Greenplum DB 号称是世界上第一个开源的大规模并行数据仓库,最初是基于 PostgreSQL,现在已经添加了大量数据库方面的创新。Greenplum 提供 PD 级别数据量的强大和快速分析能力,特别是面向大数据方面的分析能力,支持大数据的超高性能分析查询。在本次分享中,曾文旌从GPDB架构入手,辅助以SQL和优化器的案例以及对GPDB的硬件和性能的分析,对GPDB实现进行了详细解析。分享最后,他还对比了GPDB的优势和局限性,并对GPDB的未来发展进行了展望。
以下是现场分享观点整理。
名词简介

在分享开始之前,首先解释一下整个内容中最关键的几个名词:
- MPP(Massive parallel processing)为大规模并行处理系统,一般是指多个SQL数据库节点搭建而成的数据库仓库;在执行SQL查询的时候,任务可分解到多个数据库查询,然后将结果返回给用户。
- MR(mapreduce)是一种编程模型,结合了大规模处理并行运算编程的思想,可粗略地分成两部分,map和reduce,任何一个复杂的任务都可以拆成map和reduce的串行组合,主要思想从函数式的编程语言所借鉴过来。
- SN(Shared nothing)为存储的架构,用于存放数据,由多个完全独立的处理节点构成,每个处理节点有自己独立的处理SMP的架构,他们存储的数据没有共享的部分,独立的磁盘存放数据,多个SMP数据节点之间通过高速网络连接,协同起来完成一个复杂的任务。
- Data distribution 即数据分发。SN架构上,MPP完成并行任务,它们之间需要做数据的沟通,GPDB的沟通相对复杂,每个数据节点之间可以相互沟通,有的数据库产品可能只允许master和数据交流,master和其他数据节点不能相互分发数据。

MPP的完整定义如上所示,它的重点首先是本地存储数据,其次是通过网络交换数据,最后是每个数据都是数据节点的一部分,它们之间没有共享。
GPDB架构特点
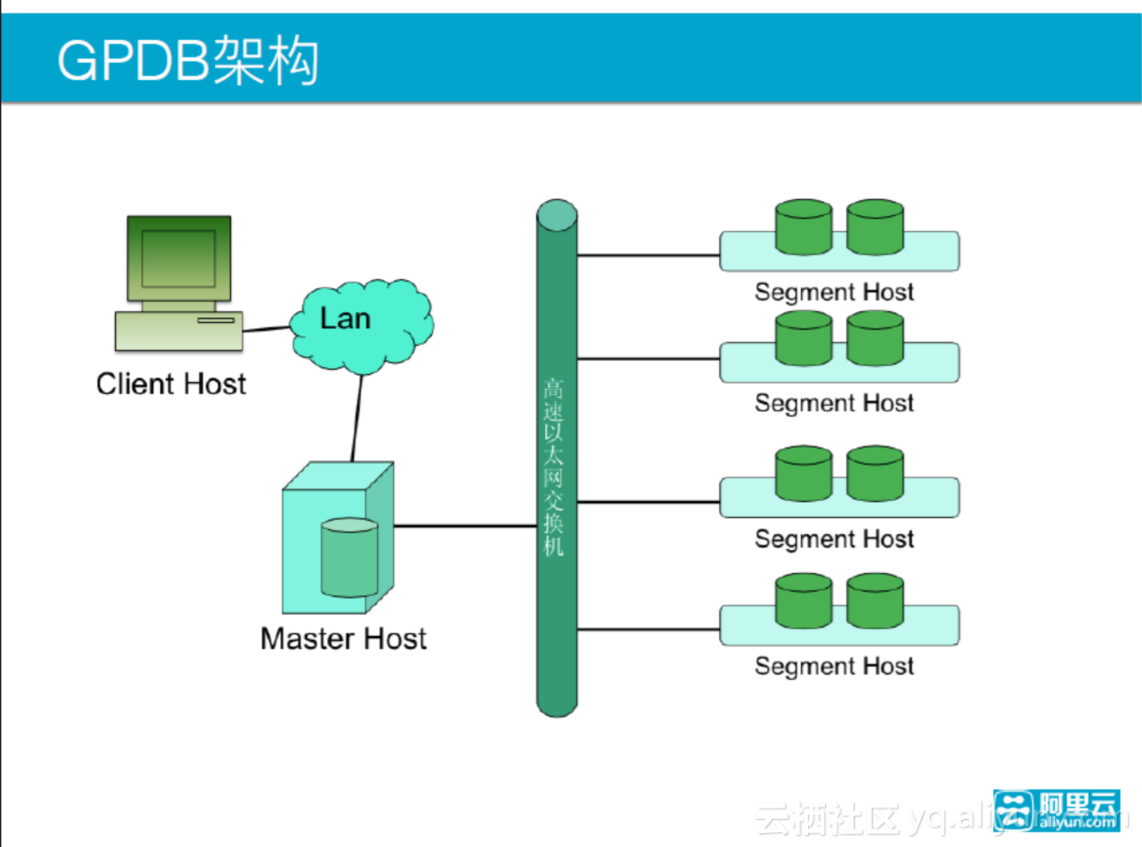
上图显示的GPDB架构图,架构中最主要的中心节点是Master Host,它可以和用户的客户端直接交互;其他的数据连接的是Segment Host,并且Segment中存放了一部分的数据;Master和Segment之间通过高速网络交换。
MPP VS MR

上图是MR的相关定义信息。显然,Hadoop主要分为两部分,一是存储部分,即分布式存储,比如熟悉的HDFS;二是大数据的计算框架,通常为MapReduce。

Apache Hadoop是谷歌思想的一种流行的实现。整个Hadoop实现的过程中,它是作为一种开源的框架,设计思路是使用低成本的硬件和自己软件中的容错功能,容错功能由HDFS来完成。有了HDFS,Apache Hadoop很容易上一定的规模,HDFS是Hadoop做到很大集群的最主要的原因。
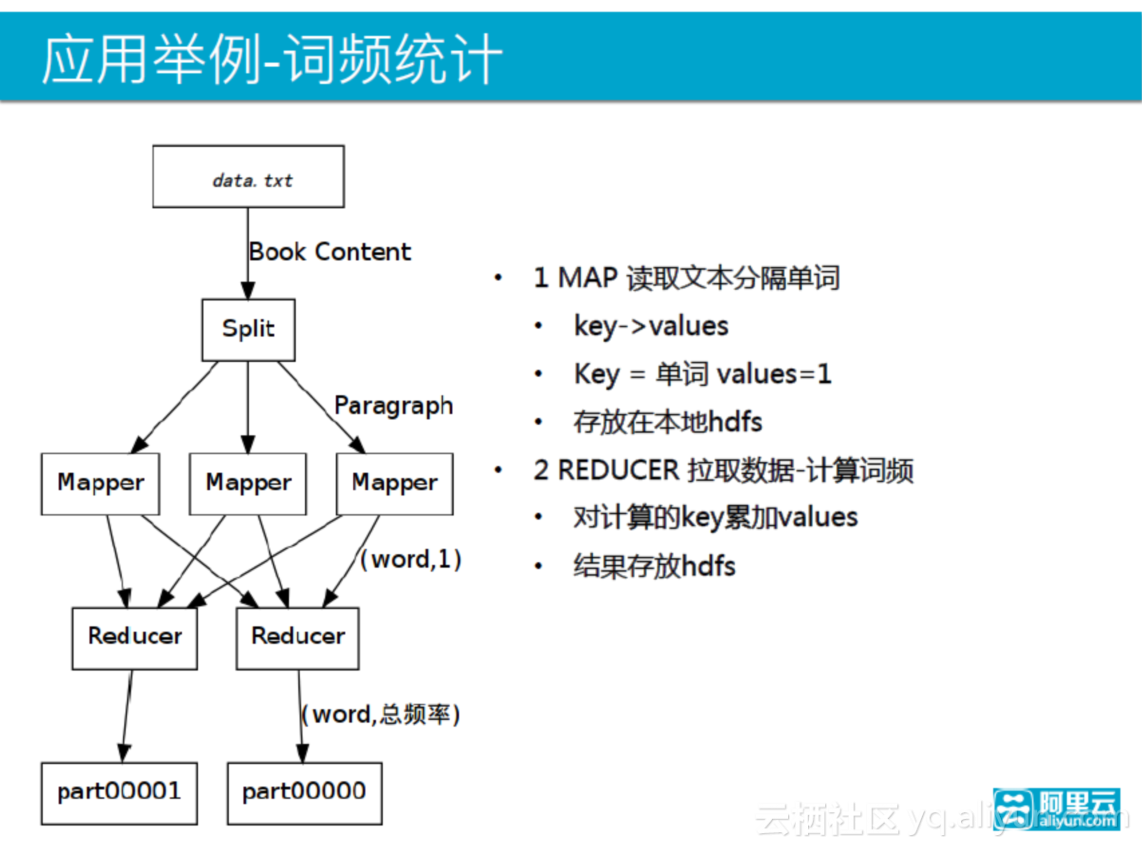
词频统计是MapReduce的设计思路常用的简单案例,将文本中单词出现的次数做一个统计,其过程也体现了Hadoop的处理思想。第一步MAP将数据从HDFS中读出来,将句子拆成单词形式,这是一个key-value的过程,key就是单词本身,value是词频,一般取1,其结果再存放到本地HDFS中,即入库的过程;第二步是reduce的过程,从HDFS中拉取数据,然后计算词频,将相同的key值放到一个reducer中,再将key累加起来,最后得到的结果再存回HDFS。如果再做一些更复杂的操作,就重新迭代几次,这个统称为MapReduce思想。
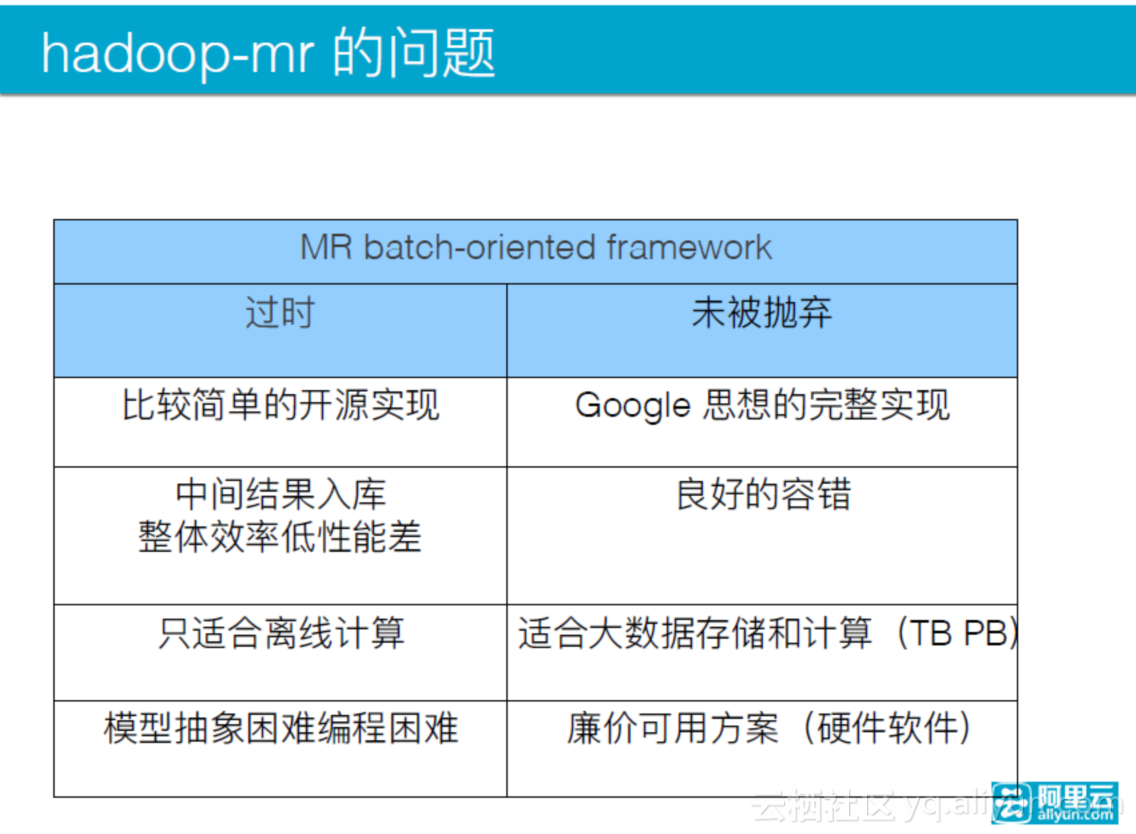
这个思想的开源版本未被抛弃的优势在于:它完整地实现了Google思想,同时具有良好的容错,适合大数据存储和计算,并且具有廉价的可用方案(软件硬件)。但其也有很多思想是过时的,例如它只是比较简单的开源实现,只适合离线计算,同时模型抽象困难、编程困难。此外它还具有一个致命的弱点,即中间结果入库整体效率低、性能差。
虽然实现方式已经过时了,但它仍未被抛弃,而且性能还会改进。

上图显示的是MR的典型的发展方向:首先,十年前主要是MapReduce,它的编程方式不太好学习;于是就有了hive,即上面是它自己的语句,底层转换成了MapReduce的方式;再后来,由于每次入库都比较慢,则将这种方式放在内存里面做,即memory的实现方式。

在关系型数据库里,词频统计也很简单,一个SQL语句就可以做到。SQL语句在GPDB是兼容SQL语句的,如上图的语句中:通过一个函数从some_table表把some_column字段拆成了一列多行的形式,将其抽象成一个临时表,再对临时表进行GROUP BY,针对每个GROUP进行一次count,最后将结果计算出来。

上图是GPDB中的QUERY PLAN,通过查看SQL语句的执行计划了解执行过程以及使用的算法。上图是一个16节点的GPDB,在segment中被拆成了两部分,首先是底层的顺序扫描,读到之后用函数拆分,然后将拆分的结果作为一次哈希聚集,并通过网络的分布节点,发送到各个segment。发送方式是哈希方式,定义一个哈希分布,把需要的数据留下,把不需要的分发到需要它的segment中。另外一个segment的作用是收到这个数据,再做一个哈希聚集,最终把这个数据再发送给master节点,它的分发程度和segment一样。所以我们看到:中间的网络分发是segment实现的一个点,它能做到Hadoop相同的功能,但前提是把非结构型数据转换成结构型数据存放到关系型数据库的表里,这样性能才可以得到保证。
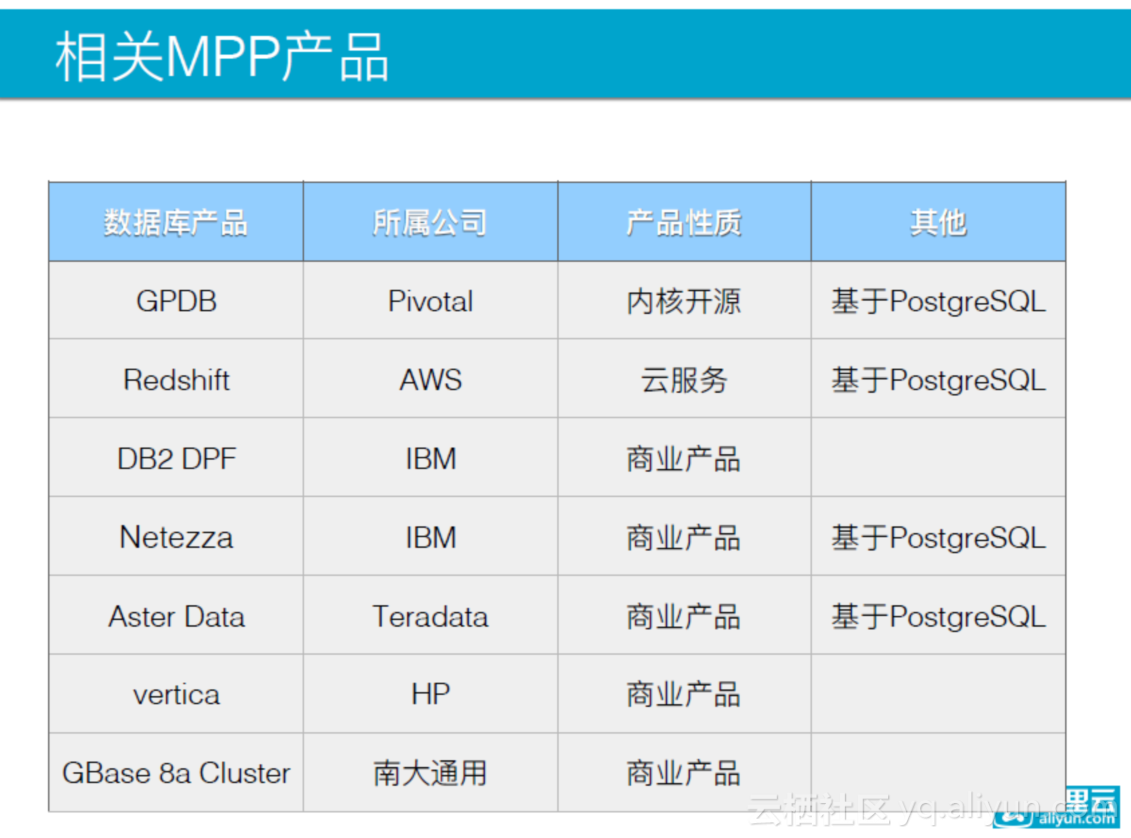
GPDB同类产品
相关的MPP产品,总结如下表,在这里不一一详述。
GPDB关键特性解析
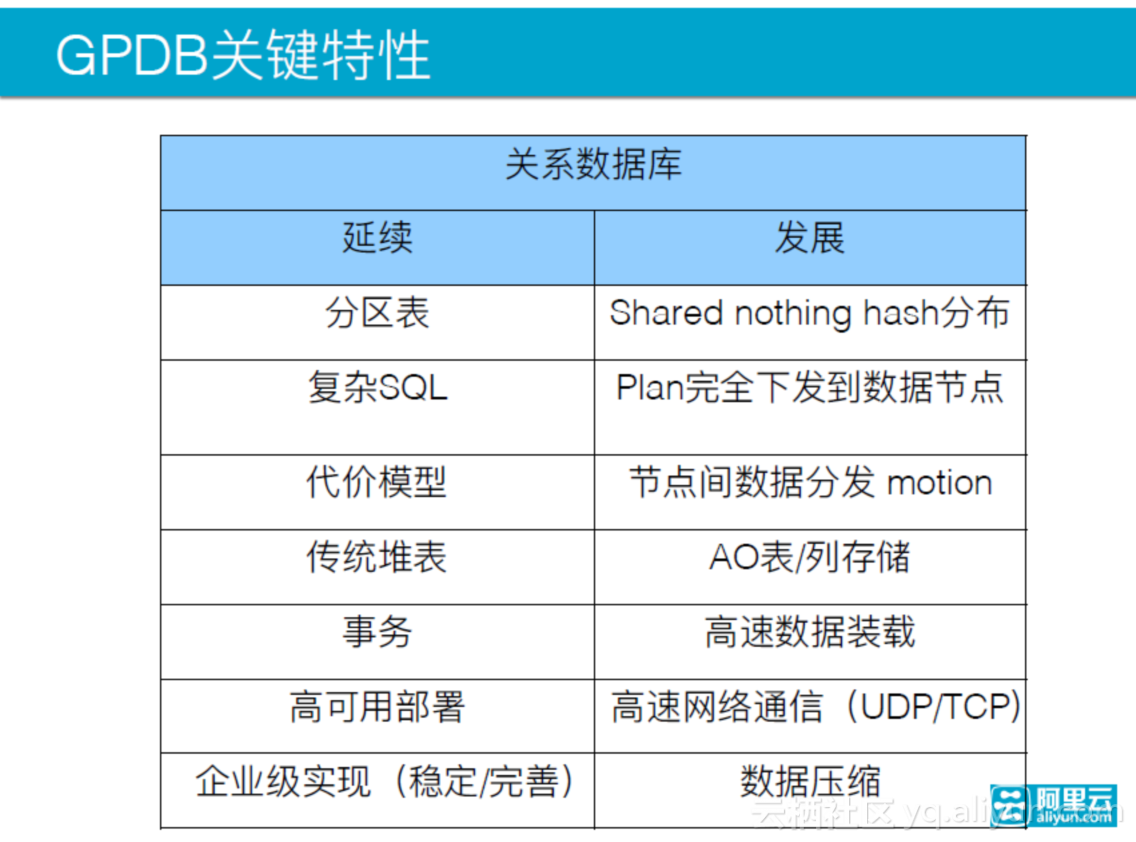
接下来解析GPDB的关键特性:
- 分区表是关系型数据库,GPDB做到了完整的分区表,不同类型的表都可以组成一张分区表,比如说堆表、列存储的表。另一个区别是Shared nothing hush分布。
- 传统的数据库支持复杂的SQL语句,完成复杂的任务,并可以通过一个SQL语句表达出来,整个语句的执行计算也好,数据读取也好,都被完全下发到了数据节点上。
- 关系数据库的代价模型,这也是它能做复杂SQL的关键性的原因。根据不同表的规模选取SQL语句,节点间的数据可以做相互的分发,根据该特性可以进行网络方面的优化。
- 传统堆表,相当于一行数据是元存储方式,多列组合成一条,存储在数据库上面,支持列存储,支持压缩数据的存储。
- GPDB可以像通常的关系型数据库那样支持事务,可以做并发,但是有一定的限度。SQL语句的select并发没有问题。对于高速数据装载,GPDB可以让每一个segment同时往自己的节点上装载数据,这和传统的方式相比,性能有很大的区别,装载性能很好,有时候甚至可以把网络的带宽占满。
- 企业的高可用性。,支持一个高可用的部署,以镜像节点的方式,持续地提供服务。还有高速网络通信,因为不可能为每一个业务都定制表的分发方式,在TCP的基础上又增加的UDP的连接协议,显著地提高网络的传输效率。
- 足够稳定,功能相对完善。支持数据压缩,能够提供压缩算法的选择。开源版本支持开源的一些压缩方式,GPDB还有一个收费的压缩方式,需要的话可以购买。
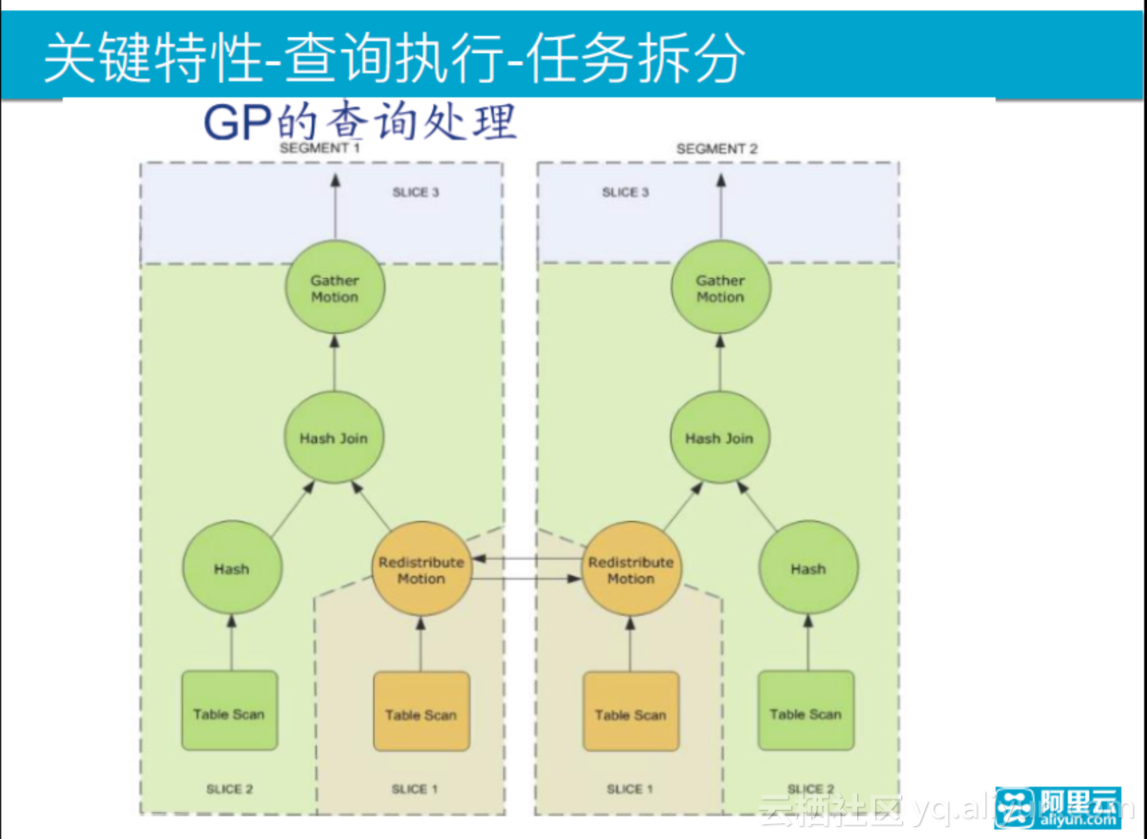
上图是查询的执行方式。master上不存储用户数据,但是会存放表定义,有时候可通过copy的方式往master上加载数据,然后maser再向每个segment上分发数据。master支持stand by节点,stand by不能读,只是一个备份,在master节点出问题的时候,让stand by连接,继续做任务,然后再将master搭起来,实现高可用。
查询执行的任务拆分是一个简单的两个表的作用语句,它在segment中被分为了两个部分来执行,分片1扫到数据之后通过网络重分布motion节点到另外一个节点,然后它发送给本segment的另外一个节点;根据motion的定义,另一个分片扫描另外一部分表,把收到的数据作一些函数的调用,最后的数据会发送给gather motion节点。每个segment的执行方式完全一样,最后的gather motion实际上是一个master节点,它会收所有的segment数据。
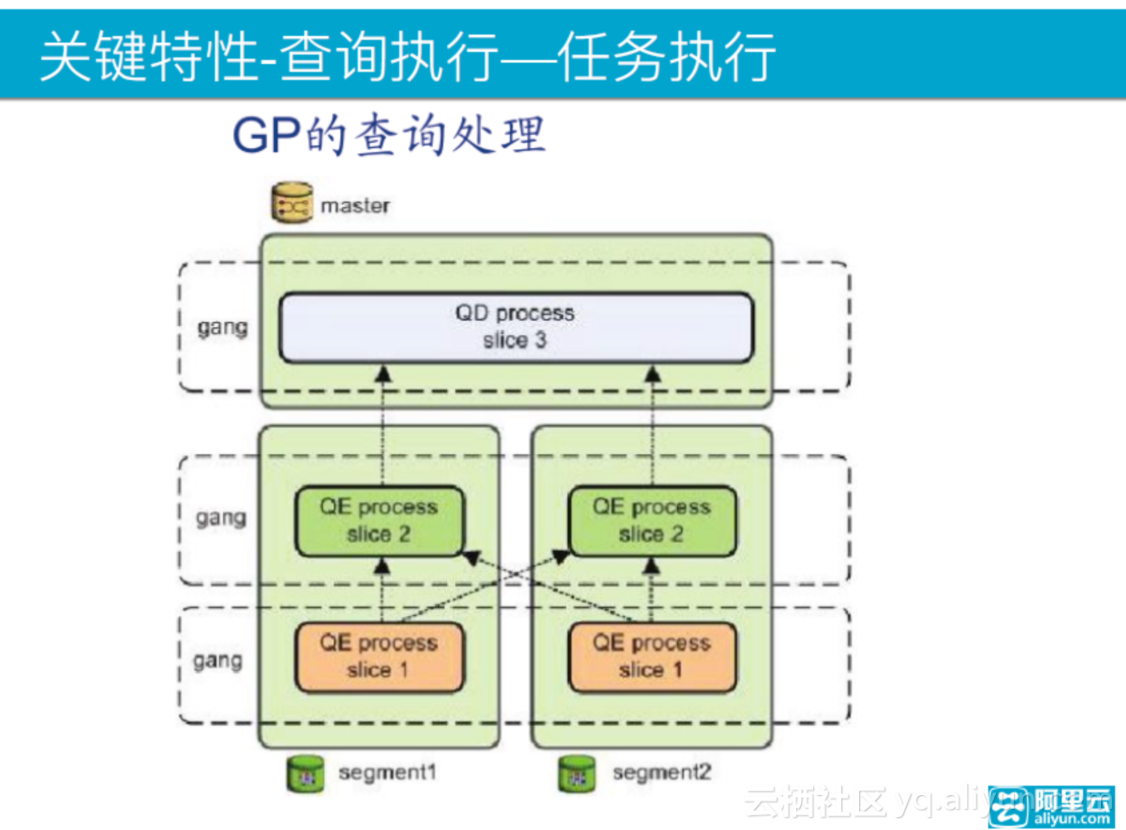
接下来说任务执行,在这里出现了gang的概念。master分发任务称为QD process,即查询分发,首先进行segment查询,多个步骤,即多个gang的方式来执行,下层会将数据往上层上传,最终汇总到QD上。
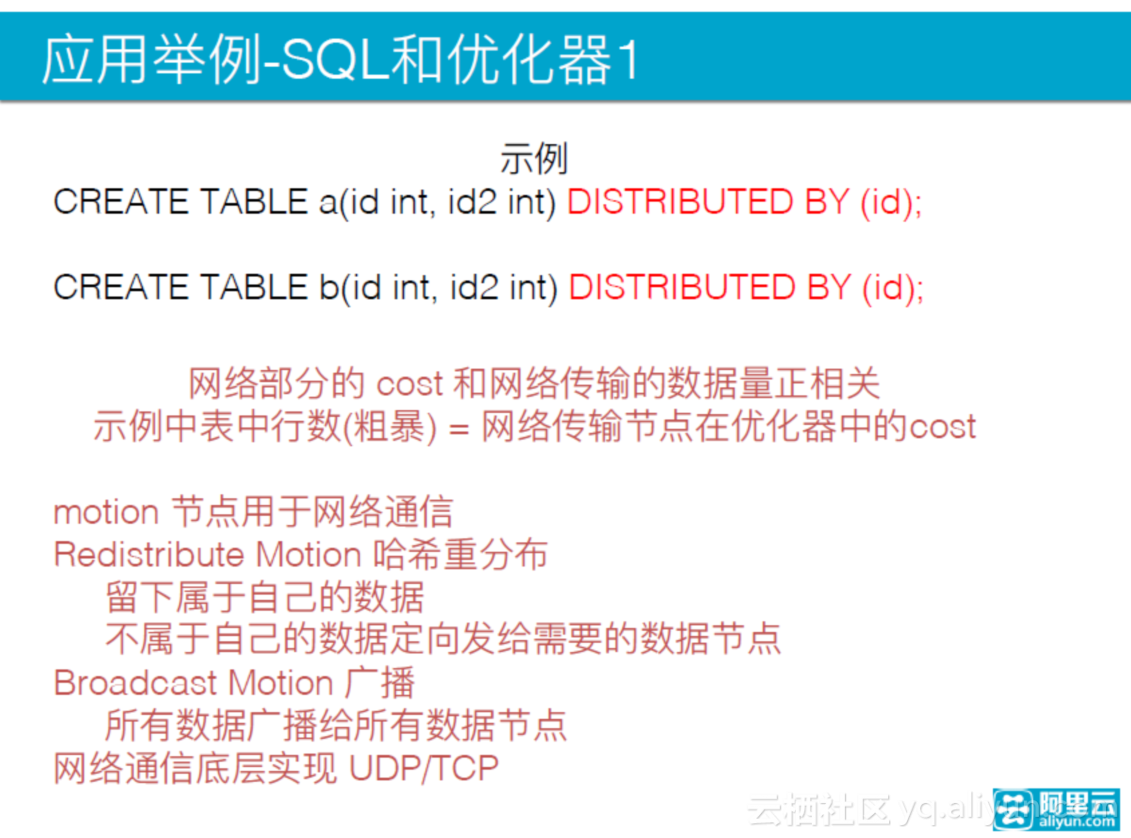
我们以两个表为例,说明一下SQL语句的执行过程。表a和表b都是以id列作为分发,这里面做了一个粗暴的估计,以表里的行数出现。网络部分的cost和网络传输的数据量正相关。另一部分是用于网络通信的motion节点,它有两种类型:一是Redistribute Motion哈希重分布,二是Broadcast Motion广播。

第一个优化器例子: A表和b表都各自有10000行,连接之后,可以看到整个的执行计划没有motion节点,因此不需要做网络重分布 。

若表的规模不变化,左边的是表a的分布列,id2不是分布列。b表会按照id2计算重分布,然后在所有的节点上做一个重分布,重分布b表时代价简单理解为10000;方法二是把a/b表广播出去,它们的代价是10000*16。很显然,重分布b表的代价最小,执行计划也是这么选择的,即优化器自动选择了最优的执行方式。

当a表的规模变为100,b表还是10000,表的连接方式不变。显然,广播a表的时候代价最小,重分布b代价为10000,全广播b代价为10000*16,优化器也自动选择了最优的方式。

如果数据规模不变,改变连接方式,连接的两个列都不是数据的分布列,很容易看出全广播a表代价最小。

最后一个例子,不连接数据的分布列,表的大小都是10000行。定义一个id2作为重分布列,a表b表都重分布一次,对比全广播a,全广播b代价小很多,所以在这个数据规模下选择重分布AB执行方式。

如图,可将优化器作如上总结:SQL比较友好,学习成本低,支持范围比较多。基于统计信息的代价模型有核心的优势,SQL语句越复杂,优势越明显。
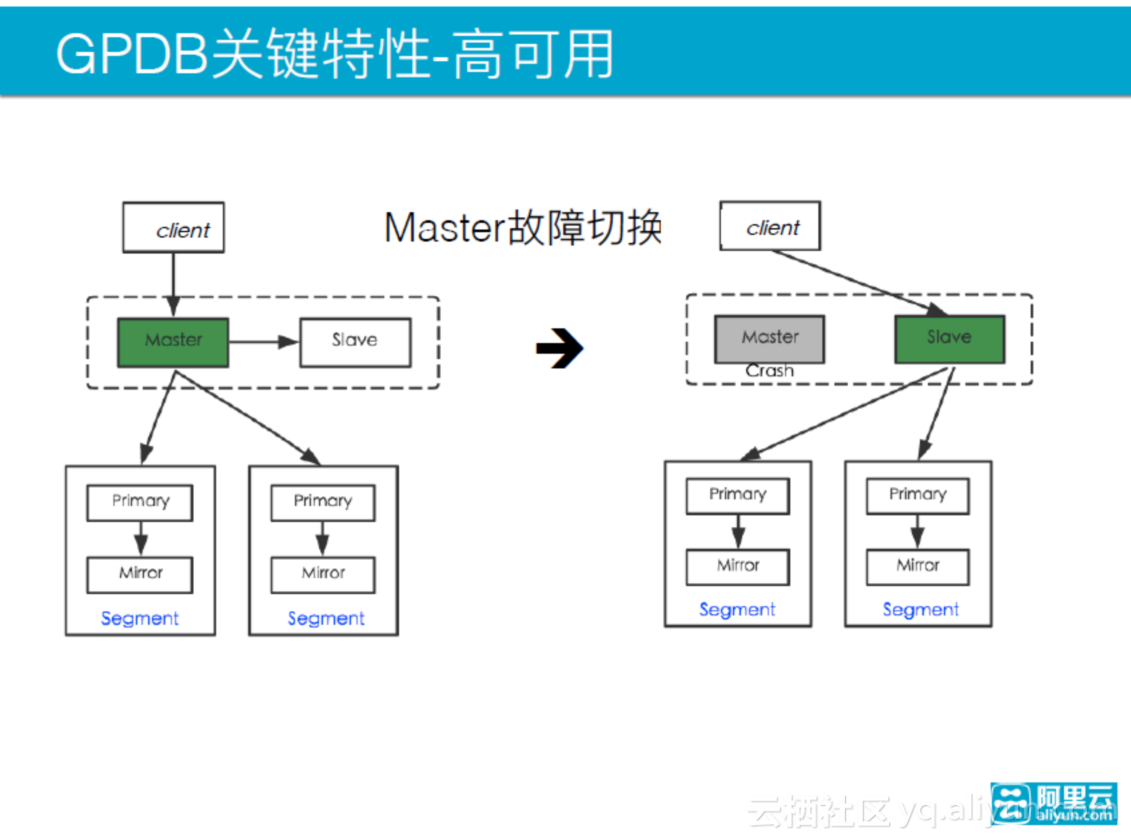
除此之外,还有一个高可用的部署方式,master的一个备份叫slave,它们之间通过流复制同步,master若出现问题,slave可以被激活,然后成为新的master。master和slave之间是流复制同步,半同步;segment之间是基于文件的快的同步,概念上是一个primary和mirror。segment若出现问题,有一个机制来保证继续往下提供服务,若网络闪断,primary会积攒一些数据,等网络好的时候再同步到mirror上。
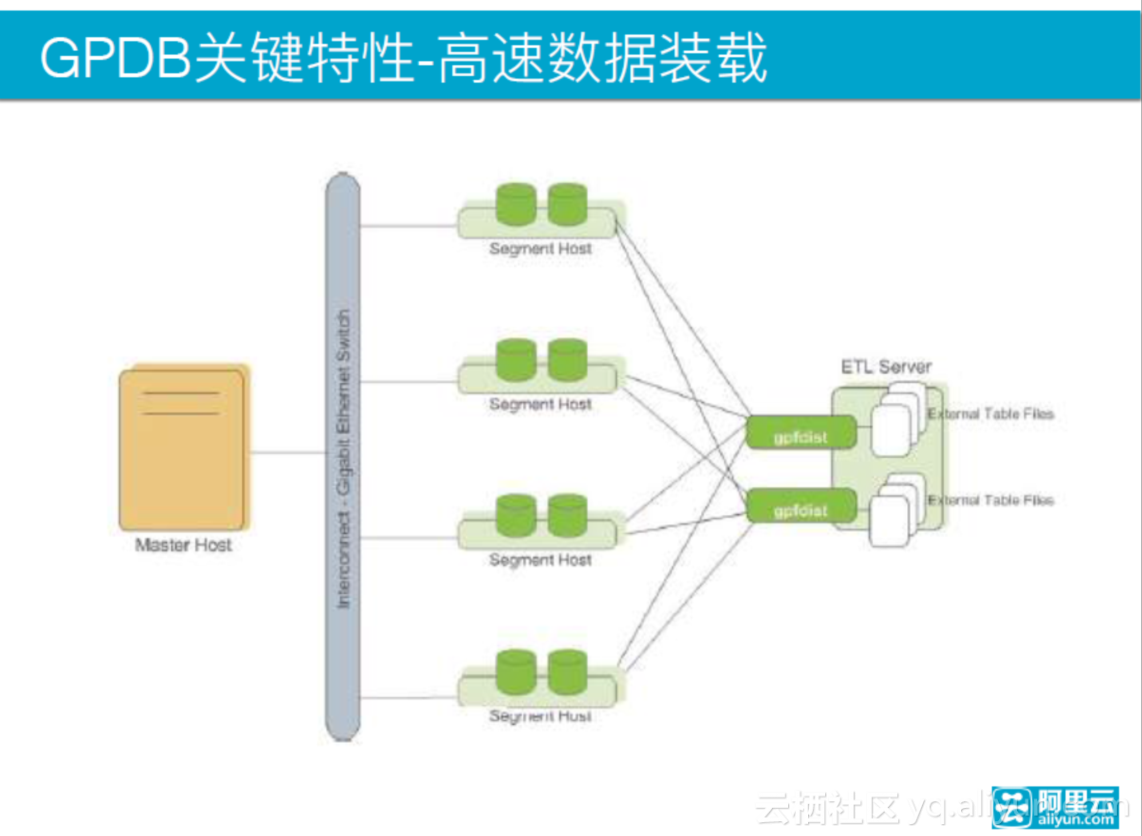
上图为高速数据装载,GPDB可以支持分布式数据装载。首先部署多个存放数据的节点,数据用web表的形式通过master请求;master请求之后,所有的segment通过GPFD的数据分发服务,GPFD收到数据的请求,然后给所有segment发数据,对等随机地发送,也可以部署多个GPFD,将数据平均地分配到每一个中, segment解析数据,和重分布有点类似,留下自己的那部分数据,存到本地segment中,定向发送不属于自己的数据。segment是定向发送,GPFD发给segment是随机发送。所以说如果整个网络足够好,装载速度会非常快,可以装载全量数据,也可以批量装载。
GPDB硬件和性能

segment是存储和计算数据的节点,segment越多,并行程度越高。建议为每个segment至少分配一个物理核CPU,8G内存,网络至少千兆以上,因为刚刚列举的很多特性有网络要求;硬盘一般为RAID 5。mirror状态不会消耗很多CPU,但是会消耗对等的网络。

标准的TPCH测试用的比较多,很容易找到开源项目,最大测1T左右的数据;PC server和Hadoop比,性能好很多;SQL越复杂,GPDB性能越好,好的可能到几十倍。除了排序需要将数据缓存到磁盘,大部分的数据在内存里,通过网络做高速的分发,网络的分发经过优化,所以性能非常好。数据在内存是流式的执行方式,正常情况,一个数据被扫描到一个节点,处理完之后立马发送到上层节点,然后再往上发。
GPDB优势和局限性

GPDB的优势在于它可以做网络数据同步,能够控制整个SQL语句的队列,控制内存的消耗;还可以用它来做资源的限制,根据自己硬件的需要控制资源;此外,每个模块经过多年的打磨,优化很好。

GPDB的局限性,有如下几种:
- 扩展性,它不像Hadoop和HDFS可以扩展到上千台,有理论瓶颈。从使用来说,比如说扩容,扩容之后所有的整个数据都需要重分布,存储方式限制了其继续往上扩展,运维的成本有可能会越来越高,当然,几十台的情况下还是游刃有余的。
- 增量入库, GP提供了一个其他的方式,来做到类似的功能。把增量成批地导出到文本,然后再成批地导入到GPDB里面去,最后再用合并的方式合并到原有的数据库,变相做到增量入库。
- 容错,上面提到通过备份的方式容错,这个有一定的局限性。
- 改进空间,比如,它支持的存储方式有列存储,列存储就是一列一个文件,用了分区表再用列存储,磁盘上的文件就会非常多,如果说再来一个并发的查询,由于PG是多进程的方式,在文件OS上同时打开,打开的个数就会特别多。
GPDB的发展

GPDB未来发展有几个方面:
- 新一代优化器,也是开源部分,在一些情况下,会比原有的GPDB优化器更好,尤其是在算多个分区表相互作用的情况下。
- CPU的消耗会明显减少,整个CPU运行的效率会提高,网上发布了测试的版本,从结果来看,性能不错。
- 其他数据库没有UDP通信的优化,所以GPDB发展的较好。
- 内部发展方向,用HDFS提高容错性,数据和计算分离。每个HDFS节点都会挂segment节点的进程,当需要的时候,启动segment计算;不需要的时候不会存在。
总结

最后简单地总结一下: GPDB的开源,在TP级别游刃有余,解决方案非常好,应用性较好,比Hadoop有着明显的优势;但是以后Hadoop也会朝着相同的方向发展。另一方面,MR和MPP的关系是相互学习,能够融合互相的优点。相当于MR把一些计算优化,使性能更好;MPP也会学习Hadoop把数据放在HDFS上,就这样实现相互融合,它们之间的一些界限作为并行计算来说越来越模糊,未来也会有很多开源或者商业的产品,在这上面诞生。