一 HTTP协议简介
作为学习前端开发的开始,我们必须搞明白以下几件事
1、什么是互联网
互联网=物理连接介质+互联网协议
2、互联网建立的目的?
数据传输打破地域限制,否则的话,我想获得对方主机上的数据,只能拿着硬盘去对方主机拷贝
3、什么是上网?
用户上网的过程即浏览器向服务端发送请求,然后将服务端主机的文本文件下载到本地显示的过程。而浏览器与服务器之间走的HTTP协议。
我们学习前端开发就是为了编排好一个文本文件存放到服务端主机,然后提供给浏览器下载显示的(浏览器客户端主要有两个功能,一是向服务端发送请求下载指令,二是将接收到的代码数据渲染成用户可以浏览的网页)所以在学习前端开发前,我们必须先研究HTTP协议
本篇文章以前就发布过,被很多技术技术同好多次转载,由于当时文章分类标签使用不当,后来删除了,在一次写这篇文章,一个是回顾以前的内容,而是希望能够更好的理解分享给大家


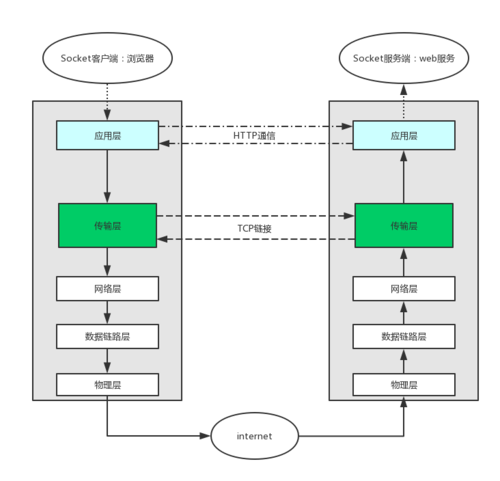
#1、HTTP协议,全称Hyper Text Transfer Protocol(超文本传输协议) HTTP协议是用于从(WWW:World Wide Web,简万维网 )服务器传输超文本到本地浏览器的传送协议。#2、HTTP协议工作于B/S架构上 浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送请求Request。 Web服务器根据接收到的请求后,向客户端发送响应信息Response。#3、HTTP协议是基于TCP/IP通信协议来传递数据的(HTML 文件, 图片文件等),如下图
迄今为止,HTTP协议的发展经历了3个版本的演化
第一个HTTP协议诞生于1989年3月,已过时。 #一:它的组成极其简单:#1、只允许客户端发送GET这一种请求 #2、不支持请求头。 #3、由于没有请求头,造成了HTTP 0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。 #二:无状态性 #1、HTTP 0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。详细解释如下:一次HTTP 0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。 #2、由此可见,HTTP协议的无状态特点在其第一个版本0.9中已经成型。 #三 :HTTP 0.9协议文档:http://www.w3.org/Protocols/HTTP/AsImplemented.html
HTTP/1.0是HTTP协议的第二个版本,至今仍被广泛采用。首次在通讯中指定版本号,相对于HTTP 0.9 增加了如下主要特性: #1、支持请求头与响应头 #2、Response响应以一个响应状态行开始,Response包含的内容不只限于超文本 #3、开始支持客户端通过POST方法向Web服务器提交数据,并支持GET、HEAD、POST方法 #4、支持长连接Keepalive(但默认还是使用短连接) #5、缓存机制以及身份认证
请看下面的介绍,现在主要在用的就是1.1
HTTP 2.0是下一代HTTP协议,目前应用还非常少。 主要特点有: #1、多路复用(二进制分帧)HTTP 2.0最大的特点: 不会改动HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念上一如往常,却能致力于突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。而之所以叫2.0,是在于新增的二进制分帧层。在二进制分帧层上, HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。 HTTP 2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。 #2、头部压缩当一个客户端向相同服务器请求许多资源时,像来自同一个网页的图像,将会有大量的请求看上去几乎同样的,这就需要压缩技术对付这种几乎相同的信息。 #3、随时复位HTTP1.1一个缺点是当HTTP信息有一定长度大小数据传输时,你不能方便地随时停止它,中断TCP连接的代价是昂贵的。使用HTTP2的RST_STREAM将能方便停止一个信息传输,启动新的信息,在不中断连接的情况下提高带宽利用效率。 #4、服务器端推流: Server Push客户端请求一个资源X,服务器端判断也许客户端还需要资源Z,在无需事先询问客户端情况下将资源Z推送到客户端,客户端接受到后,可以缓存起来以备后用。 #5、优先权和依赖每个流都有自己的优先级别,会表明哪个流是最重要的,客户端会指定哪个流是最重要的,有一些依赖参数,这样一个流可以依赖另外一个流。优先级别可以在运行时动态改变,当用户滚动页面时,可以告诉浏览器哪个图像是最重要的,你也可以在一组流中进行优先筛选,能够突然抓住重点流。
HTTP/1.1详解
HTTP/1.1是HTTP协议的第三个版本,是目前主流的HTTP协议版本
HTTP 1.1引入了许多关键性能优化:keepalive连接,请求流水线,chunked编码传输,字节范围请求等
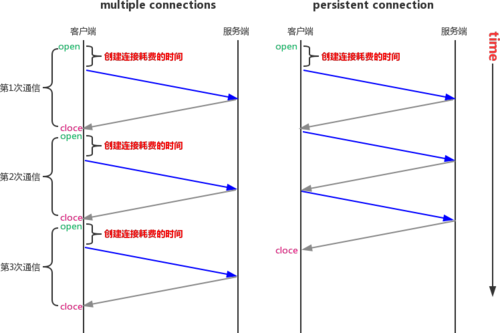
1、Persistent Connection(keepalive连接)
- 允许HTTP设备在事务处理结束之后将TCP连接保持在打开的状态,以便未来的HTTP请求重用现在的连接,直到客户端或服务器端决定将其关闭为止。
- HTTP1.1对比HTTP1.0?在HTTP1.0中使用长连接需要添加请求头 Connection: Keep-Alive,而在HTTP 1.1 所有的连接默认都是长连接,除非特殊声明不支持( HTTP请求报文首部加上Connection: close )
2、Pipelining(请求流水线)
# 请求流水线工作原理 A client that supports persistent connections MAY "pipeline" its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received. 支持持久连接的客户端可以“流水线”它的请求(即,发送多个请求而无需等待每个响应)。服务器必须按照与收到请求的相同顺序来向这些请求发送响应。
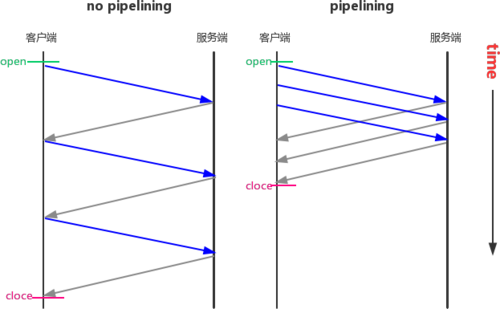
客户端发送请求之后,不需要等收到返回结果,可以直接在发送第二次请求,但是先发送的请求肯定是先收到返回结果,就像是方便工厂的生产流水线,机器上肯定不是一袋方便面在生产制造
3、chunked编码传输
#1、介绍该编码将实体分块传送并逐块标明长度,直到长度为0块表示传输结束, 这在实体长度未知时特别有用(比如由数据库动态产生的数据) #2、传输编码和分块编码当响应头里包含Transfer-Encoding: chunked,代表分块编码,会把「报文」分割成若干个大小已知的块,块之间是紧挨着发送的,这样就不需要在发送之前知道整个报文的大小了,也意味着不需要写回Content-Length首部了。 #3、分块传输的应用当使用持久连接时,在服务器发送主体内容之前,必须计算出主体内容的大小,然后放到响应头里(Content-Length:主体的字节数)发送给客户端。 如果服务器动态创建内容,可能在发送之前无法知道主体大小,分块编码就是为了解决这种情况:服务器把主体逐块发送,说明每一块的大小。服务器再用大小为0的块作为结束块。,为下一个响应做准备,此时响应头里便不再需要Content-Length了 除非使用了分块编码Transfer-Encoding: chunked,否则响应头首部必须使用Content-Length首部。 摘自HTTP/1.1:https://tools.ietf.org/html/rfc2616、 #4、关于Content-Length首部:如果请求头包含Accept-Encoding': 'gzip',则服务端会将内容压缩后返回,内容的Content-Length长度是压缩后的长度,如果请求头不包含Accept-Encoding': 'gzip',服务器就不会采取gzip压缩,同时我司服务器设定也不进行分块编码。所以返回响应头的Content-Length首部是必须的,但是这个值的大小肯定是没有进行过压缩的文件大小。
4、字节范围请求
HTTP1.1支持传送内容的一部分。比方说,当客户端已经有内容的一部分,为了节省带宽,可以只向服务器请求一部分。该功能通过在请求消息中引入了range头域来实现,它允许只请求资源的某个部分。在响应消息中Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码206(Partial Content)
HTTP 1.1还新增了如下特性:
#1、请求消息和响应消息都应支持Host头域在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。因此,Host头的引入就很有必要了。 #2、新增了一批Request methodHTTP1.1增加了OPTIONS,PUT, DELETE, TRACE, CONNECT方法 #3、缓存处理HTTP/1.1在1.0的基础上加入了一些cache的新特性,引入了实体标签,一般被称为e-tags,新增更为强大的Cache-Control头。
二 HTTP协议之请求Request
1、请求的URL
#1、什么是URL?URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息 URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。 #2、以下面这个URL为例,介绍下普通URL的各部分组成:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1 #name一个完整的URL包括以下几部分: #A.协议部分:http://该URL的协议部分为“http:”,在"HTTP"后面的“//”为分隔符。这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等。===>如果不写,浏览器会自动补全,但必须有 #B.域名部分:www.aspxfans.com一个URL中,也可以使用IP地址作为域名使用===>必须有 #C.端口部分:8080跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。===>端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口80 #D.虚拟目录部分:/news/从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。===>虚拟目录也不是一个URL必须的部分。 #E.文件名部分:index.asp从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。===>文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名 #F.参数部分:boardID=5&ID=24618&page=1从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。===>参数部分非必须 #G.锚部分:#name从“#”开始到最后,都是锚部分。===>锚部分也不是一个URL必须的部分
URL与URI,URN有什么区别
#1、URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的 URI一般由三部组成: ①访问资源的命名机制 ②存放资源的主机名 ③资源自身的名称,由路径表示,着重强调于资源。 #2、URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。 采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成: ①协议(或称为服务方式) ②存有该资源的主机IP地址(有时也包括端口号) ③主机资源的具体地址。如目录和文件名等 #3、URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com。URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。 在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。 在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。 相反的是,URL类可以打开一个到达资源的流。 # 他们三个的区别有点像是CSS的属性选择器,应该说都是做定位筛选用的,一个是在网页中定位,一个是在全球范围内的资源定位
2、Request请求的格式
客户端发送一个HTTP请求到服务器的请求消息格式为:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
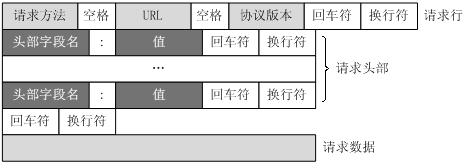
请求行以一个方法GET或POST开头,以空格分开,后面跟着请求的URI和协议的版本。详细解释如下 GET /mayite/p/7278389.html HTTP/1.1Host: www.cnblogs.com Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 #第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.GET说明请求类型为GET/mayite/p/7278389.html为要访问的资源 该行的最后一部分说明使用的是HTTP1.1版本 #第二部分:从第二行起为请求头部,紧接着请求行(即第一行)之后,用来说明服务器要使用的附加信息HOST将指出请求的目的地. User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等 #第三部分:空行,请求头部后面的空行是必须的即使第四部分的请求数据为空,也必须有空行。 #第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。只有POST方法才有请求体,可以用浏览器登录一个网站,输错账号密码来抓取POST请求 POST / HTTP1.1Host:www.wrox.com User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type:application/x-www-form-urlencoded Content-Length:40Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley
3、HTTP请求方法
#1、Http协议定义了很多与服务器交互的方法(了解)HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。 HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。 #2、了解下各个方法的大致意义 GET 请求指定的页面信息,并返回实体主体。 HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 DELETE 请求服务器删除指定的页面。 CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 OPTIONS 允许客户端查看服务器的性能。 TRACE 回显服务器收到的请求,主要用于测试或诊断。 #3、一个URL地址用于描述一个网络上的资源,而HTTP中最基本的四个方法GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 #4、 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
GET请求与POST请求的区别
简单的说法就是get请求会在url上体现出来,而post不会,当然这只是表面上的
#1、区别1: 参数的组织方式不同GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连, 例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。 POST方法是把提交的数据放在HTTP包的Body中. 因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变 #2、区别2:传输数据大小限制首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。 而在实际开发中存在的限制主要有: GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。 因此对于GET提交时,传输数据就会受到URL长度的 限制。 POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。 可以简单总结为: GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。 #3、区别3:安全性POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击
三 HTTP协议之响应Response
服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息Response
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
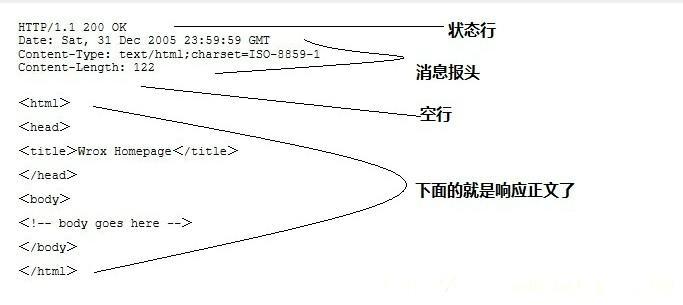
#第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok) #第二部分:消息报头,用来说明客户端要使用的一些附加信息,Date:生成响应的日期和时间; Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8 #第三部分:空行,消息报头后面的空行是必须的 #第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文,浏览器就是会把这部分内容渲染到用户的客户端浏览器,就会产生网页的效果了
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别: 1xx:指示信息--表示请求已接收,继续处理 2xx:成功--表示请求已被成功接收、理解、接受 3xx:重定向--要完成请求必须进行更进一步的操作 4xx:客户端错误--请求有语法错误或请求无法实现 5xx:服务器端错误--服务器未能实现合法的请求 常见状态码: 200 OK //客户端请求成功 400 Bad Request //客户端请求有语法错误,不能被服务器所理解401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden //服务器收到请求,但是拒绝提供服务 404 Not Found //请求资源不存在,eg:输入了错误的URL 500 Internal Server Error //服务器发生不可预期的错误 503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
四 HTTP协议完整工作流程
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
五 HTTP协议关键性总结
#1、简单快速 客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 #2、灵活 HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。 #3、无连接 HTTP无连接说的是:当某个客户机在短时间多次次请求同一个资源,服务器并不能区别是否已经响应过用户的请求。 于是我们每次发送http请求,都需要事先发起一个到服务器的TCP请求,经历“三次握手”的过程。这针对大流量的的服务器来说,开销是相当大的。这是http无链接带来的缺点 针对http无连接,人们设计了非持久连接和持久连接。实际上关于http协议非持久连接和持久连接是针对tcp协议的。当客户机/服务器的交互运行于TCP协议上时,应用程序的每个请求/响应对是经不同的TCP连接时,则该应用程序使用非持久连接,而当应用程序的每个请求/响应对是经相同的TCP连接发送,则该应用程序使用持久连接。 非持久连接 请求一个HTTP请求/响应需要的总时间=客户端发出建立连接+发生请求报文+服务器传输HTML文件的时间 持久连接 服务器在发送响应后,保持该TCP连接打开。在相同的客户机与服务器之间的后续请求和响应报文通过相同的连接进行传送。不需要再次建立tcp连接 #4、无状态 所谓http是无状态协议,言外之意是说http协议没法保存客户机信息, 无状态的优点是: 在服务器不需要先前信息时它的应答就较快。 无状态的缺点是: 缺少状态意味着如果后续处理需要前面的信息,则它必须重传。这样可能导致每次连接传送的数据量增大 关于http无状态阻碍了交互式应用程序的实现。比如记录用户浏览哪些网页、判断用户是否拥有权限访问等。于是,两种用于保持HTTP状态的技术就应运而生了,一个是Cookie,而另一个则是Session。 #5、支持B/S及C/S模式。
六、 自定义套接字分析HTTP协议
import socket server=socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('127.0.0.1',80)) server.listen(5) conn,client_addr=server.accept() request=conn.recv(1024) # print(request) print(request.decode('utf-8')) #字符编码可能会因为浏览器的不同,而乱码 conn.send(b'HTTP/1.1 200 OK\r\n\r\n<h1>hello</h1>') conn.close() server.close()
import socket server=socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('127.0.0.1',8080)) server.listen(5) conn,client_addr=server.accept() request=conn.recv(1024) # print(request) print(request.decode('utf-8')) with open('index.html','rb') as f: data=f.read() conn.send(b'HTTP/1.1 200 OK\r\n\r\n%s' %data) conn.close() server.close()





