以下内容皆为个人摸索,没有人专门指导(公司不给力啊!DBA和大牛都木有。。。),所以难免出错,如有错误欢迎指正,小子勇于接受批评~(*^__^*) ~
水平分库分表和垂直分库分表,大家都经常谈,我说下我的理解,看图:
垂直分表就不用说了,基本上会SQLServer的都会。
垂直分库就是根据业务需求来分库,比如教育系列的,可以分为资讯,课程,用户(学生,学校)三个数据库。比如电商的可以分为订单,商品,用户(商家,消费者)三个数据库。这边只是举个例子,具体的你得根据你们自己业务的实际情况来分,不是分的越多越好,最好是遇到瓶颈了再去做这些事情(这个过程才能学到很多东西)
水平分表主要就两种方法,Hash取余法和时间路由法。我重点说下时间路由的方法,这种方案后期扩容和历史数据抽离【结合列索引更劲爆哦~】比较方便。
举个简单的路由表:(时间你可以用传统的格式,我这边用的是时间轴)
这个是文章表的时间路由表,每次查询文章的时候根据查询的时间看看
比如我现在准备写入数据,当前时间 2016/11/18 16:37:29 ==》1479458249
select RTableName from Route_Article where where 1479458249 between RCreateTime and REndTime
就可以知道我应该往哪个表里面写数据:==》Article2
同理,想查询某个时间的数据也是可以通过路由表知道该往哪个表里面查询
水平分库之前提了一下文件组(http://www.cnblogs.com/dunitian/p/5276431.html)后面还会有一篇文章进行扩展说明(http://www.cnblogs.com/dunitian/p/6078512.html),这边就不说了。
其实企业里面用的最多的是复合型的,比如:水平分库分表 ,水平分库+垂直分库+分表
真的有了这方面的瓶颈的话水平分表一般只能缓解,并不能真正解决,毕竟还是在一台服务器上。单表的数据量是减少了,但是IO,连接数,带宽之类的瓶颈并不能有多大的改善。
水平分库分表可以把IO瓶颈解决一部分,优化效果还是很明显的:
水平分库+垂直分库+分表,这个方案可以利用链接服务器,这样路由表就不用改了,把路由表的表名改成完整的名称(后面会说更好的方法)
看直观图:[192.168.1.250].[BigValues].[dbo].[Article]
我简单模拟一下:我PC的IP是:192.168.1.9
先在远程数据库稍微插点数据:2013-1-1 ~ 2015-1-1的数据,量倒是不多,200W左右
没有跨库查询过的同志,可以先预习一下同义词相关的知识:http://www.cnblogs.com/dunitian/p/6041323.html#tyc
先设置一下链接服务器。我自己摸索的这个方法可能和网上的不太一样,不要慌(没办法,我按照网上的没成功啊+_+)
安全性里面设置一下用户名和密码
可以了,看看吧:
先看看效果:
这个感觉挺好的,一般情况下都是没问题的,但是遇到数据库名字或者表改了就蛋疼了,得改多少东西??关键是不太方便,名字那么长。。。===》so,引入了同义词
create synonym Article for [192.168.1.250].[BigValues].[dbo].[Article]
再看看效果吧:
-----------------------------------------------------------------------------------------------------
是不是感觉特简单,也想改革起来了?(⊙o⊙)…,其实我还是建议快到瓶颈的时候再改,不然你会很蛋疼的,现在我就简单说几个蛋疼的地方~PS:附带我的解决方案
简单说下有哪些问题:
1.全局ID的问题,既然分表了,那么第一件事情就是把自增长去掉,(eg:表A,ID为44,表B,ID为44,那我取44的数据时,取哪个呢?)
一开始我是用GUID的方式,一直认为这个不太好,为啥呢,我一般用户ID或者管理员ID会用GUID,这样Burp的暴力解猜就比较上门槛了(简单使用:http://www.cnblogs.com/dunitian/p/5724872.html)
后来发现,GUID的主键基本上满足需求,但是无序列,而且太长了,排序什么的都各种不方便,后来就找其他方法,很多,比如时间轴,后来发现高并发下还是有重复的(毕竟已经不是单机了)最终采取了雪花算法(https://github.com/twitter/snowflake)
C#版本的国外朋友已经封装了,大家可以去看看:https://github.com/ccollie/snowflake-net
强大的网友出来个简化版本:http://blog.csdn.net/***/article/details/***6 (地址我就不贴了,对前辈需要最起码的尊敬)
一开始我用的是这个版本,后来发现多线程的情况下有重复项。。。(demo:https://github.com/dunitian/TempCode/tree/master/2016-11-16/Twitter_Snowflake)
全局ID的激烈讨论:https://q.cnblogs.com/q/53552/
具体实现:http://www.cnblogs.com/dunitian/p/6130543.html
2.跨库Join
MySQL比较蛋疼,MSSQL好像没那么难,我是用链接服务器+同义词的方法解决的(上面演示的),如果有更好方案可以提点一下小子^_^
看图:
很多时候可以参考MyCat的一些东西,跨库查询肯定效率没有单机高。有时候会做一些处理来尽量避免跨库Join
比如说表A,表B,表C...常用的全局表我会把他们每个数据库存一遍,这样就方便多了(注意一下数据同步哦)
还有就是冗余一些字段
比如:产品表有这些字段:商品展图ID,展图URL,缩略展图URL。按理说这是不合理的,但是不这么干就得跨库查询了,适当牺牲嘛~
再比如:订单表里面:用户ID,用户名,店铺ID,店铺名,商品缩略展图。这样也是不合理的,但是。。。商品和订单大家都懂的,牵扯的表太多,有点夸张了~
以后分库的时候可以参考MyCat的ER分库 (相关联的一起分)
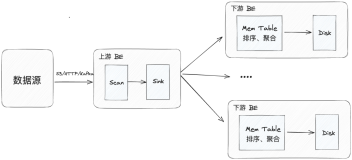
3.跨库排序、聚合等
比如要求Count,那么每个表都得单独求一下Count,然后汇总Count。这个过程可以通过应用程序去完成,毕竟可以根据路由表来统一汇总
排序就比较蛋疼了,如果是按时间(分表字段)的还好,因为我们路由表就是按时间分表的,相对简单。如果按照某个字段排序的话。。。。。(⊙o⊙)…没办法就取每个表里面的数据吧。
很多人总是疑惑为什么分页越往后面越慢(按时间不怕,我们就是按时间分表的,你去对应时间区里面取就好了)
比如按字段1排序,每一页20条数据,要求取第一页的数据==》
取第五页的数据==》想想看,这么搞的话,怎么不卡?你们有更好的解决方法可以说,小子比较菜O(∩_∩)O
(⊙o⊙)…,最后说下我最近在研究的解决方案:
分布式数据库访问层:携程DAL ,支持MySQL,SQLServer。支持Net,Java
Ctrip DAL支持流行的分库分表操作,支持Java和C#,支持Mysql和MSSqlServer。使用该框架可以在有效地保护企业已有数据库投资的同时,迅速,可靠地为企业提供数据库访问层的横向扩展能力。
开源地址:https://github.com/ctripcorp/dal
文档系列:https://github.com/ctripcorp/dal/wiki/
这个是后备方案:(下午让朋友去问了一些MyCat的作者,他说MyCat开发的时候就没有限定数据库和开发语言,MySQL,SQLServer都是支持的,换个端口而已,开发语言也没什么限制,只要你能连接MyCat就能用)
数据库中间组件:MyCat (我还没研究,改天要是可以就发篇文章)
文档:https://github.com/MyCATApache/Mycat-doc
开源地址:https://github.com/MyCATApache/Mycat-Server





















04.SQLServer性能优化之---读写分离&数据同步 http://www.cnblogs.com/dunitian/p/6041758.html