self.z_sum, self.d_sum, self.d_loss_real_sum, self.d_loss_sum])
self.writer = SummaryWriter("./logs", self.sess.graph)
sample_z = np.random.uniform(-1, 1, size=(self.sample_num , self.z_dim))
if config.dataset == 'mnist':
sample_inputs = self.data_X[0:self.sample_num]
sample_labels = self.data_y[0:self.sample_num]
else:
# self.data is like:["0.jpg","1.jpg",...]
sample_files = self.data[0:self.sample_num]
sample = [
# get_image返回的是取值为(-1,1)的,shape为(resize_height,resize_width)的
# ndarray
get_image(sample_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for sample_file in sample_files]
if (self.grayscale):
# 灰度图像的channel为1
sample_inputs = np.array(sample).astype(np.float32)[:, :, :, None]
else:
# color image
sample_inputs = np.array(sample).astype(np.float32)
counter = 1
start_time = time.time()
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
if could_load:
counter = checkpoint_counter
print(" [*] Load SUCCESS")
else:
print(" [!] Load failed...")
for epoch in xrange(config.epoch):
if config.dataset == 'mnist':
batch_idxs = min(len(self.data_X), config.train_size) // config.batch_size
else:
# self.data is like:["0.jpg","1.jpg",...]
self.data = glob(os.path.join(
config.data_dir, config.dataset, self.input_fname_pattern))
batch_idxs = min(len(self.data), config.train_size) // config.batch_size
for idx in xrange(0, batch_idxs):
if config.dataset == 'mnist':
batch_images = self.data_X[idx*config.batch_size:(idx+1)*config.batch_size]
batch_labels = self.data_y[idx*config.batch_size:(idx+1)*config.batch_size]
else:
batch_files = self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch = [
get_image(batch_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for batch_file in batch_files]
if self.grayscale:
# add a channel for grayscale
# batch_images shape:(batch,height,width,channel)
batch_images = np.array(batch).astype(np.float32)[:, :, :, None]
else:
batch_images = np.array(batch).astype(np.float32)
# add noise
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \
.astype(np.float32)
if config.dataset == 'mnist':
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={
self.inputs: batch_images,
self.z: batch_z,
self.y:batch_labels,
})
# 用于可视化
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z, self.y:batch_labels })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({
self.z: batch_z,
self.y:batch_labels
})
errD_real = self.d_loss_real.eval({
self.inputs: batch_images,
self.y:batch_labels
})
errG = self.g_loss.eval({
self.z: batch_z,
self.y: batch_labels
})
else:
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.inputs: batch_images, self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({ self.inputs: batch_images })
errG = self.g_loss.eval({self.z: batch_z})
counter += 1
print("Epoch: [%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (epoch, config.epoch, idx, batch_idxs,
time.time() - start_time, errD_fake+errD_real, errG))
# np.mod:Return element-wise remainder of division.
# 每100次生成一次samples
if np.mod(counter, config.print_every) == 1:
if config.dataset == 'mnist':
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
self.y:sample_labels,
}
)
# 保存生成的样本
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
else:
try:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
except:
print("one pic error!...")
# 每500次保存一下checkpoint
if np.mod(counter, config.checkpoint_every) == 2: # save checkpoint file
self.save(config.checkpoint_dir, counter)
def discriminator(self, image, y=None, reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
if not self.y_dim:
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [self.batch_size, -1]), 1, 'd_h4_lin')
return tf.nn.sigmoid(h4), h4
else:
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
x = conv_cond_concat(image, yb)
h0 = lrelu(conv2d(x, self.c_dim + self.y_dim, name='d_h0_conv'))
h0 = conv_cond_concat(h0, yb)
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim + self.y_dim, name='d_h1_conv')))
h1 = tf.reshape(h1, [self.batch_size, -1])
h1 = concat([h1, y], 1)
h2 = lrelu(self.d_bn2(linear(h1, self.dfc_dim, 'd_h2_lin')))
h2 = concat([h2, y], 1)
h3 = linear(h2, 1, 'd_h3_lin')
return tf.nn.sigmoid(h3), h3
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
# 2 is stride
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = deconv2d(
h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = deconv2d(
h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = deconv2d(
h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.expand_dims(tf.expand_dims(y, 1),2)
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(
self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin')))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin')))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(deconv2d(h1,
[self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2')))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(
deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def sampler(self, z, y=None): # 采样测试
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
if not self.y_dim: # generator
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
h0 = tf.reshape(
linear(z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin'),
[-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(h0, train=False))
h1 = deconv2d(h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1')
h1 = tf.nn.relu(self.g_bn1(h1, train=False))
h2 = deconv2d(h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2')
h2 = tf.nn.relu(self.g_bn2(h2, train=False))
h3 = deconv2d(h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3')
h3 = tf.nn.relu(self.g_bn3(h3, train=False))
h4 = deconv2d(h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4')
return tf.nn.tanh(h4)
else: # discriminator
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.reshape(y, [-1, 1, 1, self.y_dim])
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin'), train=False))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin'), train=False))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(
deconv2d(h1, [self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2'), train=False))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def load_mnist(self):
data_dir = os.path.join(self.data_dir, self.dataset_name)
fd = open(os.path.join(data_dir,'train-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trX = loaded[16:].reshape((60000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'train-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trY = loaded[8:].reshape((60000)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teX = loaded[16:].reshape((10000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teY = loaded[8:].reshape((10000)).astype(np.float)
trY = np.asarray(trY)
teY = np.asarray(teY)
X = np.concatenate((trX, teX), axis=0)
y = np.concatenate((trY, teY), axis=0).astype(np.int)
seed = 547
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(y)
y_vec = np.zeros((len(y), self.y_dim), dtype=np.float)
for i, label in enumerate(y):
y_vec[i,y[i]] = 1.0
return X/255.,y_vec
@property # 可以当属性来用
def model_dir(self):
return "{}_{}_{}_{}".format(
self.dataset_name, self.batch_size,
self.output_height, self.output_width)
def save(self, checkpoint_dir, step):
# save checkpoint files
model_name = "DCGAN.model"
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess,
os.path.join(checkpoint_dir, model_name),
global_step=step)
# load checkpoints file
def load(self, checkpoint_dir):
import re
print(" [*] Reading checkpoints...")
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
#A CheckpointState if the state was available, None
# otherwise
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
# basename:Returns the final component of a pathname
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
counter = int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0- from _future_ import division 这句话当python的版本为2.x时生效,可以让两个整数数字相除的结果返回一个浮点数(在python2中默认是整数,python3默认为浮点数)。glob可以以简单的正则表达式筛选的方式返回某个文件夹下符合要求的文件名列表。
- DCGAN的构造方法除了设置一大堆的属性之外,还要注意区分dataset是否是mnist,因为mnist是灰度图像,所以应该设置channel = 1( self.c_dim = 1 ),如果是彩色图像,则 self.c_dim = 3 or self.c_dim = 4 。然后就是build_model。
- self.generator 用于构造生成器; self.discriminator 用于构造鉴别器; self.sampler 用于随机采样(用于生成样本)。这里需要注意的是, self.y 只有当dataset是mnist的时候才不为None,不是mnist的情况下,只需要 self.z 即可生成samples。
- sigmoid_cross_entropy_with_logits 函数被重新定义了,是为了兼容不同版本的tensorflow。该函数首先使用sigmoid activation,然后计算cross-entropy loss。
- self.g_loss 是生成器损失; self.d_loss_real 是真实图片的鉴别器损失; self.d_loss_fake 是虚假图片(由生成器生成的fake images)的损失; self.d_loss 是总的鉴别器损失。
- 这里的 histogram_summary 和 scalar_summary 是为了在后续在tensorboard中对各个损失函数进行可视化。
- tf.trainable_variables() 可以获取model的全部可训练参数,由于我们在定义生成器和鉴别器变量的时候使用了不同的name,因此我们可以通过variable的name来获取得到self.d_vars(鉴别器相关变量),self.g_vars(生成器相关变量)。 self.saver = tf.train.Saver() 用于保存训练好的模型参数到checkpoint。
- train 函数是核心的训练函数。这里optimizer和DCGAN的原文保持一直,选用Adam优化函数, lr=0.0002 , beta1=0.5 。 merge_summary 函数和 SummaryWriter 用于构建summary,在tensorboard中显示。
- sample_z 是从[-1,1]的均匀分布产生的。如果dataset是mnist,则可以直接读取sample_inputs和sample_labels。否则需要手动逐个处理图像, get_image
返回的是取值为(-1,1)的,shape为(resize_height,resize_width)的ndarray。如果处理的图像是灰度图像,则需要再增加一个dim,表示图像的channel=1,对应的代码是 sample_inputs = np.array(sample).astype(np.float32)[:, :, :, None] 。 - 接下来通过 self.sess.run([d_optim,... 和 self.sess.run([g_optim,...) 来更新鉴别器和生成器。 self.writer.add_summary(summary_str, counter) 增加summary到writer。由于同样的原因,这里仍然需要区分mnist和其他的数据集,所以计算最优化函数的过程需要一个if和一个else。
- np.mod(counter, config.print_every) == 1 表示每print_every次生成一次samples; np.mod(counter, config.checkpoint_every) == 2 表示每checkpoint_every次保存一下checkpoint file。
- 下面是discriminator(鉴别器)的具体实现。首先鉴别器使用conv(卷积)操作,激活函数使用leaky-relu,每一个layer需要使用batch normalization。tensorflow的batch normalization使用 tf.contrib.layers.batch_norm 实现。如果不是mnist,则第一层使用leaky-relu+conv2d,后面三层都使用conv2d+BN+leaky-relu,最后加上一个one hidden unit的linear layer,再送入sigmoid函数即可;如果是mnist,则 yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim]) 首先给y增加两维,以便可以和image连接起来,这里实际上是使用了conditional GAN(条件GAN)的思想。 x = conv_cond_concat(image, yb) 得到condition和image合并之后的结果,然后 h0 = lrelu(conv2d(x, self.c_dim + self.y_dim, name='d_h0_conv')) 进行卷积操作。第二次进行conv2d+leaky-relu+concat操作。第三次进行conv2d+BN+leaky-relu+reshape+concat操作。第四次进行linear+BN+leaky-relu+concat操作。最后同样是linear+sigmoid操作。
- 下面是generator(生成器)的具体实现。和discriminator不同的是,generator需要使用deconv(反卷积)以及relu 激活函数。generator的结构是:1.如果不是mnist:linear+reshape+BN+relu---->(deconv+BN+relu)x3 ---->deconv+tanh;2.如果是mnist,则除了需要考虑输入z之外,还需要考虑label y,即需要将z和y连接起来(Conditional GAN),具体的结构是:reshape+concat---->linear+BN+relu+concat---->linear+BN+relu+reshape+concat---->deconv+BN+relu+concat---->deconv+sigmoid。注意的最后的激活函数没有采用通常的tanh,而是采用了sigmoid(其输出会直接映射到0-1之间)。
- sampler函数是采样函数,用于生成样本送入当前训练的生成器,查看训练效果。其逻辑和generator函数基本类似,也是需要区分是否是mnist,二者需要采用不同的结构。不是mnist时,y=None即可;否则mnist还需要考虑y。
- load_mnist 函数用于加载mnist数据集; save 函数用于保存checkpoint; load 函数用于加载checkpoint。
2.4 ops.py
ops.py代码如下:
import math
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
from utils import *
try:
image_summary = tf.image_summary
scalar_summary = tf.scalar_summary
histogram_summary = tf.histogram_summary
merge_summary = tf.merge_summary
SummaryWriter = tf.train.SummaryWriter
except:
image_summary = tf.summary.image
scalar_summary = tf.summary.scalar
histogram_summary = tf.summary.histogram
merge_summary = tf.summary.merge
SummaryWriter = tf.summary.FileWriter
if "concat_v2" in dir(tf):
def concat(tensors, axis, *args, **kwargs):
return tf.concat_v2(tensors, axis, *args, **kwargs)
else:
def concat(tensors, axis, *args, **kwargs):
return tf.concat(tensors, axis, *args, **kwargs)
class batch_norm(object):
def __init__(self, epsilon=1e-5, momentum = 0.9, name="batch_norm"):
with tf.variable_scope(name):
self.epsilon = epsilon
self.momentum = momentum
self.name = name
# 定义了class 的__call__ 方法,可以把类像函数一样调用
def __call__(self, x, train=True):
return tf.contrib.layers.batch_norm(x,
decay=self.momentum,
updates_collections=None,
epsilon=self.epsilon,
scale=True,
is_training=train,
scope=self.name)
def conv_cond_concat(x, y):
"""Concatenate conditioning vector on feature map axis."""
x_shapes = x.get_shape()
y_shapes = y.get_shape()
# 沿axis = 3(最后一个维度连接)
return concat([
x, y*tf.ones([x_shapes[0], x_shapes[1], x_shapes[2], y_shapes[3]])], 3)
def conv2d(input_, output_dim,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="conv2d"):
with tf.variable_scope(name):
w = tf.get_variable('w', [k_h, k_w, input_.get_shape()[-1], output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.conv2d(input_, w, strides=[1, d_h, d_w, 1], padding='SAME')
biases = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
conv = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape())
return conv
# 做一个反卷积操作,tf.nn.conv2d_transpose
def deconv2d(input_, output_shape,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="deconv2d", with_w=False):
with tf.variable_scope(name):
# filter : [height, width, output_channels, in_channels]
w = tf.get_variable('w', [k_h, k_w, output_shape[-1], input_.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
try:
deconv = tf.nn.conv2d_transpose(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
# Support for verisons of TensorFlow before 0.7.0
except AttributeError:
deconv = tf.nn.deconv2d(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
biases = tf.get_variable('biases', [output_shape[-1]], initializer=tf.constant_initializer(0.0))
deconv = tf.reshape(tf.nn.bias_add(deconv, biases), deconv.get_shape())
if with_w:
return deconv, w, biases
else:
return deconv
# leaky relu
def lrelu(x, leak=0.2, name="lrelu"):
return tf.maximum(x, leak*x)
def linear(input_, output_size, scope=None, stddev=0.02, bias_start=0.0, with_w=False):
# 本质其实就是做了一个matmul....
shape = input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
matrix = tf.get_variable("Matrix", [shape[1], output_size], tf.float32,
tf.random_normal_initializer(stddev=stddev))
bias = tf.get_variable("bias", [output_size],
initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_, matrix) + bias, matrix, bias
else:
return tf.matmul(input_, matrix) + bias- 第9行到第20行的代码是为了保持tf0.x和tf1.x版本的兼容性。tf0.x版本使用tf.xxx_summary风格的函数,而tf1.x版本则使用tf.summary.xxx风格的函数。为了保持一致性,通过重命名统一成tf.xxx_summary风格了。
- 22行到27行重新定义了concat函数,也是为了兼容性考虑, if "concat_v2" in dir(tf): 这句话是说如果tf有concat_v2这个方法的话,tf0.x中使用concat_v2函数,而tf1.x版本中使用concat函数。
- 29行到44行定义了batch_norm类。需要注意的是37-44行定义了类的__call__特殊方法,这个方法的作用是可以将类像普通的函数那样直接调用,而不用先构造一个对象再调用方法,这是常用的一个技巧。tf中的batch normalization 是函数 tf.contrib.layers.batch_norm
- conv_cond_concat函数的作用是将conv(卷积)和cond(条件)concat起来。在mnist的generator和discriminator中会用到。
- 54行到65行的conv2d函数重新定义了卷积操作,主要是封装了 tf.nn.conv2d 函数。
- 68行到91行定义了deconv2d(反卷积)函数。tf0.x的反卷积函数为 tf.nn.deconv2d ,tf1.x的反卷积函数为 tf.nn.conv2d_transpose 。最后还加上了一个bias( tf.nn.bias_add )。
- 94到95行定义了leaky-relu函数lrelu。其实就一行代码: tf.maximum(x, leak*x) 。
- 97行到109行定义了linear函数,其实就是一个fully_connected layer。
2.5 utils.py
utils.py代码如下:
"""
Some codes from https://github.com/Newmu/dcgan_code
"""
from __future__ import division
from glob import glob
from os.path import join,basename,exists
from os import makedirs
import math
import json
import random
import pprint
import scipy.misc
import numpy as np
from time import gmtime, strftime
from six.moves import xrange
import tensorflow as tf
import tensorflow.contrib.slim as slim
pp = pprint.PrettyPrinter()
get_stddev = lambda x, k_h, k_w: 1/math.sqrt(k_w*k_h*x.get_shape()[-1])
def show_all_variables():
model_vars = tf.trainable_variables()
# Prints the names and shapes of the variables
slim.model_analyzer.analyze_vars(model_vars, print_info=True)
def get_image(image_path, input_height, input_width,
resize_height=64, resize_width=64,
crop=True, grayscale=False):
image = imread(image_path, grayscale)
return transform(image, input_height, input_width,
resize_height, resize_width, crop)
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def imread(path, grayscale = False):
if (grayscale):
return scipy.misc.imread(path, flatten = True).astype(np.float)
else:
return scipy.misc.imread(path).astype(np.float)
def merge_images(images, size):
return inverse_transform(images)
def merge(images, size):
# samples 图片的真实高和宽
h, w = images.shape[1], images.shape[2]
# 图片channel的有效值只能是3或者4
if (images.shape[3] in (3,4)):
c = images.shape[3]
# img是合并之后的大图片,图片宽和高都倍增了
img = np.zeros((h * size[0], w * size[1], c))
# 遍历每一张图片
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
# 依次向大图填充小图(按行填充)
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3]==1:
# drop channel
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:,:,0]
return img
else:
raise ValueError('in merge(images,size) images parameter '
'must have dimensions: HxW or HxWx3 or HxWx4')
def imsave(images, size, path):
'''
modified imsave
:param images: ndarray,shape:(batch,height,width,channel)
:param size: (row images num,col images num)
:param path: save path
:return:
'''
# np.squeeze:去除维度为1的维
image = np.squeeze(merge(images, size))
return scipy.misc.imsave(path, image)
def center_crop(x, crop_h, crop_w,
resize_h=64, resize_w=64):
'''
对图像进行中心化crop处理
:param x: image ndarray
:param crop_h: input height
:param crop_w: input width
:param resize_h: resize height
:param resize_w: resize width
:return: resized image
'''
if crop_w is None:
crop_w = crop_h
h, w = x.shape[:2]
j = int(round((h - crop_h)/2.))
i = int(round((w - crop_w)/2.))
return scipy.misc.imresize(
x[j:j+crop_h, i:i+crop_w], [resize_h, resize_w])
def transform(image, input_height, input_width,
resize_height=64, resize_width=64, crop=True):
'''
对图像进行转化处理
:param image: ndarray of image
:param input_height: image height
:param input_width: image width
:param resize_height: height after resize
:param resize_width: width after resize
:param crop: if to crop or not
:return:
'''
if crop:
cropped_image = center_crop(
image, input_height, input_width,
resize_height, resize_width)
else:
# 直接resize
cropped_image = scipy.misc.imresize(image, [resize_height, resize_width])
# 将(0,255)映射到(-1,1)
return np.array(cropped_image)/127.5 - 1.
def inverse_transform(images):
# (-1,1) ---> (0,1)
return (images+1.)/2.
def to_json(output_path, *layers):
with open(output_path, "w") as layer_f:
lines = ""
for w, b, bn in layers:
layer_idx = w.name.split('/')[0].split('h')[1]
B = b.eval()
if "lin/" in w.name:
W = w.eval()
depth = W.shape[1]
else:
W = np.rollaxis(w.eval(), 2, 0)
depth = W.shape[0]
biases = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(B)]}
if bn != None:
gamma = bn.gamma.eval()
beta = bn.beta.eval()
gamma = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(gamma)]}
beta = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(beta)]}
else:
gamma = {"sy": 1, "sx": 1, "depth": 0, "w": []}
beta = {"sy": 1, "sx": 1, "depth": 0, "w": []}
if "lin/" in w.name:
fs = []
for w in W.T:
fs.append({"sy": 1, "sx": 1, "depth": W.shape[0], "w": ['%.2f' % elem for elem in list(w)]})
lines += """
var layer_%s = {
"layer_type": "fc",
"sy": 1, "sx": 1,
"out_sx": 1, "out_sy": 1,
"stride": 1, "pad": 0,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx.split('_')[0], W.shape[1], W.shape[0], biases, gamma, beta, fs)
else:
fs = []
for w_ in W:
fs.append({"sy": 5, "sx": 5, "depth": W.shape[3], "w": ['%.2f' % elem for elem in list(w_.flatten())]})
lines += """
var layer_%s = {
"layer_type": "deconv",
"sy": 5, "sx": 5,
"out_sx": %s, "out_sy": %s,
"stride": 2, "pad": 1,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx, 2**(int(layer_idx)+2), 2**(int(layer_idx)+2),
W.shape[0], W.shape[3], biases, gamma, beta, fs)
layer_f.write(" ".join(lines.replace("'","").split()))
def make_gif(images, fname, duration=2, true_image=False):
# 生成gif图
# duration:持续时间
# images shape:(batch_size,height,width,channel)
import moviepy.editor as mpy
def make_frame(t):
try:
# x 代表是t时刻选取的帧图片
x = images[int(len(images)/duration*t)]
except:
x = images[-1]
if true_image: # 返回不经过处理的ndarray,元素值是(-1,1)之间
return x.astype(np.uint8)
else:
# (-1,1) ---> (0,255)
return ((x+1)/2*255).astype(np.uint8)
clip = mpy.VideoClip(make_frame, duration=duration)
clip.write_gif(fname, fps = len(images) / duration)
def visualize(sess, dcgan, config, option):
# 用于可视化
image_frame_dim = int(math.ceil(config.batch_size**.5)) # 图片尺寸
if option == 0:
# noise
z_sample = np.random.uniform(-0.5, 0.5, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_%s.png' % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
elif option == 1: # 将samples生成大图
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.random.uniform(-1, 1, size=(config.batch_size , dcgan.z_dim))
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
# y是batch_size个0-9之间的随机数
y = np.random.choice(10, config.batch_size)
save_random_digits(y,image_frame_dim,image_frame_dim,'./%s/test_arange_%s.txt' % (config.sample_dir,idx))
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_arange_%s.png' % (config.sample_dir,idx))
elif option == 2:
values = np.arange(0, 1, 1./config.batch_size)
# idx是随机的
for idx in [random.randint(0, dcgan.z_dim - 1) for _ in xrange(dcgan.z_dim)]:
print(" [*] %d" % idx)
# z_dim:test_images_num
z = np.random.uniform(-0.2, 0.2, size=(dcgan.z_dim))
# np.tile:按照指定的维度将array重复
# z_sample shape:(batch_size,z_dim)
z_sample = np.tile(z, (config.batch_size, 1))
#z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
#save_random_digits(y, image_frame_dim, image_frame_dim, './%s/test_%s.txt' % % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
try:
make_gif(samples, './%s/test_gif_%s.gif' % (config.sample_dir,idx))
except:
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_%s.png' % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
elif option == 3: # 不能是mnist,直接生成gif
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
make_gif(samples, './%s/test_gif_%s.gif' % (config.sample_dir,idx))
elif option == 4:
image_set = []
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample): z[idx] = values[kdx]
image_set.append(sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample}))
#make_gif(image_set[-1], './%s/test_gif_%s.gif' % (config.sample_dir,idx))
# 合成一张大图gif(64张大图)
new_image_set = [merge(np.array([images[idx] for images in image_set]), [10, 10]) \
for idx in range(63, -1, -1)] # 63-0
make_gif(new_image_set, './%s/test_gif_merged.gif' % config.sample_dir, duration=8)
def save_random_digits(arr,height,width,save_path):
'''
将arr中数字保存到文件,按行保存,共有height行,width列
:param arr: ndarray
:param height: 行数
:param width: 列数
:param save_path: 保存文件地址
:return:
'''
with open(save_path,"w") as f:
for i in range(height):
for j in range(width):
if j != width-1:
f.write("%d," % arr[i*width+j])
else:
f.write("%d\n" % arr[i*width+j])
f.close()
def image_manifold_size(num_images):
manifold_h = int(np.floor(np.sqrt(num_images)))
manifold_w = int(np.ceil(np.sqrt(num_images)))
assert manifold_h * manifold_w == num_images
return manifold_h, manifold_w
def resize_imgs(imgs_path,size,save_dir):
'''
将imgs_path文件夹的所有图片都resize到size大小,并重新保存到save_dir
:param imgs_path: 原始图像文件夹地址
:param size: resize之后的图像大小
:param save_dir: resize之后的图像保存地址
:return:
'''
if not exists(save_dir):
makedirs(save_dir)
imgs = glob(imgs_path+"*.jpg")
for i,img in enumerate(imgs,1):
try:
img_arr = scipy.misc.imread(img)
new_img = scipy.misc.imresize(img_arr,size)
scipy.misc.imsave(join(save_dir,basename(img)),new_img)
except Exception as e:
print(e)
if i % 100 == 0:
print("Resize and save %d images!" % i)
print("Resize and save all %d images!" % len(imgs))
# if __name__ == '__main__':
# imgs_path = "data/images/"
# save_dir = "data/lsun_new/"
# size = (108,108)
# resize_imgs(imgs_path,size,save_dir)utils.py定义了很多有用的全局工具函数,可以直接被其他的脚本调用。
- glob库用来list 某一个文件夹下的files;os库用来操作路径和文件夹等;pprint用于美观打印;gtime和strftime有用格式化日期;scipy.misc包含了很多和图像相关的有用的函数。
- 24-27行的show_all_variables函数,调用了 slim.model_analyzer.analyze_vars(vars,print_info) 函数来打印model所有variables的信息。
- 39-43行的imread函数封装了 scipy.misc.imread 函数,该函数参数 flatten = True 表示将color layer 展平成一个single gray-scale layer。
- 48-73行的merge函数用于从一系列小图产生大图,images[0]表示小图的个数,h=images[1]表示小图的高,w = images[2]表示小图的宽,x_h = size[0]表示最终大图height应该扩展的倍数,x_w = size[1]表示最终大图width应该扩展的倍数。该函数最终生成一个高为h*x_h,宽为w*x_w的大图。表示大图的高度方向包含x_h个小图,宽度方向包含x_w个小图。
- 75-85行定义了保存图像的imsave函数。注意 np.squeeze 可以去除数组中维度为1的那些维(降维),与之相反的操作是 np.expand_dims(arr,axis) 函数,可以给指定的axis维度增加一维。
- 87-104行的center_crop函数的作用是中心化剪切处理,同时对图像进行了resize操作。
- 106-126行的transform函数,也是对图像进行center_crop(可选)以及resize操作,只不过它最后将image array的每个元素的取值范围从(0,255)映射到(-1,1),(-1,1)是tanh函数的取值范围。
- 132-193行的to_json函数将各个layers结构保存到json文件,我们不用这个函数,就不细说了。
- 195-215行的make_gif函数可以将生成的序列图像转换为gif图像,这里使用moviepy库来完成这个工作,关于moviepy的介绍和使用,可以参考我之前的一篇文章。
- 217-298行的visualize用于测试阶段生成图像样本,可以是单个jpg格式的图像,也可以是gif图像,还可以是小图拼接成的大图。visualize函数通过option变量的取值(可以取0,1,2,3,4五个值)来控制以五种不同的方式保存结果。
- option=0:这种情况只适用于dataset 不等于mnist的情况,直接将samples merge成一个大图,然后保存即可,其中大图共有batch_size张小图,每行和每列各有ceil(sqrt(batch_size))个;
- option=1:这种情况和option=0类似,只是它考虑到了dataset为mnist的情况,如果是mnist,则会随机生成batch_size个digit labels,然后从generator生成相应的数字,最后拼接成一个大图,这里我自己定义了一个save_random_digits函数用于将每次随机生成的数字保存到txt文件中去,这样后续可以验证生成的数字图像是否是我们希望生成的;
- option=2:这种情况下,不会生成一张大图,而是生成含有batch_size帧的gif图,默认时间是2s,如果生成gif失败,则会生成和option=1一样的大图;
- option=3:不能是mnist数据集,生成和option=2一样的gif。
- option=4:合成一张大图的gif,一共有batch_size个大图,每个大图由z_dim(生成样本数目)个小图组成。
- 300-316行的save_random_digits函数是我自定义的函数,用于将随机数字保存到txt文件;
- 最后326-346行的resize_imgs函数是我自己添加的,作用就是将指定文件夹下的图像resize成指定的大小,这样我们就可以利用自己的数据集训练model了。
3. 代码运行结果(生成图像效果验证)
1. mnist
根据我们上面的解读,运行如下命令即可以使用mnist训练DCGAN:
python3 main.py --dataset=mnist --input_height=28 --output_height=28 --train True
你需要确保main.py目录下的data/mnist文件夹下有已经解压缩的mnist数据文件。由于mnist数据规模不大,所以使用gpu训练大概只需要几十分钟。训练完成之后,训练过程中采样得到的生成图片保存在samples文件夹下,第一次采样和最后一次采样得到图片分别为下图1和图2所示:

图1 mnist训练第一次采样生成图片

图2 mnist训练最后一次采样生成图片
可以看出随着训练的进行,生成的手写数字的质量确实是慢慢提高的。好了,接着利用训练得到的checkpoint来进行test,这里visualize的option参数设置为1,然后运行如下的命令即可以进行测试:
python3 main.py --dataset=mnist --input_height=28 --output_height=28 --train False
测试默认会生成100张合成的大图,我们随机抽取一张,比如第66张吧,其真实的随机数字排列和生成的手写数字如下图3和图4所示:

图3 第66张真实的随机数字排列

可以发现生成的手写数字和真实的数字是完全符合的,通过随机查看其他的生成图片,可以发现基本全部是100%符合的,这说明conditional DCGAN是非常有效的。
2. celebA
celebA数据集比mnist数据集规模要大,有大约20w+的人脸图片,图片是彩色的108*108尺寸。运行下面的命令即可以进行训练:
python3 main.py --dataset celebA --input_height=108 --crop --train True \
--epoch 2 --sample_dir ./celebA_samples --visualize True
注意默认训练采样保存的文件夹是samples文件夹,由于我们已经把mnist的结果保存在那里了,如果继续使用这个文件夹,celebA的结果会把之前的文件覆盖掉。为了避免这样的情况,我们重新设定保存sample的文件夹为celebA_samples文件夹,这个文件夹会在运行过程中自动创建,不需要手动创建。由于celebA的数据集规模较大,我电脑的配置是:ubuntu 16.04,tensorflow1.4.1,cuda8+cudnn6,显卡是nvidia GTX950M,显存4G。在batch_size = 64的情况下,大概1.5s可以训练一个batch,因此如果按照默认配置epoch=25,一个epoch的batch_num = ceil(202602/64)=3166,因此全部训练完大约需要的时间为1.5*3166*25/3600 ≈33h。由于我没有台式机,自己的笔记本不太可能一直训练这么长时间;机房的电脑配置太渣,train不动。所以我只能随便train一下了。我甚至一轮都没有训练完就停下来了。第1个epoch第100个batch生成的图像如下图5所示:

图5 第1个epoch第100个batch生成的图像
第1个epoch第2500个batch生成的图像如下图6所示:

图6 第1个epoch第2500个batch生成的图像
可以发现,虽然都没有完整的训练一个epoch,但是第2500个batch生成的图像效果已经能初步看出人脸的轮廓了,如果你有足够的算力,不妨试着完整训练一下,最后得到的结果应该会相当不错。
接着我们可以利用上面那个只训练了一点点的模型进行测试,测试celebA运行命令:
python3 main.py --dataset celebA --input_height=108 --crop --train False \
--checkpoint_dir ./checkpoint --sample_dir ./celebA_samples
当然你仍然可以通过设定option的值来控制test的输出。下面的图7和图8是生成的gif图(图8由于体积太大已经转为jpg格式),由于训练非常不充分,因此效果不佳,但是仍然有脸部的轮廓:

图7 celebA训练不到一轮生成脸部图像gif(小图)

图8 celebA训练不到一轮生成脸部图像gif(大图)
3. lsun
由于我使用download.py下载的lsun文件体积非常大(46G),而且格式是mdb格式的,不好直接读取。所以我后来从lsun的官网又自己重新下载了一个2G的图像压缩文件,解压缩之后大概有9000张图像,里面的图像种类较多,主要是关于各种自然景观的。由于图像数量不大,而且各个图像风格差异较大,因此不是很适合训练DCGAN(当然也是可以train的),所以我自己就没有实验了。如果大家有兴趣可以自己尝试训练一下看看效果怎么样。
4. beauty_girls
这个是我自己搜集的数据集,看名字就知道是关于美女的啊。大约有2000张美女图,基本上是全身图,原图尺寸较大,而且size不统一,我们需要利用上面提到的utils.py中的resize_imgs函数首先将所有图片resize到相同的尺寸(这里我resize到width和height都是108),然后保存到文件夹beauty_girls,将该文件夹放入data目录下,然后运行如下的命令就可以训练:
python3 main.py --dataset beauty_girls --input_height=108 --crop --train True \
--epoch 500 --sample_dir ./beauty_girls_samples --visualize True \
--print_every 10 --checkpoint_every 240
这一次因为图片数量只有2000,所以我设定要训练500轮,我在晚上睡觉的时候用笔记本跑了一下,这下却翻车了,训练采样得到的图片是这样的:

图9 beauty_girls 从上到下依次训练1轮,66轮,200轮,300轮,500轮生成的图像
可以发现从第1轮到第300轮生成图片的质量是提高的,但是再往后训练,特别是到了最后500轮的时候,图像明显花了,很多小图都是相似的看不懂的模式(也就是论文里说的mode collapse),这说明最多训练到300轮左右模型就已经差不多收敛了,再往后效果可能会更差,也许会发生mode collapse这种现象。这一点和论文最后提到的是一致的。而且可以发现即使是最好的生成图片,质量也不是特别好,这可能主要是与训练样本数太少(只有2000)而且图像风格差异太大引起的。最后,不要问我要原始训练图片,是拿什么图片训练的,你看生成图片难道猜不到么?哈哈哈。
5. girl_face
这个数据集来自知乎网友Best July的文章:用DCGAN生成女朋友,有兴趣大家可以看看这篇文章。该数据集包含了剪切好的8000多张妹子的头像,大小都是96x96的。差不多是下面这种:

数据集大家可以去faces下载,密码:09h9。运行下面的命令即可以开始训练:
python3 main.py --dataset girl_face --input_height=96 --crop --train True \
--epoch 200 --sample_dir ./girl_face --visualize True \
--print_every 30 --checkpoint_every 300
你需要确保将包含图片数据的girl_face文件夹放在data目录下,我们设定训练200轮,全部训练完成估计要5,6个小时。下图11(从上至下)是分别训练1轮,30轮,70轮,100轮,130轮以及170轮时候产生的图像,可以发现随着训练轮数的增加,生成图像的质量是逐渐增加的,大概到100轮左右的时候,其实生成的头像质量已经很不错了(可以发现是美女了),后续个别位置的小图质量有所增加,但是始终有一些小图有一些畸变,不是特别自然。但是总体上来说,生成的图片质量很不错了。

图11 girl_face 训练1轮,30轮,70轮,100轮,130轮以及170轮时候产生的图像(从上至下)
训练完成之后,我们使用训练得到的model进行test,但是其实有一个问题我们之前没有提到,那就是如果训练轮数设定的过多,那么最新的一个checkpoint加载得到的model未必是最优的,最优的可能在中间的某一个epoch。但是原代码只能加载最新的一个checkpoint,所以我们将model.py中的 load 函数修改如下:
# load checkpoints file
def load(self, checkpoint_dir,checkpoint_name = None):
import re
print(" [*] Reading checkpoints...")
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
#A CheckpointState if the state was available, None
# otherwise
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
# basename:Returns the final component of a pathname
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
if checkpoint_name is None:
# 加载最新的checkpoint
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
else:
# 加载指定的而不是最新的checkpoint
self.saver.restore(self.sess, os.path.join(checkpoint_dir, checkpoint_name))
counter = int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
if checkpoint_name is None:
print(" [*] Success to read {}".format(ckpt_name))
else:
print(" [*] Success to read {}".format(checkpoint_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0主要的修改就是增加了一个checkpoint_name参数,用于指定特定的而不是最新的checkpoint file。同时我们增加了一个checkpoint_name命令行参数: flags.DEFINE_string("checkpoint_name",None,"the name of the loaded checkpoint file,default is the lastest checkpoint") 用来指定checkpoint_name参数,默认值是None。
另外还有一个问题就是,在train的时候sample的样本,输入噪声z是服从(-1,1)的均匀分布,而原代码的visualize函数在option=1,2,3,4的时候,sample不是通过(-1,1)的均匀分布采样得到的,经过我的实验,如果在option=1,2,3,4的时候直接用原代码进行test,得到的生成图片几乎都是模糊的。我猜想这是因为test和train的时候的输入采样分布不一致导致的结果。因此我也对utils.py的visualize函数进行了修改如下:
def visualize(sess, dcgan, config, option):
# 用于可视化
image_frame_dim = int(math.ceil(config.batch_size**.5)) # 图片尺寸
if option == -1:
# noise
z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim],
'./%s/test_%s.png' % (config.sample_dir, strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
elif option == 0:
# noise
z_sample = np.random.uniform(-0.5, 0.5, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_%s.png' % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
elif option == 1: # 将samples生成大图
#values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.random.uniform(-1, 1, size=(config.batch_size , dcgan.z_dim))
# for kdx, z in enumerate(z_sample):
# z[idx] = values[kdx]
if config.dataset == "mnist":
# y是batch_size个0-9之间的随机数
y = np.random.choice(10, config.batch_size)
save_random_digits(y,image_frame_dim,image_frame_dim,'./%s/test_arange_%s.txt' % (config.sample_dir,idx))
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_arange_%s.png' % (config.sample_dir,idx))
elif option == 2:
# values = np.arange(0, 1, 1./config.batch_size)
# idx是随机的
# for idx in [random.randint(0, dcgan.z_dim - 1) for _ in xrange(dcgan.z_dim)]:
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
# z_dim:test_images_num
#z = np.random.uniform(-0.2, 0.2, size=(dcgan.z_dim))
# np.tile:按照指定的维度将array重复
# z_sample shape:(batch_size,z_dim)
#z_sample = np.tile(z, (config.batch_size, 1))
#z_sample = np.zeros([config.batch_size, dcgan.z_dim])
# for kdx, z in enumerate(z_sample):
# z[idx] = values[kdx]
z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim))
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
#save_random_digits(y, image_frame_dim, image_frame_dim, './%s/test_%s.txt' % % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
try:
make_gif(samples, './%s/test_gif_%s.gif' % (config.sample_dir,idx),4)
except:
save_images(samples, [image_frame_dim, image_frame_dim], './%s/test_%s.png' % (config.sample_dir,strftime("%Y-%m-%d-%H-%M-%S", gmtime())))
elif option == 3: # 不能是mnist,直接生成gif
# values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
# z_sample = np.zeros([config.batch_size, dcgan.z_dim])
# for kdx, z in enumerate(z_sample):
# z[idx] = values[kdx]
z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
make_gif(samples, './%s/test_gif_%s.gif' % (config.sample_dir,idx),4)
elif option == 4:
image_set = []
# values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
# z_sample = np.zeros([config.batch_size, dcgan.z_dim])
# for kdx, z in enumerate(z_sample): z[idx] = values[kdx]
z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim))
image_set.append(sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample}))
make_gif(image_set[-1], './%s/test_gif_%s.gif' % (config.sample_dir,idx),12)
# 合成一张大图gif(64张大图)
new_image_set = [merge(np.array([images[idx] for images in image_set]), [10, 10]) \
for idx in range(63, -1, -1)] # 63-0
make_gif(new_image_set, './%s/test_gif_merged.gif' % config.sample_dir, duration=8)
elif option == 5:
#保存单个的小图
z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
for i,sample in enumerate(samples):
scipy.misc.imsave("./%s/single_test_%s.png" %(config.sample_dir,i),sample)主要的修改是将所有的采样方式都改为(-1,1)的均匀分布: z_sample = np.random.uniform(-1, 1, size=(config.batch_size, dcgan.z_dim)) 。实验发现,这种方式在test的时候是非常有效的。另外,我保留了option=0的情况不变,增加了option=-1的情况以及option=5的情况。option=5表示将生成的图片按小图保存。下面的几张图展示了test的结果:

图12 girl_face 随机选取的一个test 生成图像大图