欢迎关注大数据和人工智能技术文章发布的微信公众号:清研学堂,在这里你可以学到夜白(作者笔名)精心整理的笔记,让我们每天进步一点点,让优秀成为一种习惯!
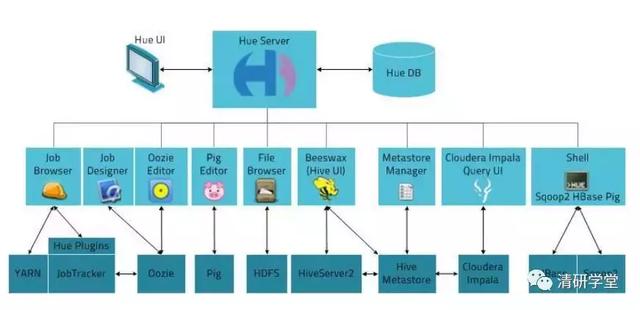
日常的大数据使用都是在服务器命令行中进行的,可视化功能仅仅依靠各个组件自带的web界面来实现,不同组件对应不同的端口号,如:HDFS(50070),Yarn(8088),Hbase(16010)等等,而大数据的组件又有很多,为了解决某个问题,常常需要结合多个组件来使用,但是每个组件又有独立的web界面进行可视化,这时,如果有一个统一的web界面来管理并可以开发所有大数据的组件是非常方便的,而Hue正是这样的工具,它管理的大数据组件包括:HDFS、HBase、Hive、Pig、Sqoop、Spark、Scala等等几乎所有常用的组件。
(一)、HUE的介绍:
HUE是一个开源的Apache hadoop UI系统,管理hadoop生态体系结构的所有组件,基于python web框架Django实现,由Cloudera开发
HUE的tar包是源码包,采用源码安装 (源码安装的好处:卸载和移植软件方便)
源码安装三步骤:
1、配置:./configure --preifix=安装的目录 #检测系统配置,生成makefile文件 如果有makefile文件,直接进行编译和安装
2、编译:make
3、安装:make install
HUE的http服务端口:8888
二、安装和配置HUE:
安装HUE前,需要安装它所需要的rpm包及其依赖(27个),否则HUE运行会报错 rpm包:redhat软件包管理器 存放在redhat光盘Packages目录下
rpm包与tar.gz/.tgz、.bz2的区别:
rpm形式的软件包安装、升级、卸载方便,推荐初学者使用rpm形式的软件包
安装:rpm -ivh
卸载:rpm -e
tar.gz形式的软件包安装方便,卸载麻烦,用tar工具打包、gzip/bzip2压缩,安装时直接调用gzip/bzip2解压即可。如果解压后只有单一目录
用rm -rf命令删除,如果解压后分散在多个目录,必须手动一一删除
安装:tar -zxvf *.tar.gz/ tar -yxvf *.bz2
卸载:rm -rf/手动删除
一、安装rpm包:
方法:使用yum安装rpm包
yum:能够从指定的资源库(repository)自动下载、安装、升级rpm包及其依赖,必须要有可靠的资源库(repository)
1、挂载光盘 mount /dev/cdrom /mnt
mount命令:挂载硬盘/光盘/iso文件到指定目录下,访问其中的数据
2、建立yum资源库
cd /etc/yum.repos.d #yum资源库默认所在的目录
vim redhat7.repo
[redhat-yum] 资源库的标识
name=redhat7 资源库的名字
baseurl=file:///mnt 资源库的位置
enabled=1 启用资源库
gpgcheck=0 不检查资源库中的rpm包是否是官方的
3、执行下面的语句:
yum install gcc g++ libxml2-devel libxslt-devel cyrus-sasl-devel cyrus-sasl-gssapi mysql-devel python-devel python-setuptools sqlite-devel ant ibsasl2-dev libsasl2-modules-gssapi-mit libkrb5-dev libtidy-0.99-0 mvn openldap-dev libffi-devel gmp-devel openldap-devel
(二)、安装HUE:
解压:tar -zxvf hue-4.0.1.tgz
指定安装目录安装:PREFIX=/root/training make install
注:如果不指定prefix,可执行文件默认安装到/usr/local/bin中,配置文件默认安装到/usr/local/etc中,库文件默认安装到/usr/local/lib中,其他文件默认安装到/usr/local/share中
注:HUE的tar包是源码包,采用源码安装
三、配置HUE:
1、与hadoop集成:1、开启hdfs的web功能 2、允许HUE操作hdfs
<!--开启hdfs的web功能-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--设置hadoop集群root的代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--设置hadoop集群root的代理用户组-->
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
3、添加一个新用户并授权:hue要对/root/training/hue有访问权限
adduser hue
chown -R hue.hue /root/training/hue
4、修改配置文件hue.ini($HUE_HOME/desktop/conf):
http_hosts 192.168.182.11
http_port 192.168.182.11
server_user root
server_group root
default_user root
default_hdfs_superuser root
fs_defaulfs hdfs://192.168.182.11:9000
webhdfs_url http://192.168.182.11:50070/webhdfs/v1
hadoop_conf_dir /root/training/hadoop-2.7.3/etc/hadoop
resourcemanager_host 192.168.182.11
resourcemanager_api_url http://192.168.182.11:8088
proxy_api_url http://192.168.182.11:8088
history_server_api_url http://192.168.182.11:19888
二、与HBase集成:
1、修改配置文件hue.ini:
hbase_clusters=(Cluster|192.168.182.11:9090)
hbase_conf_dir=/root/training/hbase-1.3.1/conf
三、与Hive集成:
hive_server_host=192.168.182.11
hive_server_port=10000
hive_conf_dir=/root/training/apache-hive-2.3.0-bin/conf
(三)、启动HUE:
1、启动hadoop:start-all.sh hue就可以访问hadoop
2、启动hbase:start-hbase.sh
3、启动hbase的thrift server:hbase-daemon.sh start thrift hue就可以访问hbase
4、启动hive的元信息存储:hive --service metastore(表示前台运行) hue就可以访问hive的元信息
5、启动hive的thrift server:hiveserver2 &(表示后台运行) hue就可以访问hive
6、启动hue:bin/supervisor($HUE_HOME/build/env)
作者:李金泽,清华大学在读硕士,研究方向:大数据和人工智能

