写这篇随笔的目的是我发现了在上一篇关于My SQL的随笔中存在一些不严谨的代码问题,在这里再次简单的总结一下并加以改进,以代码为主。
# !每行命令必须以分号(;)结尾
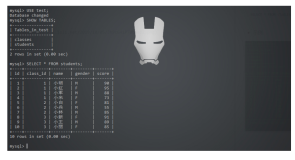
先通过命令行进入数据库客户端
mysql -h服务端ip地址 -P(大写)服务端使用的端口,一般为3306 -p(小写)
回车之后输入密码,进入
显示所有数据库
show databases;
创建数据库并设置编码
- 数据库创建时可以设置字符集以及排序规则
- 字符集一般使用utf8的,排序规则一般使用忽略大小写的,其实也不能说是忽略大小写
- 它的原理是放进数据库的都转换成大写,然后不管用户输入的大写还是小写都转换成大写再去数据库里查
- 所以看起来就相当于是忽略了大小写
- 如果不设置中文会乱码
create database 数据库名字 character set utf8;
create database 数据库名字 charset=utf8;
修改数据库编码
alter database 数据库名字 character set utf8;
展示创建数据库的过程
show create database 数据库名字;
使用某个数据库
use 数据库名字;
判断当前在哪个数据库里
select database();
查看该数据库有哪些表
show tables;
创建数据库中的表
create table 表的名字(
字段名字 类型(范围) [约束],
字段名字 类型(范围) [约束],
字段名字 类型(范围) [约束]);
查看某表的字段(属性)
desc 表的名字;
show create table 表的名字;
往表中添加字段
alter table 表的名字 add 字段名字 类型(范围) [约束];
修改表字段类型
alter table 表名字 modify 字段名字 新类型(范围) [约束];
修改表字段的名字和类型
alter table 表名字 change 旧的字段名字 新的字段名字 新类型(范围) [约束];
给表中的字段添加约束
主键,外键,检查,唯一四个约束要用add constraint,其他的约束可以用modify
alter table 表的名字 add constraint 起个名字(随意) 约束(字段名字);
往表中添加数据
insert into 表的名字(字段名字) values(要添加的数据);
查询表中的数据
select * from 表的名字;
根据范围查询表里的数据
select * from table limit m,n;
- 显示范围是:[m+1行,m+n行],包括m+1和m+n行
根据字段查询表里的数据
select 字段名字1,字段名字2 from 表的名字;
给从表里查询出来的数据的字段取别名
select 字段名字1 as 要取的别名,字段名字2 as 要取的别名 from 表的名字;
根据字段查询表里的数据(去重)
select distinct 字段名字 from 表的名字;
根据条件查询表里的数据(条件可使用not,!=,or,in(值1,值2...),and,between..and..)
select * from 表的名字 where 条件;
模糊查询表里的数据
在根据条件查询的条件中使用like和通配符%(任意字符),_(一个字符)
查询表里的某字段为NULL的值条件必须用is null,不能用= null
对表里的数据排序(先按字段1排,有相同的则再按字段2排)
select * from 表的名字 order by 字段名字1 asc(默认升序)/desc(降序),字段名字2 asc(默认升序)/desc(降序);
修改表中某字段的所有数据
update 要修改的表的名字 set 要修改的字段 = 修改后的内容;
修改表中某字段的指定数据(where 后面是查找条件)
update 要修改的表的名字 set 要修改的字段 = 修改后的内容 where 字段 = 内容;
删除表中的一个字段(这里要注意不能全删光)
alter table 表的名字 drop column 字段名字;
删除表中的数据
truncate 表的名字; (后面不能跟where)
delete from 表的名字;
delete from 表的名字 where 字段名字 = 内容;
删除数据库/表
drop database/table 存在的数据库名字/表的名字;
清屏
system clear
导入导出数据库
导出(终端中): mysqldump -uroot -p 存在的要导出的数据库的名字 > 要导出位置的绝对路径/新名字.sql
导入(终端中): mysql -uroot -p 新数据库的名字 < 路径/要导入的数据库名字.sql
导入(客户端中): 1. 先建一个新的数据库,名字随意
2. use 这个空的数据库
3. source 写要导入的.sql文件的绝对路径