云栖TechDay活动第二十二期中,阿里云ET团队正茂带来了题为《创新业务中的预测分析技术实践》的分享,他主要与大家分享创新业务中的预测分析,并结合具体案例来讲述这些预测技术的具体应用和使用经验。
以下为现场分享观点整理。
机器学习简介

开篇之前,首先介绍一下机器学习。机器学习是人工智能的科学其中的一个方向,这个领域主要解释如何用经验学习来去改善具体算法的性能。机器学习主要分为有监督学习、无监督学习、半监督学习和增强学习四类。
本文所提到的预测技术就是有监督学习,如上图右侧所示;上图的左侧是无监督学习。通俗点讲,有监督的过程就是老师教授知识的过程,让你在脑海中形成一个模型,从而大脑就储存了多个模型并识别。机器学习就是用一些程序让机器自动学习。
增强学习是指机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。与监督学习的区别:增强学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。

为什么需要机器学习呢?按照阿里云的宣传语,就是为了无法计算的价值。这两年人工智能之所以发展这么快:其一,因为廉价的高性能计算以及大规模的存储。以前的计算机基本上是512M内存,而现在标配8G,现在手机的处理器也已经远远超过小学时期PC机的处理性能。像阿里云大规模的集群存储机,上万台机器同时计算,足以表明其高性能计算及大规模存储;其二,目标问题有多种因素来决定。例如4月8号我们预测李汶获得《我是歌手》的冠军,影响她获得冠军的因素可能有上千种,这上千种因素综合决定了其结果。其三就是简单的规则难以处理。如果有多种因素、多种规则糅合在一起,就无法判断,这个时候特别需要机器学习、算法来进行处理。
有监督学习那些事

现在具体分析下监督学习,即预测技术。它是机器学习中的一个方法,由训练资料中学到或建立一个模式。比如刚出生的小孩,学说话,学认知,在自己的大脑中建立一个模式,并且以此模型来推测新的实例。上图可以直观地表示。有监督就是这样一个过程。我们把预测技术中连续的输出值称为回归分析。
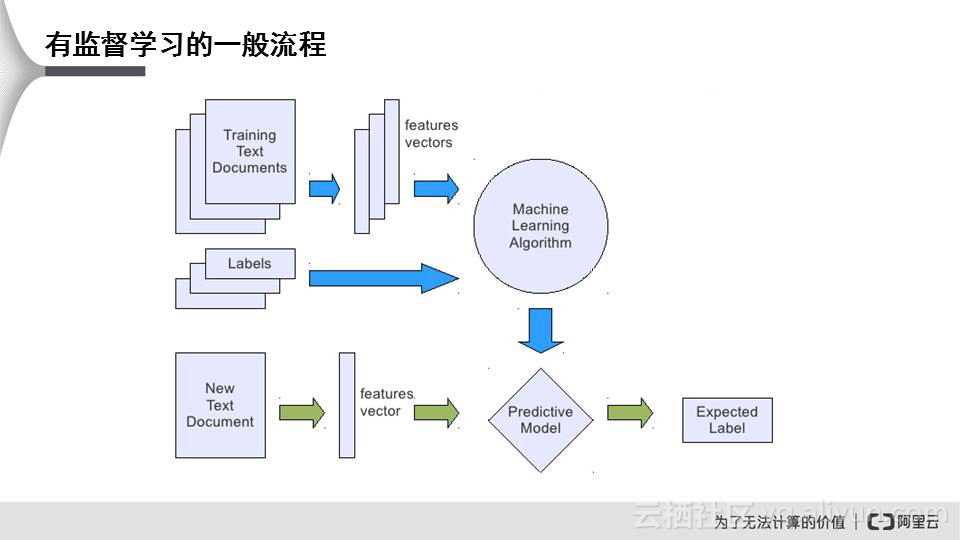
上图是有监督学习的流程,在工业界中,有监督学习是更常见和更有价值的方式,占据机器学习任务的80%。以刚才小朋友学习的例子解释上图。左上角是一个训练集,即训练的资料;下面是类别,特征向量为小孩识别的物体特征,那么我们要用机器把这些特征抽取出来,装到一个算法模型里,其次把特征对应到的东西交给算法,接着算法学习一个模型,把这个模型装在机器的内存里面。如果再来一个新的物体,就通过摄像头把图像的特征向量采集下来,再传到机器内存中,机器内存就会根据已有的模型做一个预测。若模型训练的不好,容易预测错误。
上图中蓝色的箭头是离线过程包含数据筛选和清洗、特征抽取、模型训练和优化模型等环节;绿色箭头为应用流程,对需要预估的数据抽取特征,应用离线训练得到的模型进行预估。现在用一个具体实例解释预测的步骤。比如王菲要在南京开演唱会,预测粉丝购买演唱会门票的意愿。她的代理公司就要考虑南京有多少粉丝,粉丝中有多少人愿意去买票。若预定了一个5万人的体育场,票是800块钱一张,结果来了几千个人,那完全是亏本。
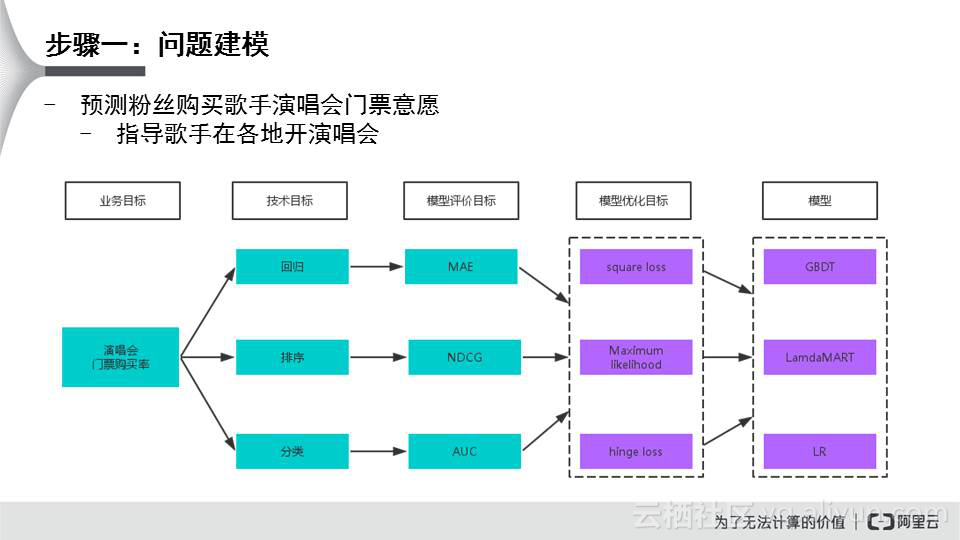
要预测,第一步就是问题建模,把问题转成数学模型。首先把它当成一个业务目标,运营公司的业务目标就是判断王菲的粉丝会不会买演唱会的门票,然后转成一个技术目标;预测里面的技术目标分为回归、排序和分类。买或不买,可以当成一个分类问题;然后考虑这个模型的评价目标,评估模型的好与坏,模型预测的准确率。还要确定一下所建模型的评价指标,紧接着做一些模型的优化指标。

在建模过程当中,我们踩过一些坑。一是业务目标与模型的优化目标不一致,以刚才的演唱会为例,我们预测粉丝会不会买门票,这是一个业务目标,若你用了另外一种分类器或预测技术,数学建模就有问题;二是准备的训练数据以及特征与选择的模型是否相符,准备的训练数据包括买没买过王菲的门票,有没有浏览过王菲周边的商品,有没有听过王菲的歌,每天听多少次,历史上有没有参加过她的演唱会,若演唱会在周日,根据历史信息判断周日是不是有空等;这些都是根据互联网的信息来进行决策,把这些信息一块交给模型来判断。要看准备的训练数据与选择的模型是否一致,基本需要考虑两个问题,训练数据的多与少,高阶特征与低阶特征。高阶特征就是业务经验的特征;低阶就是没有业务经验、直接的特征;三是是否被工业界广泛采用,这个很关键,因为工业界有各种限制,例如模型非常耗时,训练一个模型要跑很久,无法并行化等等。四要考虑是否需要多模型融合。比如我们可以把演唱会门票问题拆成几个子问题分别进行预测,再把这几个子模型融合到一起再预测。

第二步就是准备训练数据。演唱会采用的训练数据,首先就是年龄、性别等粉丝的属性数据,有没有听过她的歌等行为数据,还包括label数据,即有没有在网上买过她的门票,互联网通过服务器把这些行为数据、日志都记录下来,我们再把这些当成标注label。其次就是艺人属性及行为数据。比如说艺人流行不流行,流行的年龄段,歌的风格,花边新闻,关注度,粉丝量,百度指数等;行为数据包括最近的网络曝光率等。第三个就是粉丝和艺人的交互数据,比如听过多少次王菲的歌,一个月下载了几次,有没有参加过粉丝见面会等。以上就是我们要准备的训练数据。
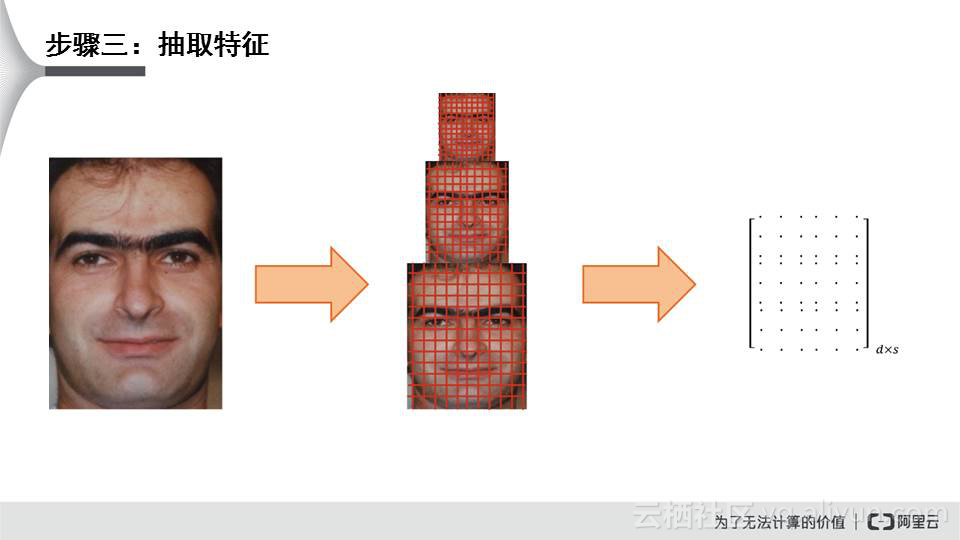
准备训练数据采用三大类的特征。第一类是粉丝自身的特征;第二类是艺人自身的特征;第三类是粉丝与艺人之间的交互关系。采集数据过程中会出现一些坑,首先要保证预测数据与训练数据的分布尽可能一致。比如说训练数据里买演唱会门票的人是1千万,不买的是9千万,就是1:9,然后训练模型出来,拿到业务中心应用,业务中心应用可能真实的数据分布是1:50,那训练集就有问题了。其次,目标变量噪音尽可能少。再次,尽量不要采样,建模之后,准备训练数据,然后开始进行预测。要出具特征,以人脸识别为例,判断一个人是谁,肯定要提取如棱角、眉毛、鼻子、嘴唇、头发等特征,把特征交给大脑。这也就是第三步:抽取特征。

目前大量工作都在做特征,工业界算法工程师基本上自嘲自己是特征处理工程师,这两点都说明了特征有多重要。深度学习技术其实就是一个特征工程。抽取特征过程中踩过的坑主要包括:做这些事情是否借鉴了业务经验,业务经验很关键;是否考虑到了数据的获取规模、难度、准确度、覆盖率等等;缺失值的处理,不可能所有样本都包含某一特征;维度灾难和降维,比如淘宝的首页是千人千面,因为要对用户进行预估,考虑到用户在淘宝上的行为特征,进行降维,这样运行的更快,机器的计算也更快;线行模型还要较多的特征抽取技巧,非线性的模型不需要考虑这么多;六是长尾样本预测主要是受高阶特征的影响,高频样本主要是低阶特征的影响。

特征抽取后,第四步需要训练模型。训练模型是说我们已经抽取到了苹果、梨子的外表,做什么样的模型、用什么样的模型进行训练。模型训练基本思路是:首先选定假设函数和损失函数,基于已有训练数据(x,y),不断调整w,使得损失函数最优,相应的w就是最终学习结果,也就得到相应的模型。目前常用的优化损失函数是批量梯度下降和随机梯度下降,两者的原理都不难,沿着梯度下降最快的方向去学习所需要的参数。
在模型训练过程中,我们采过很多坑,例如是否采用了一个成熟的工具包,例如阿里云的PAI平台、MLib、TensorFlow;此外还有一些常用的模型,如逻辑回归、随机森林、梯度下降树、卷积神经网络;当现有的工具无法满足需求时,需要自主开发模型。目前来看,RF、GBDT是万金油,较少处理特征,经常出现在各大算法竞赛中。
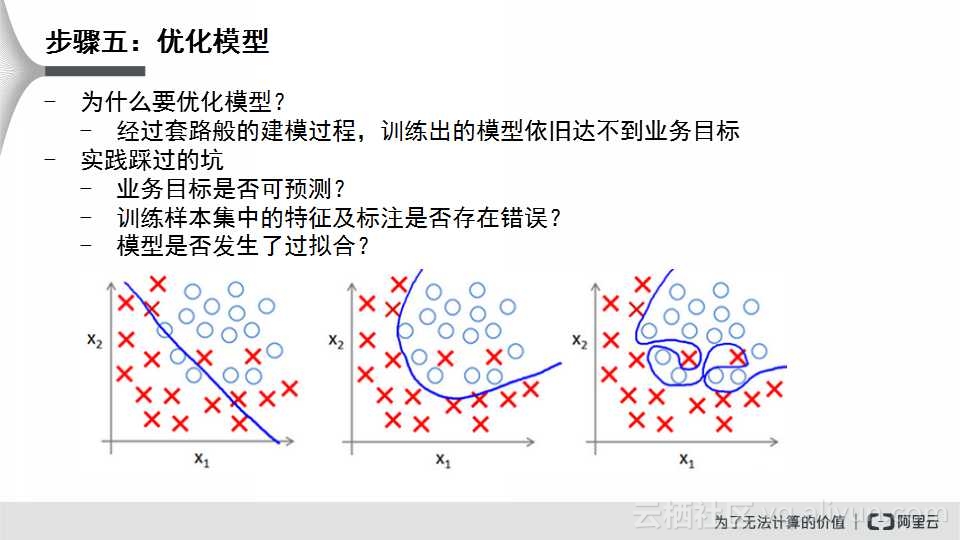
模型训练后,第五步需要优化模型。之所以需要优化模型,是因为经过套路般的建模过程,训练处的模型依旧达不到业务目标,会出现欠拟合(左一)或者过拟合(右一)现象。目前实践中踩过的坑包括:业务目标是否可预测;训练样本集中的特征及标注是否存在错误;模型是否发生了过拟合。

在优化模型中,过拟合与欠拟合一般解决方案如上所示。欠拟合的解决方案就是增加特征,例如在预测是否会买王菲演唱会的门票中们可以增加你是否听过王菲的音乐会或是否有过交互的特征;针对欠拟合的解决方案是,例如已经预测了你是否会买这个门票,比如采用了几十万特征,这种情况容易产生过拟合,这个时候需要进行特征筛选,从100万维特征降维到100维;
然后在模型层次上面,针对过拟合,可以提高正则项的惩罚参数;欠拟合可以采用融合多个模型来提高它的拟合能力。
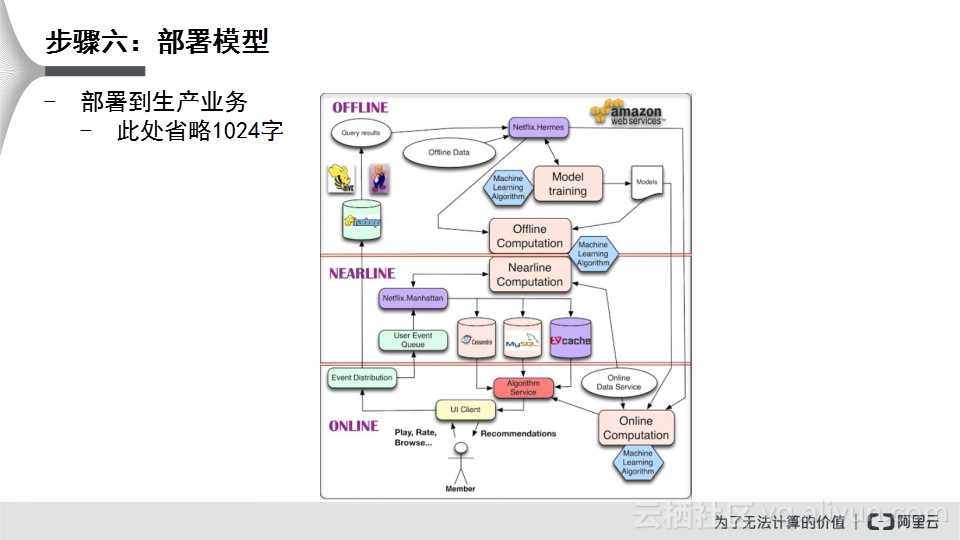
模型训练后,第六步是部署模型,上图右侧是非常典型的部署案例:AWS云服务平台上的案例。
创新业务中预测技术
下面来简单聊一下阿里云创新业务中基本用到的一些预测技术。
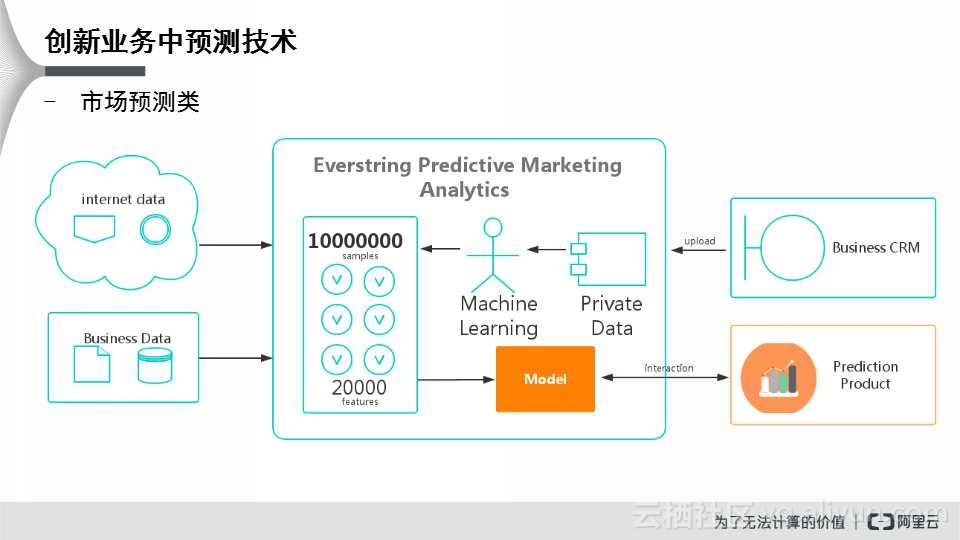
上图是美国一家创业公司提供的市场预测类的图。所谓的市场预测是指:新开一家公司,去预测你是不是我的客户,类似于淘宝上的预测是否会点击上面的图片,每一次点击都要向广告商收取费用。因此市场预测是有其存在的必要性的。
市场预测类的架构图如上所示:在架构的右侧是Business CRM,用于管理客户关系的数据,这其中既有用户的购买数据,又包含从互联网抓取的数据以及通过商业手段买到的数据。将这些数据综合在一起,利用上文提到的技术,将其进行模型训练,最后形成应用,通过产品展示出来。例如,可以给房地产开发商预测客户,比如,某一个楼盘有10万个潜在客户,通过市场预测技术,判断出潜在价值高的客户,进行重点营销,提高转化率。
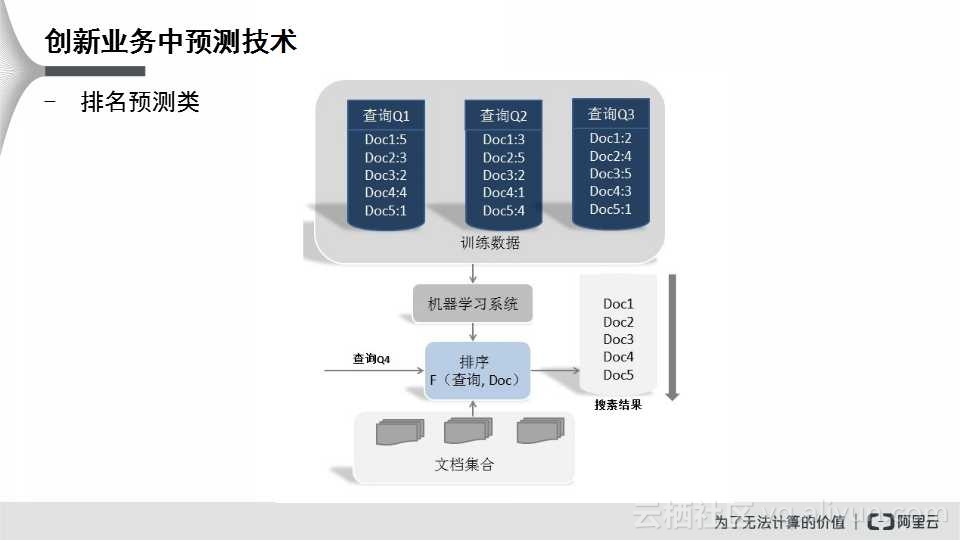
排名预测类也是常见的预测技术之一。上图是常见的Google、百度、搜狗引擎排序的列表。上文所提到的《我是歌手》预测也是一个排序,总共7个选手,需要预测前三名,其中采取了F(查询、Doc)的机器学习排序。
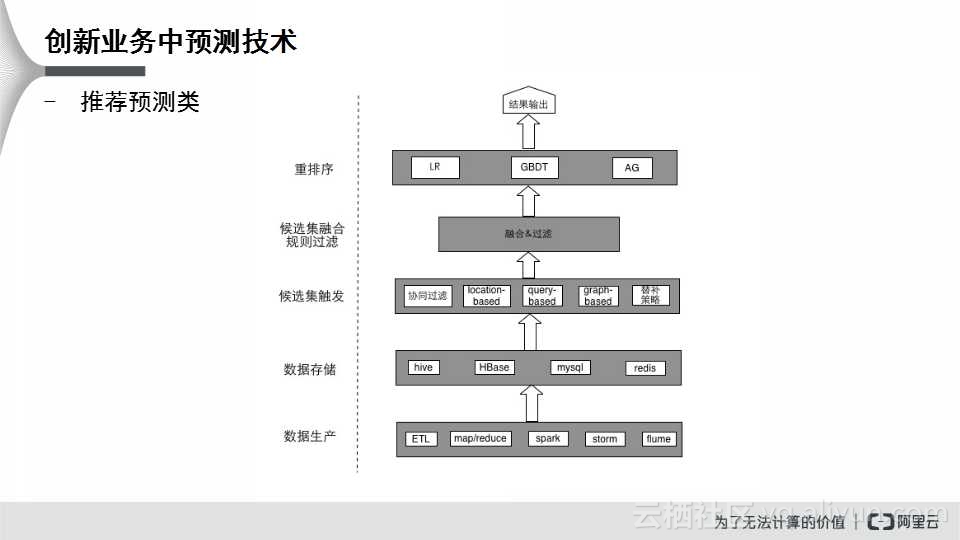
推荐预测类是目前常用的一种预测技术,例如,手淘中的推荐好货、优酷土豆上的推荐电影或者是爱奇艺的个性化推荐,猜你喜欢等等。个性化推荐算法的框架首先是现有数据生产、数据存储;然后再进行一次二次排序,这其中涉及到一些基础的算法,如协同过滤;然后进行一次数据融合;最终在进行一次二次排序,例如刚才提到的GBDT,最终是通过一次排序然后再输出,输出值就是ID。
以上提到的三类预测方式,可以解决很多市场中、业务上面临的问题,这些业务不仅仅是传统推荐、广告、搜索业务,而是将其结合大数据运用到各行各业中,例如工业、交通、旅游,医院等等。

目前在阿里云的创新业务中也应用了很预测技术,主要的应用如上图所示,例如影视投资风控预测,在投资电影时,改不改投,投入多少,这都需要提前去预测的;或者是景区客流量预测,景区流量会不会突然爆发、会不会超出景区承载能力以及踩踏事件产生等,都需要进行事先的预测。
技术成长建议

最后,对于在座的听众提几点建议:如果对大数据预测技术感兴趣,可以多参加一些工业界的大数据大会或论坛,以及一些竞赛,例如阿里举办的天池大赛;另外一方面,因为机器学习,包括预测技术,本身就是数学,是基于数学建模的基础上发展而来,平时需要多看一些经典的数学书籍,顶级会议论文等。