产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
开发者社区
首页
探索云世界
探索云世界
云上快速入门,热门云上应用快速查找
了解更多
问产品
动手实践
考认证
TIANCHI大赛
活动广场
活动广场
丰富的线上&线下活动,深入探索云世界
任务中心
做任务,得社区积分和周边
高校计划
让每位学生受益于普惠算力
训练营
资深技术专家手把手带教
话题
畅聊无限,分享你的技术见解
开发者评测
最真实的开发者用云体验
乘风者计划
让创作激发创新
阿里云MVP
遇见技术追梦人
直播
技术交流,直击现场
下载
下载
海量开发者使用工具、手册,免费下载
镜像站
极速、全面、稳定、安全的开源镜像
技术资料
开发手册、白皮书、案例集等实战精华
插件
为开发者定制的Chrome浏览器插件
探索云世界
新手上云
云上应用构建
云上数据管理
云上探索人工智能
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
热门
Modelscope模型即服务
弹性计算
云原生
数据库
物联网
云效DevOps
龙蜥操作系统
平头哥
钉钉开放平台
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
支持服务
镜像站
码上公益
开发者社区
大数据
文章
正文
Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析
2018-06-23
1571
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议
》和 《
阿里云开发者社区知识产权保护指引
》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单
进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
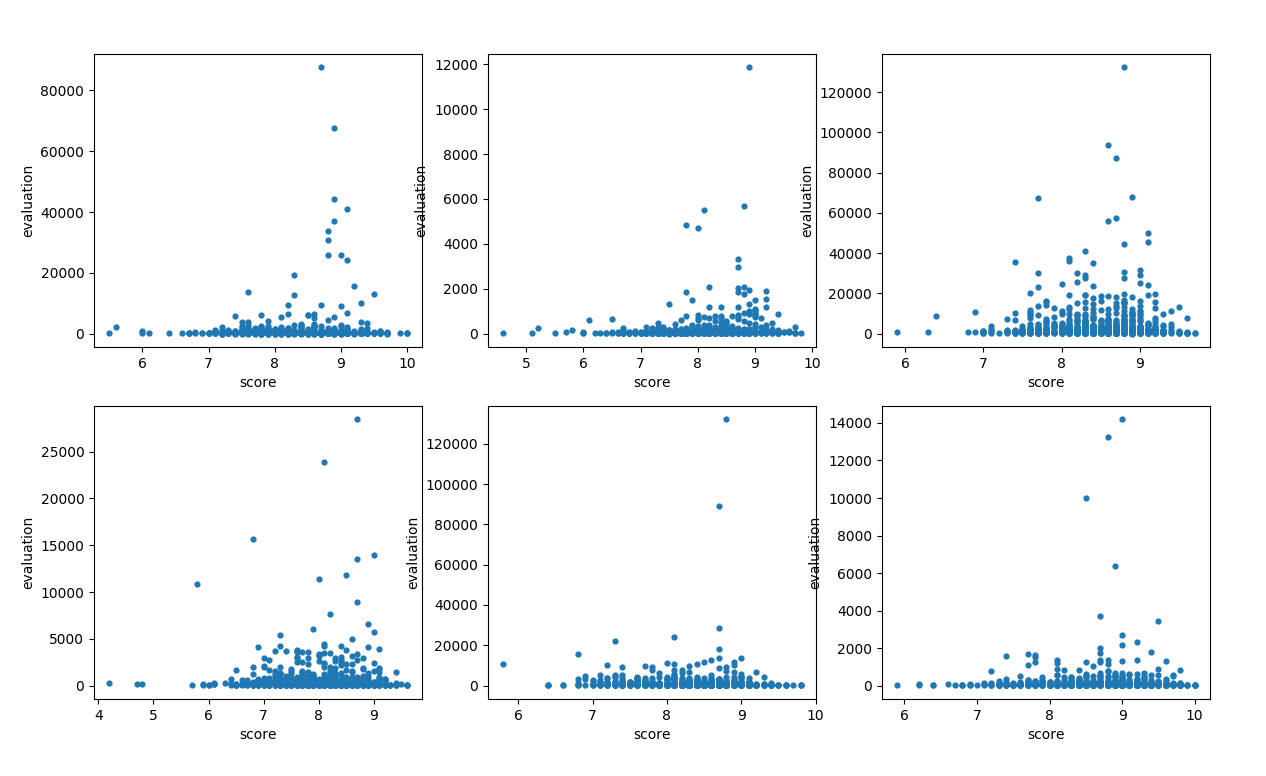
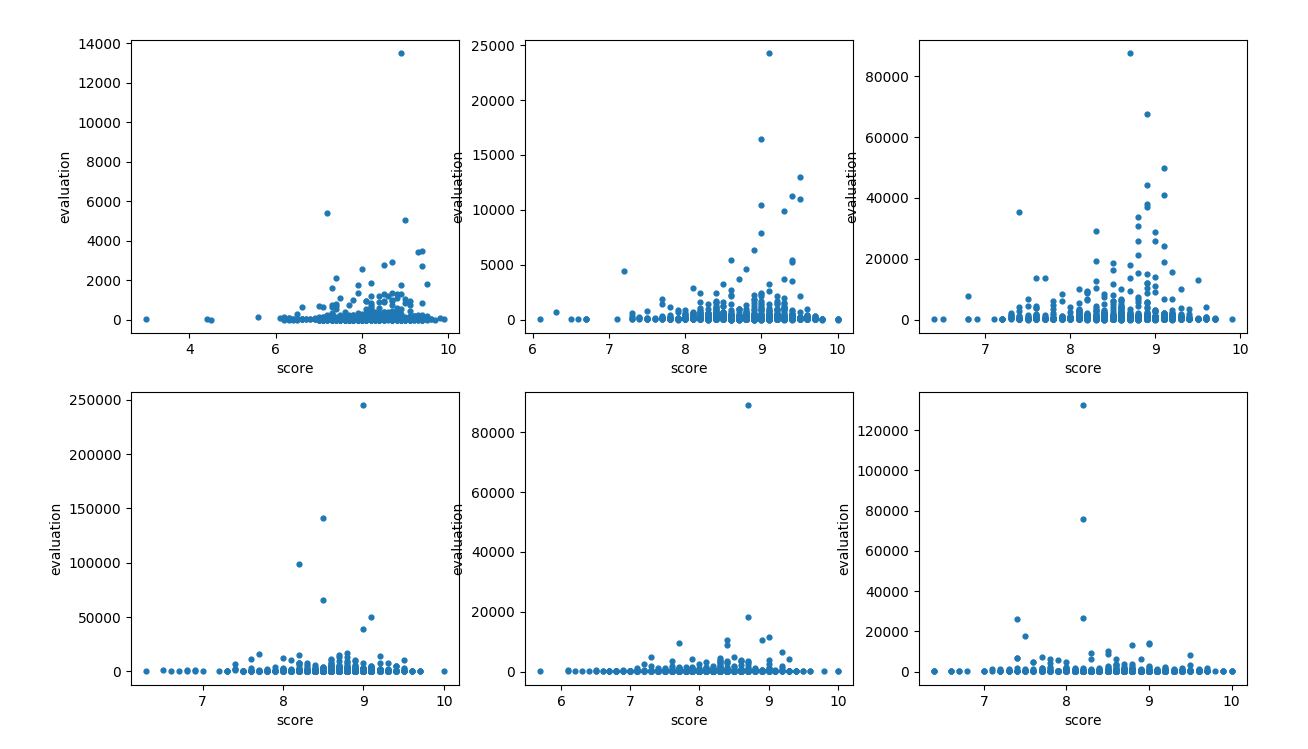
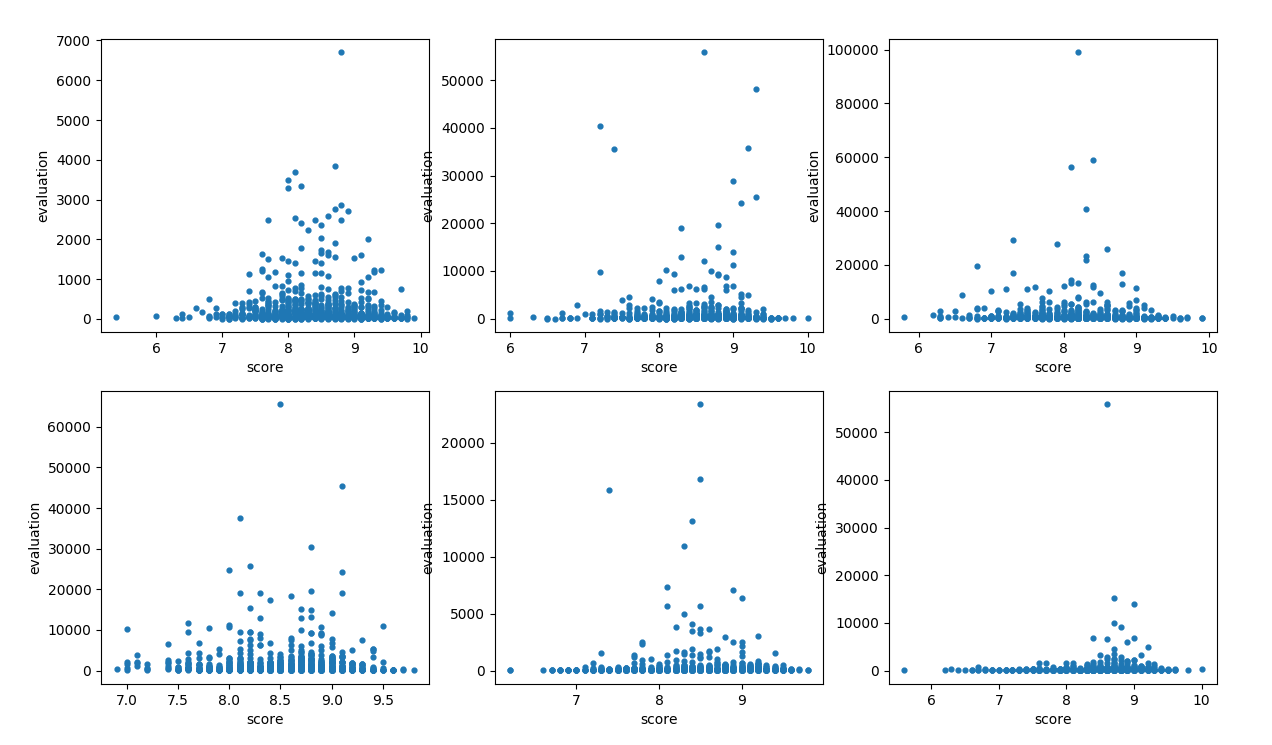
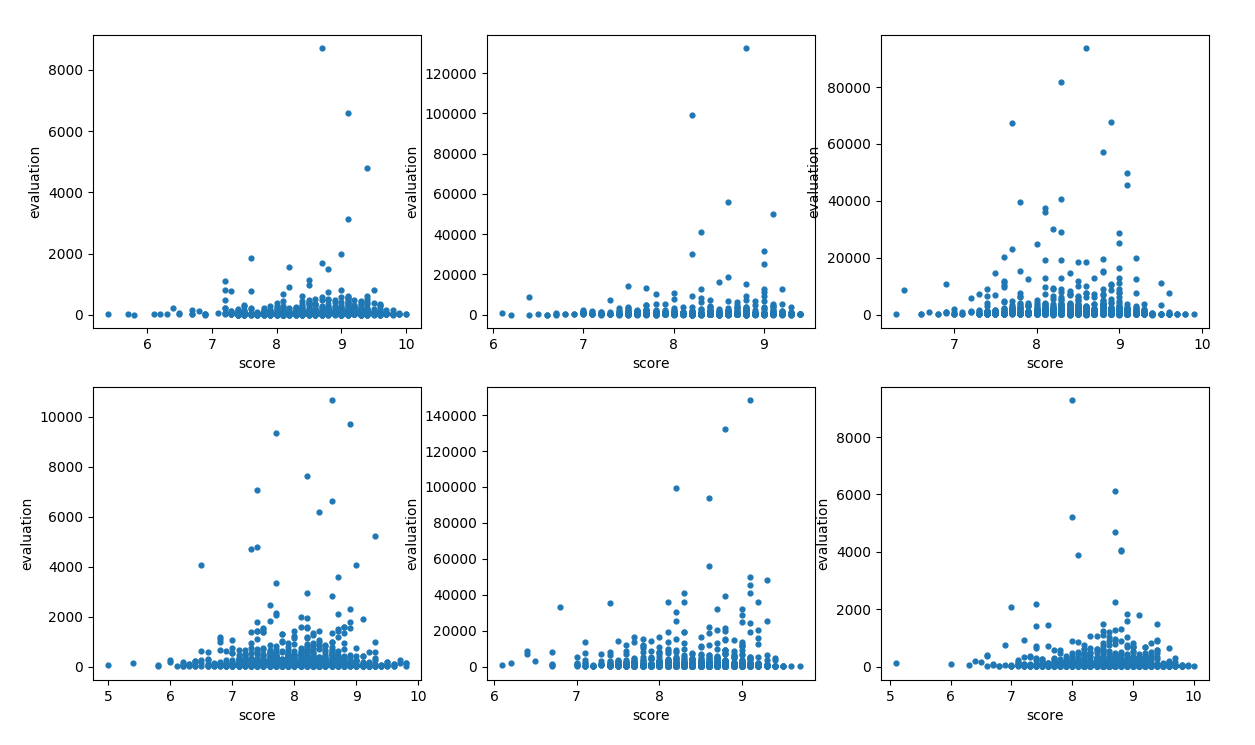
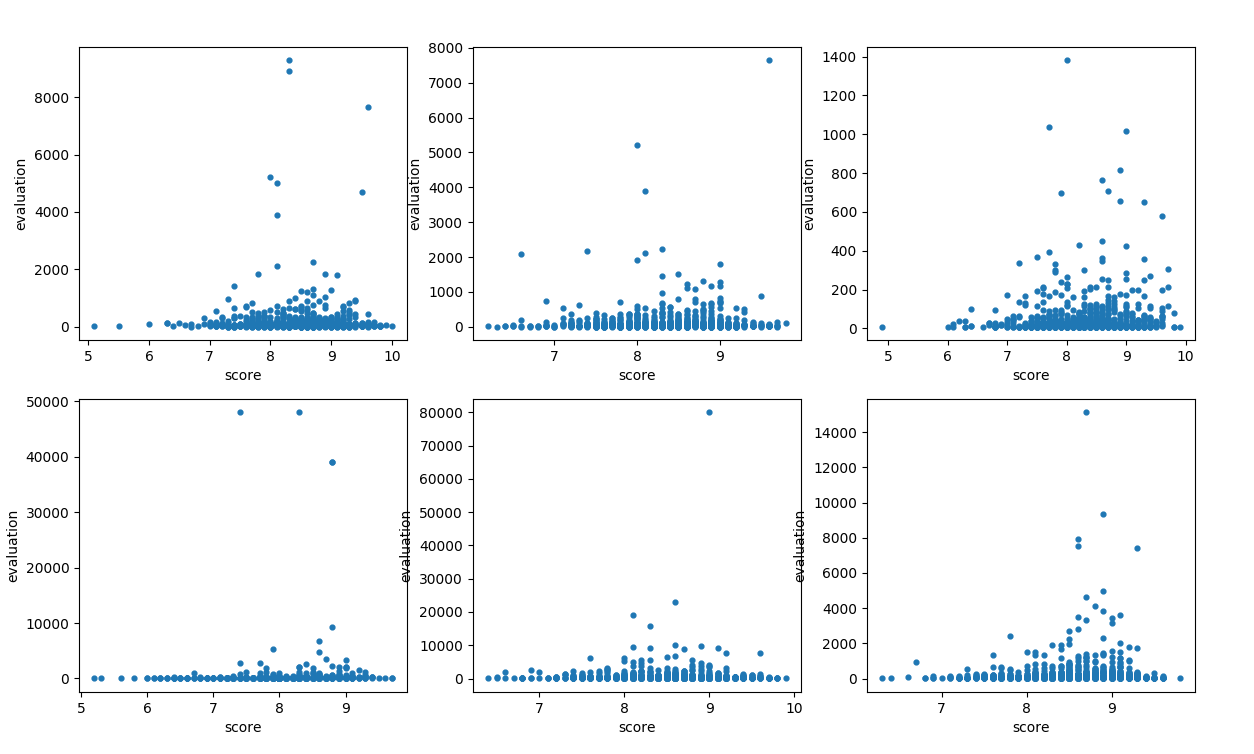
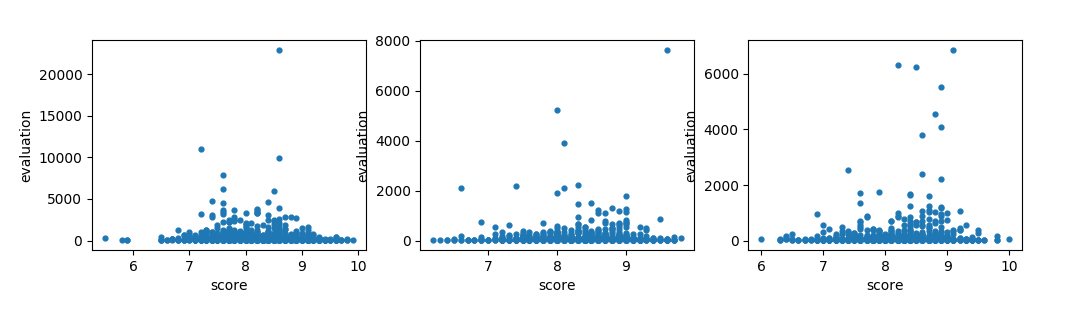
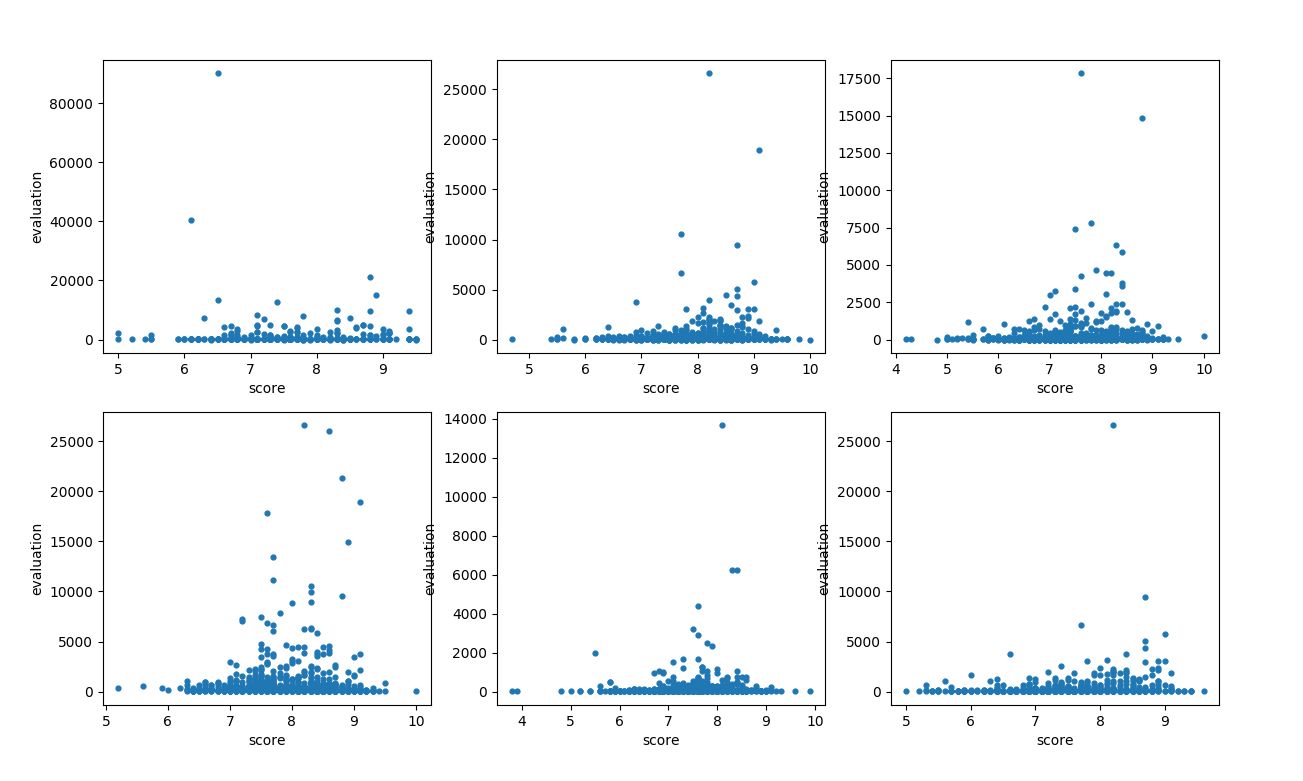
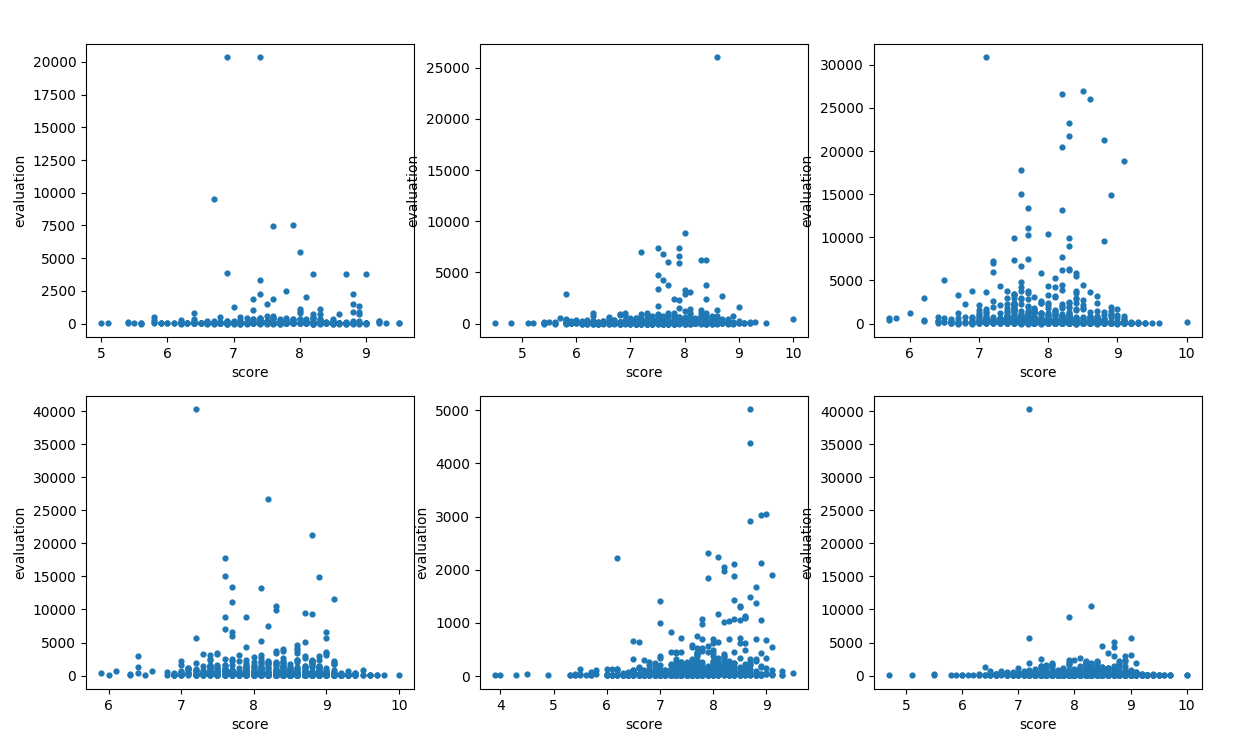
文化 经管 ....略 结论: 一个模块的评分与评论数相关,评分为 [8.8——9.2] 之间的书籍评论数往往是模块中最多的
文化
经管
....略
结论: 一个模块的评分与评论数相关,评分为 [8.8——9.2] 之间的书籍评论数往往是模块中最多的
文章标签:
Python
数据采集
关键词:
Python分析
Python模块
爬虫python
Python爬虫
Python评分
奶berber
目录
相关文章
桃李春风一杯酒
|
13天前
|
数据采集
存储
API
网络爬虫与数据采集:使用Python自动化获取网页数据
【4月更文挑战第12天】本文介绍了Python网络爬虫的基础知识,包括网络爬虫概念(请求网页、解析、存储数据和处理异常)和Python常用的爬虫库requests(发送HTTP请求)与BeautifulSoup(解析HTML)。通过基本流程示例展示了如何导入库、发送请求、解析网页、提取数据、存储数据及处理异常。还提到了Python爬虫的实际应用,如获取新闻数据和商品信息。
桃李春风一杯酒
33
2
2
java开发-郭老师
|
17天前
|
数据采集
Python
【python】爬虫-西安医学院-校长信箱
本文以西安医学院-校长信箱为基础来展示爬虫案例。来介绍python爬虫。
java开发-郭老师
19
0
0
1941623231718325
|
24天前
|
存储
开发者
Python
Python中的collections模块与UserDict:用户自定义字典详解
【4月更文挑战第2天】在Python中,`collections.UserDict`是用于创建自定义字典行为的基类,它提供了一个可扩展的接口。通过继承`UserDict`,可以轻松添加或修改字典功能,如在`__init__`和`__setitem__`等方法中插入自定义逻辑。使用`UserDict`有助于保持代码可读性和可维护性,而不是直接继承内置的`dict`。例如,可以创建一个`LoggingDict`类,在设置键值对时记录操作。这样,开发者可以根据具体需求定制字典行为,同时保持对字典内部管理的抽象。
1941623231718325
25
0
0
didiplus
|
23天前
|
数据采集
安全
Python
python并发编程:Python实现生产者消费者爬虫
python并发编程:Python实现生产者消费者爬虫
didiplus
24
0
0
1941623231718325
|
25天前
|
存储
缓存
算法
Python中collections模块的deque双端队列:深入解析与应用
在Python的`collections`模块中,`deque`(双端队列)是一个线程安全、快速添加和删除元素的双端队列数据类型。它支持从队列的两端添加和弹出元素,提供了比列表更高的效率,特别是在处理大型数据集时。本文将详细解析`deque`的原理、使用方法以及它在各种场景中的应用。
1941623231718325
31
4
5
ohh.
|
2天前
|
开发者
Python
Python的os模块详解
Python的os模块详解
ohh.
15
0
0
长梦
|
3天前
|
数据采集
存储
JSON
Python爬虫面试:requests、BeautifulSoup与Scrapy详解
【4月更文挑战第19天】本文聚焦于Python爬虫面试中的核心库——requests、BeautifulSoup和Scrapy。讲解了它们的常见问题、易错点及应对策略。对于requests,强调了异常处理、代理设置和请求重试;BeautifulSoup部分提到选择器使用、动态内容处理和解析效率优化;而Scrapy则关注项目架构、数据存储和分布式爬虫。通过实例代码,帮助读者深化理解并提升面试表现。
长梦
13
0
0
阿文没烦恼
|
6天前
|
数据挖掘
API
数据安全/隐私保护
python请求模块requests如何添加代理ip
python请求模块requests如何添加代理ip
阿文没烦恼
22
0
0
1941623231718325
|
7天前
|
数据采集
JavaScript
前端开发
使用Python打造爬虫程序之破茧而出:Python爬虫遭遇反爬虫机制及应对策略
【4月更文挑战第19天】本文探讨了Python爬虫应对反爬虫机制的策略。常见的反爬虫机制包括User-Agent检测、IP限制、动态加载内容、验证码验证和Cookie跟踪。应对策略包括设置合理User-Agent、使用代理IP、处理动态加载内容、验证码识别及维护Cookie。此外,还提到高级策略如降低请求频率、模拟人类行为、分布式爬虫和学习网站规则。开发者需不断学习新策略,同时遵守规则和法律法规,确保爬虫的稳定性和合法性。
1941623231718325
15
1
1
阿文没烦恼
|
7天前
|
测试技术
Python
Python 有趣的模块之pynupt——通过pynput控制鼠标和键盘
Python 有趣的模块之pynupt——通过pynput控制鼠标和键盘
阿文没烦恼
21
0
0
热门文章
最新文章
1
网络爬虫与数据采集:使用Python自动化获取网页数据
2
Rust高级爬虫:如何利用Rust抓取精美图片
3
掌握 C# 爬虫技术:使用 HttpClient 获取今日头条内容
4
python并发编程:Python实现生产者消费者爬虫
5
畅游网络:构建C++网络爬虫的指南
6
【python】爬虫-西安医学院-校长信箱
7
简单描述一下爬虫的工作原理。
8
Python爬虫如何快速入门
9
阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
10
使用Python实现DBSCAN聚类算法
1
Python中的装饰器:概念、用法和实例
18
2
Python中的装饰器:概念、用法及实例
17
3
使用Python实现图像处理中的边缘检测算法
46
4
Python中如何实现字符串反转?请提供至少两种方法。
17
5
在Python中,如何创建一个迭代器?
19
6
请解释Python中的迭代器和生成器的区别?并分别举例说明。
18
7
在Python中,如何使用装饰器重写类的方法?
22
8
Python中的装饰器:概念、用法及实例
18
9
Python中的装饰器:概念、应用与实例
16
10
Python中的装饰器:概念、用法和实例
19
相关课程
更多
Python Web开发基础
Python爬虫实战
Python常用数据科学库
Python网络爬虫实战
Python完全自学手册图文教程
Python基础快速入门实战教程
相关电子书
更多
From Python Scikit-Learn to Sc
Data Pre-Processing in Python:
双剑合璧-Python和大数据计算平台的结合
相关实验场景
更多
函数计算进阶-IP查询工具开发
小试牛刀,一键部署电商商城
推荐系统入门之使用协同过滤实现商品推荐
Python新手入门
Python入门
一键创建和部署高分电影推荐语音技能
下一篇
部署LAMP环境(Alibaba Cloud Linux 3)