SIGAI特约作者:沪东三哥
原创声明:本文为SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。
何为OCR ?
OCR的全称为“Optical Character Recognition” 中文翻译为光学字符识别。它是利用光学技术和计算机技术把印在或写在纸上的文字读取出来,并转换成一种计算机和人都能够理解的形式的过程。
先来看一个简单的OCR的流程:
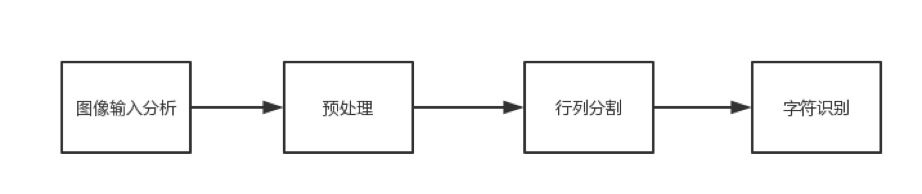
第一步,通过图像信息采集(一般就是相机),得到包含了待识别字符的图像,分析结构。
第二步,运用阈值操作等一些图像处理的方法对待测对象进行去噪和矫正。
第三步,因为文本信息的特殊性质,需要进行行列分割,对单个字符,或者是连续几个字符进行检测。
第四步,将分割后的字符图像导入识别模型中进行处理,进而得到原图中的字符信息。
场景文本识别
对于印刷字体的OCR技术如今已经相当成熟了。腾讯TIM的手机版就自带有图像文字提取的功能,微软的Office Lens的各种扫描功能呢等等,虽然不能说是百分之百正确,但是95%以上的印刷字体识别基本都是可以做到了。所以现在技术上关注的更多的是“场景文本识别”,也就是复杂环境下的字符信息的识别,如下面几张图所示。

对于复杂环境中的字符的识别,主要包括文字检测和文字识别两个步骤,这里介绍的CTPN(Detecting Text in
Natural Image with Connectionist Text Proposal Network)方法就是在场景中提取文字的一个效果较好的算法,能将自然环境中的文本信息位置加以检测。
涉及到了图像中位置信息的选择,很容易联想到之前用于目标检测的R-CNN的模型。毕竟CNN(Convolutional Neural Network)在这两年的图像处理上一枝独秀已经“深入人心”。那么把“字符位置”标记成一类,然后直接放入CNN模型处理岂不美哉?不过,现实总不会这么美好,文字的多种情况、字体,以及大面积的文字信息的位置,都对我们直接用R-CNN的方法产生了干扰,让结果产生严重的偏差。应对于此,一类结合CNN优势,专门应对环境文本信息的模型也就因运而生了,CTPN正是其中的佼佼者。
CTPN算法概述
言归正传,那么算法上文本位置的准确界定是怎么做到的呢?
首先,明确待检测的目标的特点,无论是图3还是图4的样例,文字信息的特点在于它是一个序列,是由“字符、字符的一部分、多字符”组成的一个sequence。所以这个目标显然不像我们一般的目标检测中的对象那样是独立和封闭的,所以不妨使用前后关联的序列的方法,比如说RNN (Recurrent Neural Networks),利用前后文的信息来进行文本位置的测定。

另外很重要的一点是,作者认为预测文本水平方向的位置比预测竖直方向上的位置要困难得多。所以检测的过程中
不妨引入一个类似数学上“微分”的思想,如下图5所示,先检测一个个小的、固定宽度的文本段。在后处理部分再将这些小文本段连接起来,得到文本行。
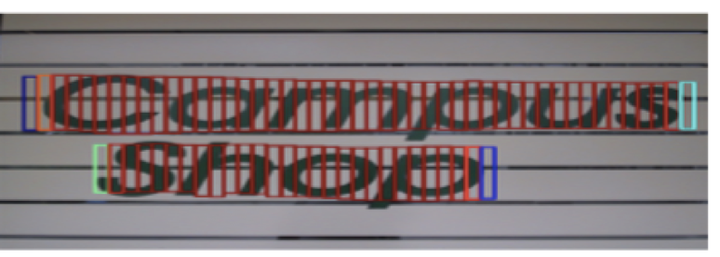 图5 “微分”示意图
图5 “微分”示意图
有了CNN和RNN结合,以及数学上”微分”思想处理文字段这样的奇思妙想之后,接下来就看作者是如何将其实现的了。具体流程图如下,然后分别进行介绍。
过程的图像如下图6:
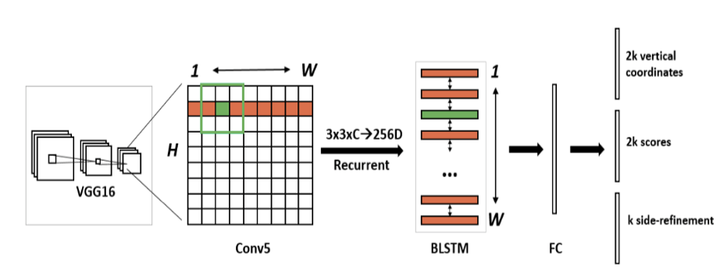 图6算法流程示意图
图6算法流程示意图
具体的步骤为:
1. 首先,用VGG16的前5个Conv stage得到feature map,大小为W*H*C
2. 用3*3的滑动窗口在前一步得到的feature map上提取特征,利用这些特征来对多个anchor进行预测,这里anchor定义与之前faster-rcnn中的定义相同,也就是帮我们去界定出目标待选区域。
3. 将上一步得到的特征输入到一个双向的LSTM中,输出W*256的结果,再将这个结果输入到一个512维的全连接层(FC).
4. 最后通过分类或回归得到的输出主要分为三部分,根据上图从上到下依次为2k vertical coordinates:表示选择框的高度和中心的y轴的坐标;2k scores:表示的是k个anchor的类别信息,说明其是否为字符;k side-refinement表示的是选择框的水平偏移量。本文实验中anchor的水平宽度都是16个像素不变,也就是说我们微分的最小选择框的单位是 “16像素”。
5. 用文本构造的算法,将我们得到的细长的矩形(如下图7),然后将其合并成文本的序列框。
 图7 回归的长矩形框
图7 回归的长矩形框
核心方法
具体的流程已经介绍完毕了,而这些流程中有很多作者提出的实现方法需要特别关注,名称(按照论文)分别是:Detecting Text in Fine-scale proposals(选择出anchor,也就是待选的”矩形微分框“)、Recurrent Connectionist Text Proposals(双向LSTM,利用上下文本信息的RNN过程)、Side-refinement(文本构造,将多个proposal合并成直线)。
Detecting Text in Fine-scale proposals:
和faster-rcnn中的RPN的主要区别在于引入了”微分“思想,将我们的的候选区域切成长条形的框来进行处理。k个anchor(也就是k个待选的长条预选区域)的设置如下:宽度都是16像素,高度从11~273像素变化(每次乘以1.4),也就是说k的值设定为10。最后结果对比如下:

图8 Fine-scale text的对比
本文使用的方法回归出来的y轴坐标结果如下:
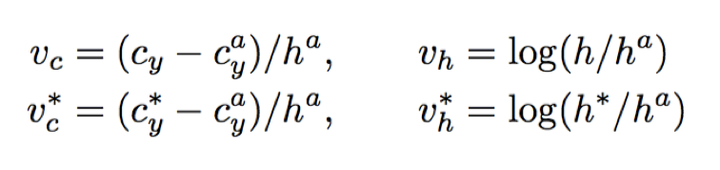
其中标记*的表示为真值;v = {vc,vh} 表示一个预测的框选位置,因为长度固定(之前确定的16像素),vc表示的是该预选框在y轴上的中心位置,vh表示这个预选框的高度。
Recurrent Connectionist Text Proposals:
其方法对应的就是之前流程中的”双向LSTM“对应的细节,将前后文的信息用到文本位置的定位当中。其中BLSTM有128个隐含层。输入为3*3*C滑动窗口的feature,输出为每个窗口所对应的256维的特征。简要表示如下:
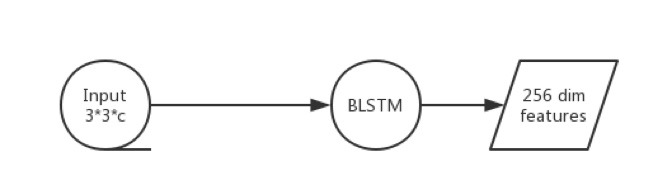 图9 输入输出示意图
图9 输入输出示意图
下面是使用RNN和不使用RNN的效果对比图。
 图10 RNN效果对比图
图10 RNN效果对比图
Side-refinement:
先进行文本位置的构造,Side-refinement是最后进行优化的方法。对定位出来的“小矩形框”加以合并和归纳,可以得到需要的文本信息的位置信息。我们最后保留的小矩形框是需要score>0.7的情况,也就是将下图中的红色小矩形框合并,最后生成黄色的大矩形框。
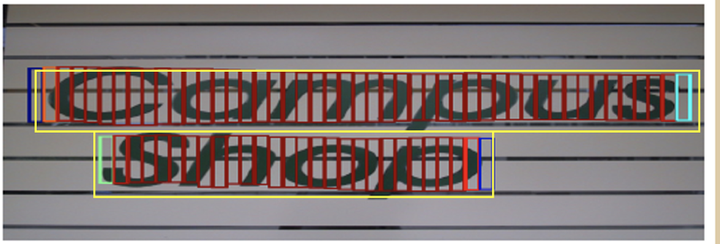 图11 小区域分割示意图
图11 小区域分割示意图
主要的思路为:每两个相近的proposal(也就是候选区)组成一个pair,合并不同的pair直到无法再合并为止。而判断两个proposal,Bi和Bj可以组成一个pair的条件为Bi—>Bj,同时Bj—>Bi;该符号的判定条件见下图。
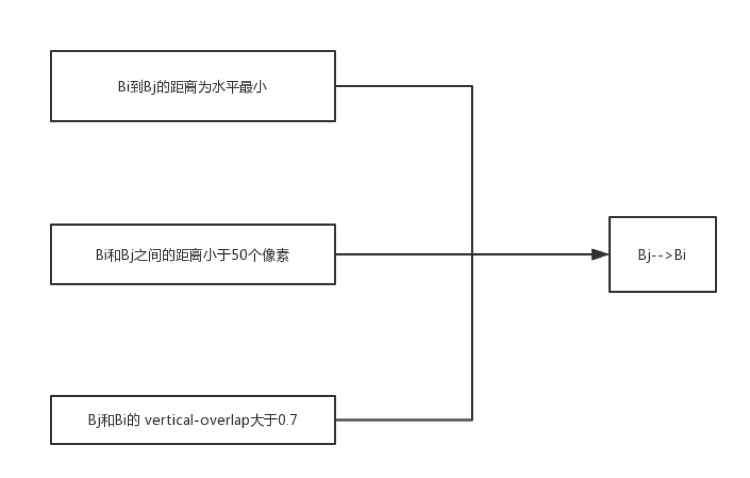 图12 可合并区域判定示意图
图12 可合并区域判定示意图
因为这里规定了回归出来的box的宽度是16个像素,所以会导致一些位置上的误差,这时候就是Side-refinement发挥作用的时候
了。定义的式子如下:
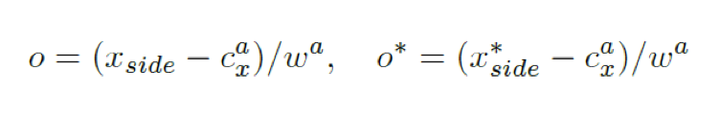
其中带*表示为GroundTruth.。 表示回归出来的左边界或者右边界,
表示anchor中心的横坐标,
是固定的宽度16像素。所以O的定义相当于是一个缩放的比例,帮助我们去拉伸回归之后的box的结果,从而更好地符合实际文本的位置。对比图如下,红色框是使用了side-refinement的,而黄色框是没有使用side-refinement方法的结果:
 图13 Side-refinement结果对比
图13 Side-refinement结果对比
纵观整个流程,该方法的最大两点也是在于将RNN引入了文本检测之中,同时将待检测的结果利用“微分”的思路来减少误差,使用固定宽度的anchor来检测分割成许多块的proposal.最后合并之后的序列就是我们需要检测的文本区域。CNN和RNN的高效无缝衔接极大提升了精度,实验对比如下表所示:
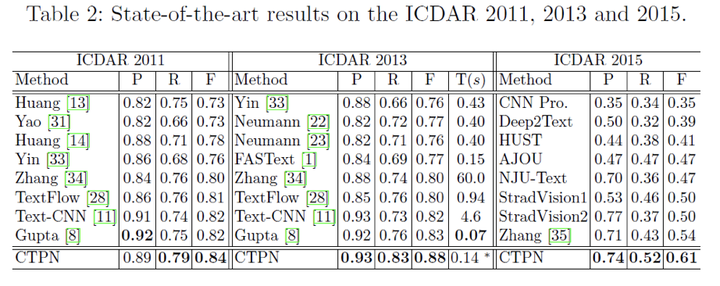 表1 实验结果与其他方法的对比
表1 实验结果与其他方法的对比
说明
1. 论文: https://arxiv.org/pdf/1609.03605.pdf
2. 代码: https://github.com/eragonruan/text-detection-ctpn
(搬运,实测运行可靠,是有人根据faster-r-cnn的tensorflow版本进行 改写的,具体的训练和测试请参阅git上的readme)
3. 除流程图外其他配图和表格信息均来自原文 “Detecting Text in Natural Image with Connectionist Text Proposal Network”
参考文献
[1] Ren, S., He,K., Girshick, R., & Sun, J. (2015). Faster R-CNN: towards real-time object
detection with region proposal networks. International Conference onNeural Information Processing Systems (Vol.39, pp.91-99). MIT Press.
[2] sTian,Z., Huang, W., He, T., He, P., & Qiao, Y. (2016). Detecting Text in Natural Image with Connectionist Text Proposal Network. European Conference on Computer Vision (pp.56-72). Springer, Cham.
[3] Olah C(2015). Understanding LSTM networks.blog, http://colah.github.io/posts/2015-08-Understanding-LSTMs/, August 27, 2015.
推荐文章
[1] 机器学习-波澜壮阔40年 SIGAI2018.4.13.
[2] 学好机器学习需要哪些数学知识?SIGAI 2018.4.17.
[3] 人脸识别算法演化史 SIGAI2018.4.20.
[4] 基于深度学习的目标检测算法综述 SIGAI2018.4.24.
[5] 卷积神经网络为什么能够称霸计算机视觉领域? SIGAI2018.4.26.
[6] 用一张图理解SVM的脉络 SIGAI2018.4.28.
[7] 人脸检测算法综述 SIGAI2018.5.3.
[8] 理解神经网络的激活函数 SIGAI2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 SIGAI2018.5.8.
[10] 理解梯度下降法 SIGAI2018.5.11.
[11] 循环神经网络综述—语音识别与自然语言处理的利器 SIGAI2018.5.15
[12] 理解凸优化 SIGAI2018.5.18
[13]【实验】理解SVM的核函数和参数 SIGAI 2018.5.22
[14] 【SIGAI综述】行人检测算法 SIGAI2018.5.25
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上) SIGAI2018.5.29
[16] 理解牛顿法 SIGAI2018.5.31
[17]【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题 SIGAI 2018.6.1
[18] 大话Adaboost算法 SIGAI2018.6.2
[ 19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法 SIGAI2018.6.4
[20] 理解主成分分析(PCA) SIGAI2018.6.6
[21] 人体骨骼关键点检测综述 SIGAI2018.6.8
[22] 理解决策树 SIGAI2018.6.11
[23] 用一句话总结常用的机器学习算法 SIGAI2018.6.13
[24] 目标检测算法之YOLO SIGAI2018.6.15
[25] 理解过拟合 SIGAI 2018.6.18
[26] 理解计算:从√2到AlphaGo ——第1季 从√2谈起 SIGAI2018.6.20
原创声明:本文为SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。 