本文根据顾风胜在大流量高并发互联网应用实践在线峰会上题为《海量订单实时同步与处理实践》的分享整理而成。
直播视频:点此进入
PDF下载:点此进入
以下是精彩内容整理:
双十一订单全链路
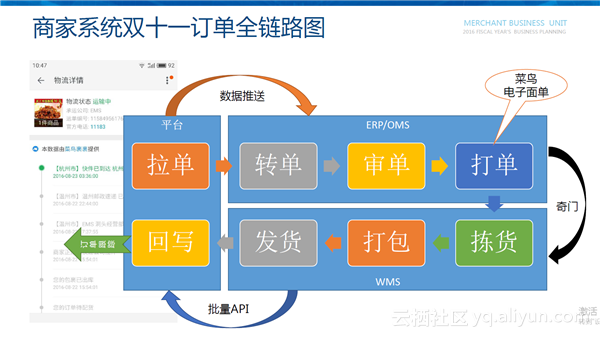
从图中可以看出,整个双十一订单处理过程中主要涉及到三个系统:平台(天猫、淘宝)、ERP/OMS(用来处理订单)、WMS(仓库内的打包、发货)。其中包括了八个状态:拉单可以平台提供的订单API来完成,ERP/OMS进行转单、审单、打单,WMS提供拣货、打包、发货,最后要把状态进行回写。订单回写完成之后,订单状态就会在淘宝订单的物流详情中显示出来。
针对双十一订单的整个链路,接下来主要给大家推荐平台提供的几个产品,让订单同步和处理更加高效:订单同步通过数据推送(订单同步服务)、面单打印通过菜鸟电子面单、仓库对接通过奇门数据总线,订单状态回写通过批量API。
订单同步与处理关键接口
订单同步API:
- taobao.trades.sold.get(获取三个月内已卖出的订单)
- taobao.trades.sold.increment.get(增量获取发生变更的订单)
- taobao.trade.fullinfo.get(获取单笔订单详细信息)
打单面单API:
- taobao.wlb.waybill.i.get(获取电子面单号)
- taobao.tmc.message.produce(订单状态回流)
- taobao.logistics.offline.send(物流发货回写)
传统的订单同步方法
传统的订单同步方法主要分为三个流程。
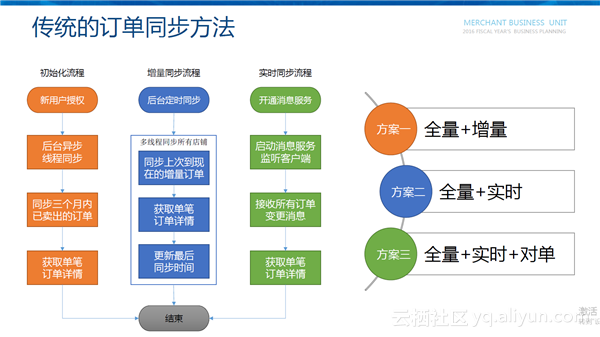
第一个流程是初始化流程,新的用户进来之后需要给其授权,然后后台需要异步启动一个新的线程把订单同步回来,一般最多同步三个月内已卖出的订单,此外还需要调用订单详情接口获取单笔订单详情。
第二个是增量同步流程。订单在不断的产生和变化,需要在后台定时同步增量的订单,所以应该在后台定时起一些异步的线程去同步这个应用里所有已授权用户的增量订单,然后通过订单详情接口获取订单详情,并且把最后的同步时间点存储起来以便下次使用。
第三个是实时同步流程,主要应用于自动发货等实时处理的场景。淘宝开放平台提供了主动通知的消息服务能力。接收到订单变更的实时消息之后,通过订单详情接口,就可以拿到订单详情更新本地数据。
通过这三个流程,我们可以组合出很多方案。第一种是“全量+增量”的方案,可以实现订单的初始化、增量同步,适用于大部分的业务场景;第二种是“全量+实时”的方案,存在的问题是部分订单的变更可能没有发消息,适用于对数据准确性要求不是非常高的实时订单处理场景;第三种是“全量+实时+对单”的方案,可以保证整个订单同步的实时可靠,适用于对数据准确性和实时性要求极高的场景。
高效使用订单同步API
taobao.trades.sold.get(获取三个月内已卖出的订单):使用use_has_next=true的方式分页,每次分页可以减少一次db count,提高API分页查询的效率;对于订单量大的卖家,需要切分时间段,比如按天获取,双十一峰值时段甚至切分到按分钟获取;需要调用taobao.trade.fullinfo.get获取详情的情况下,批量接口设置fields=tid可以直接走DB索引,获得更高的效率。
taobao.trades.sold.increment.get(增量获取变更的订单):不能从前往后翻页,否则已翻页的订单发生变化,会导致后续页数的订单前移,前移订单将会遗漏,正确的做法是从后往前翻页;首次请求使用use_has_next=false获取变更总数,后续请求通过use_has_next=true分页,每次分页可以减少一次db count;需要调用taobao.trade.fullinfo.get获取详情的情况下,批量接口设置fields=tid可以直接走DB索引,获得更高的效率。
常见的漏单原因
- 批量订单查询type入参设置不完整
- 增量同步订单没有从后往前翻页
- 增量同步订单时间片没有重叠
- 增量同步订单没有往前追溯一定的时间(比如5~30分钟)
- 程序简单粗暴,时间片不切分,导致API调用频繁超时
- 订单的部分属性变更并不会发主动通知消息
- 极少数情况下,有一些订单发生了变更,但修改时间没变
更深层次的漏单原因
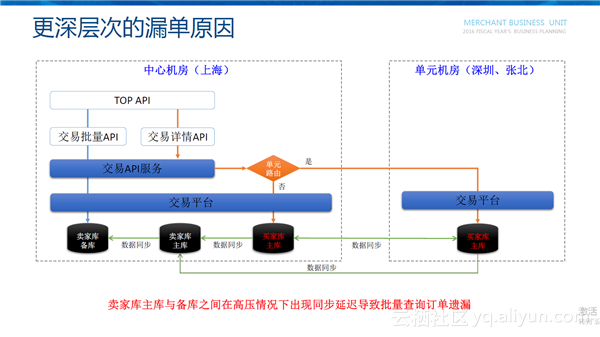
图中是淘宝天猫交易的机房分布,其分为中心机房和单元机房。中心机房放着买家库的主库,单元机房也会同样放买家库的主库。消费者下单后,订单会直接落入买家库里面,中心机房和单元机房会通过DRC进行双向数据同步,同时在买家库的基础上同步出了卖家库用来查询已卖出的宝贝,在卖家库基础上同步出了卖家库的备库,而这个备库才是真正对外提供交易批量API的库。交易批量API直接查询的是卖家库的备库,而交易详情API是关联的买家库。买家库是一个实时的库,而卖家库是由买家库同步过来的。卖家库主库与备库之间在高压情况下(双十一)会出现同步延迟导致批量查询订单遗漏。这种情况下的漏单是非常难以解决的,比较粗暴的做法是每天凌晨全量对昨天的订单再进行一次同步,但代价很高。
针对上述订单遗漏情况,淘宝推出了订单同步服务。
数据推送——订单同步服务
订单同步服务产生的背景是漏单解决成本高、API轮询实时性不高、大卖家数据难同步,该服务的定位是面向公网的数据同步服务,做到把阿里内部的数据库通过订单同步服务数据推送能够实时可靠的推送到ISV数据库。目前已经做到了一致性(数据完全一致,不漏单)、高实时(秒级完成数据同步)、通用化(千人千面,自助接入和开通)、可伸缩(可横向扩展、支持亿级数据同步)。
数据推送架构
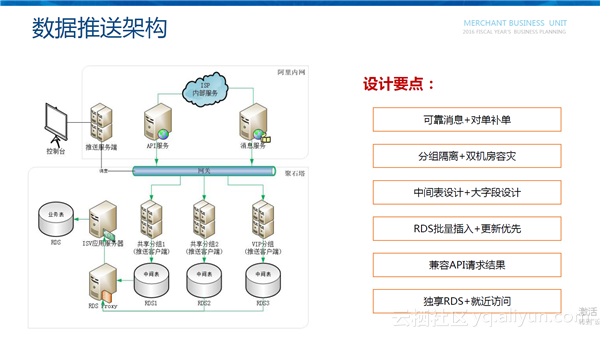
如上图所示,整个数据推送的架构分为两部分:部署在阿里内网的数据推送的服务端、淘宝开放平台的API服务和消息服务;在聚石塔内部署的数据推送的客户端、ISV应用服务器以及ISV的RDS。
数据推送的设计要点包括:
可靠消息+对单补单:通过可靠的消息服务保证订单实时推送到RDS里面;通过增量API、大数据、ODPS进行对单补单,确保订单状态与淘宝完全一致;
分组隔离+双机房容灾:数据推送客户端采用了分组隔离的方式,为每一个分组至少分配两台以上的机器,并且分到不同的机房,即使其中一个机房宕机了,也不会影响数据的正常推送,并且隔离各应用之间的影响;
中间表+大字段:数据库上采用中间表和大字段的设计,适配各种ISV的个性化字段推送需求;
批量插入+更新优先:订单RDS采用批量插入,提高写入效率,订单发生变更后,采用更新优先,避免每次更新都要先查询一次DB,减少对DB的查询次数;
兼容API请求结果:存储到RDS里面的数据是兼容API请求的JSON返回格式,可以使用TOP提供的SDK直接解释成交易对象;
独享RDS+就近访问:RDS是各应用独享的,访问频率和性能由ISV自己控制,不会像API那样受他人的影响。整个RDS和数据推送客户端是放在一起的,数据推送可以就近访问,同步效率更高。
数据推送中间表设计
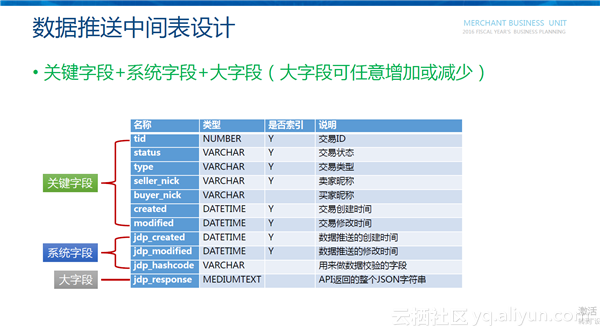
中间表分为关键字段、系统字段和大字段。关键字段是订单里面比较重要的字段,比如交易ID、交易状态、交易类型等。系统字段是用于整个数据推送在进行订单的增、删、改、查以及对单时所用到的字段。大字段是订单详情API返回的整个JSON字符串,可任意定制需要返回的字段。
数据推送最佳实践
- 先看官方的使用说明(搜索“订单同步服务使用”)
- 按需设置需要推送的字段及历史数据
- 按需设置系统库保留时长(最短可以设置为2天)
- 推荐使用“jdp_modified字段+倒排序+逆向翻页”获取增量订单
- 不要对sys_info库的表进行count,查询尽量走索引
- 多RDS使用,尽可能保证用户均匀分布
- RDS推荐规格,“每1万用户+保留2天”选择IOPS为600~1200的RDS
官方仓库对接标准——奇门
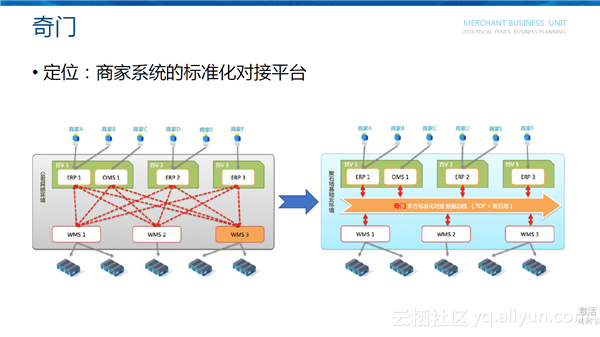
对于ERP与WMS的互通,ISV以前更多的是通过自研发进行对接,需要双方沟通接口标准,制定对接计划,联调测试等,对接的成本高,周期长,重复对接。针对这些问题,淘宝开放平台推出了奇门,为商家ERP与WMS提供标准化的对接。从图中可以看出,以前ERP和WMS对接的整个结构是一个网状的结构,一个ERP需要和所有的WMS进行对接,反之亦然,是一个N对N的情况。奇门引入了数据总线的概念,把ERP和WMS之间对接的数据交互的场景进行标准化,形成数据总线,这样的好处是ERP只需要和奇门数据总线进行对接就可以实现任意WMS的对接,反之亦然,是一个N对1的情况。
奇门的优势
- ERP与WMS互通标准,目前已定义36个标准API接口,覆盖常用场景
- 覆盖面广,主流的ERP与WMS都已接入
- 高效对接,白皮书、API在线文档、奇门SDK、挡板自测
- 稳定,久经考验的高可靠、高性能网关,支持商家级流量控制
- 安全,API请求不可篡改,不可重放,双向授权认证
- 追溯,所有API请求记录持久化存储,系统纠纷有据可查
奇门最佳实践
- 使用挡板测试降低联调成本
- 使用奇门SDK降低编码成本
- 不同系统之间的通讯容易出现超时问题,核心操作最好做幂等机制
- 标准没有提供的字段,可通过extendProps个性化设置
- 网络延迟低的情况下,走批量接口提高效率
高效订单回写方法——批量API
除了聚石塔内的API调用以外,有些商家会在移动端或者办公网络中调用API,比如在千牛插件里面调用API,此时的效率一般很差,因为在弱网环境下,每次API请求的TCP的三次握手建立连接时长更高,每次API调用总体时长比在聚石塔里面调用要高很多。以前开放平台也提供了两种批量API调用方式来解决这个问题:一个是TQL,但TQL调用方式,不易理解,串行调用,安全隐患高;另外一个是ATS,但ATS提供成本高,使用复杂,实时性差。批量API可以做到高性能、低延迟、通用化、容易使用。
批量API架构
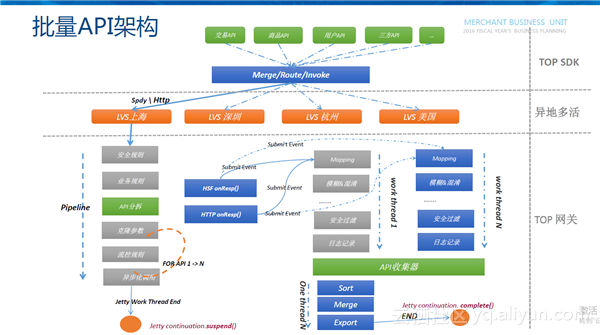
如上图所示,最上层是SDK,其作用是把各种API的请求进行合并,路由到相应的服务去进行调用。第二层是异地多活,SDK可以根据就近原则调用到相应的机房。第三层是TOP网关平台,一个请求进来之后会做API的校验、安全、流控等规则的校验等,校验通过后才会把API进行拆分,一个批量API请求拆分成N个API请求,然后把请求提交到后台相应的提供服务能力的机器上,等待后台服务处理完之后通过NIO的网络事件回来唤醒工作线程,工作线程会把后端返回的结果进行数据的转换包括安全过滤、日志打点等,直到所有请求处理完之后会进行API的收集、排序、合并、导出,最后把请求唤醒返回给客户端的SDK。整个服务端在处理批量API的过程中,采用了全异步化的处理,不管一次发起多少次API请求,都不会影响服务端的稳定性和效率,这是批量API区别于TQL和ATS最根本的地方。
批量API协议
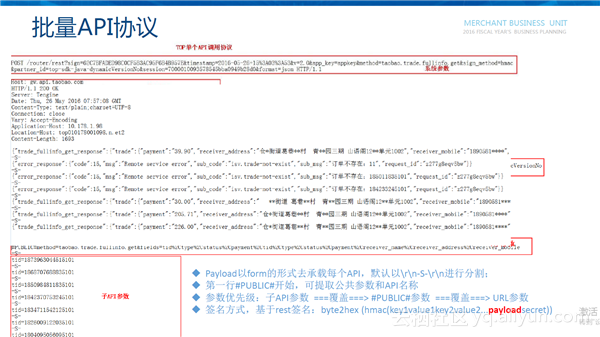
单个API的协议通过签名、头部参数的设置、业务参数的拼装实现一个API的调用。批量API的协议和单个API协议的区别比较小,唯一的区别是body里面的参数,引入了一个公共参数,可以放到公共字段中避免重复传送,减少网络开销。不同API的参数放到子参数列表中,并且通过-s-的分隔符分开。
批量API的几个特点:Payload以form的形式去承载每个API,默认以\r\n-S-\r\n进行分割(也支持自定义分隔符);第一行#PUBLIC#开始,可提取公共参数和API名称;参数优先级:子API参数 ===覆盖===> #PUBLIC#参数 ===覆盖===> URL参数;签名方式,基于rest签名:byte2hex (hmac(key1value1key2value2...payloadsecret))。
批量API与普通API比较
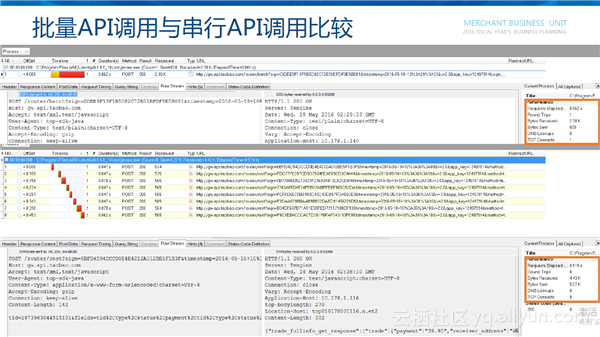
单个API的调用方式比较熟悉,比如调用订单详情API,首先创建淘宝的客户端,然后新建调用订单详情的request,设置要查询的订单字段,每个请求执行一次request。批量API引入TaobaoBatchRequest的对象,不会每次请求都添加相同的字段,只需要去新建不同的request,追加到batch request中,最后只发起一次API调用即可。批量API调用与串行API调用比较发现,批量API调用和单次API调用时间接近,远比串行API调用效率高。




