
引言:
日志向来都是运维以及开发人员最关心的问题。运维人员可以及时的通过相关日志信息发现系统隐患、系统故障并及时安排人员处理解决问题。开发人员解决问题离不开日志信息的协助定位。没有日志就相当于没有了眼睛,失去了方向。
微服务日渐火热,享受微服务架构带来的种种好处的同时也要承担起由微服务带来的种种困扰。日志管理就是其中一个。微服务有一个很大的特色:分布式。 分布式部署的结果就导致日志信息散落在各地,这样就给日志的采集存储带来了一定的挑战:
这篇文章将探讨一下日志管理的相关问题。
目录:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程与实现
四、日志中心的关键配置
五、总结
一、日志的重要性和复杂性
要说管日志,在管日志之前有一个先决条件,我们需要知道日志是什么,能做什么,有什么用。援引百度百科的话,它是记录系统操作事件的记录信息。
在日志文件内部记录了当前系统的各项生命体征,就像我们在医院体检过后拿到的体检单,上面反应了我们的肝功能、肾功能、血常规等的具体指标。日志文件在应用系统中的作用就如同体检单,它反应了系统的健康状态、系统的操作事件、系统的变更状况。
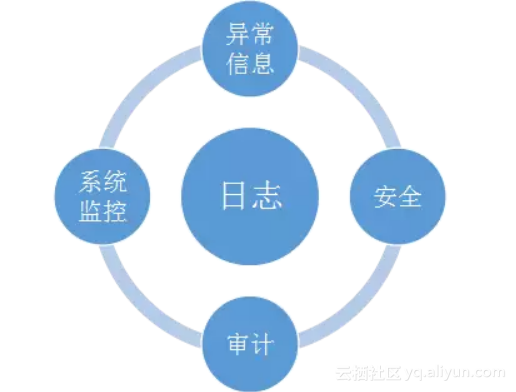
日志在系统中扮演着监护人的身份,它是保障高可靠服务的基础,记录了系统的一举一动。运维层面、业务层面、安全层面都有日志的身影,系统监控、异常处理、安全、审计等都离不开日志的协助。
日志种类繁杂,一个健壮的系统可能会有着各种各样的日志信息。

如此复杂多样的日志,是否要一网打尽?哪些又是我们所需要的?这都是我们在设计日志中心架构时需要考虑的问题。
二、基于微服务的
日志中心架构设计
日志中心是微服务生态中不可或缺的一环,是监控的二当家。在此分享一下我们的产品级设计实践,了解一下,在基于微服务的架构,日志中心在技术架构中所处的位置是怎样的,以及如何部署。
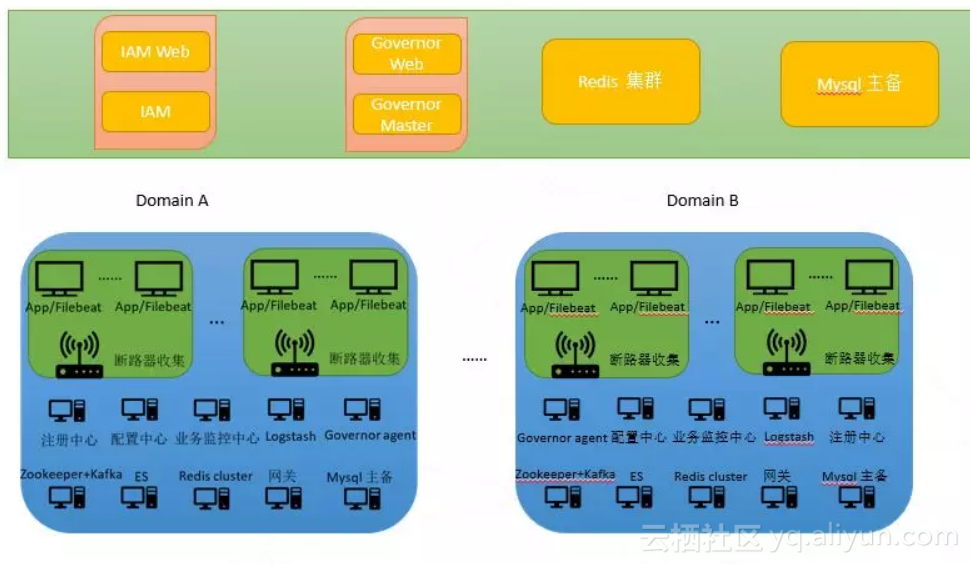
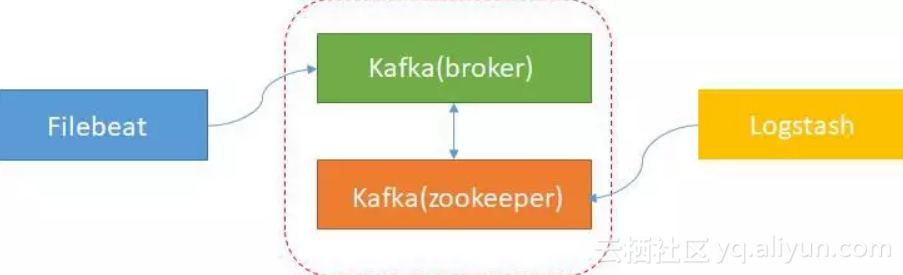
在这一设计中,微服务结构由以下几部分组成:
图片中并没有日志中心这四个关键字,因为他是由多个独立组件共同协同构成的。这些组件分别是Filebeat、Kafka、Logstash、Elastic search,他们共同构成了日志中心。
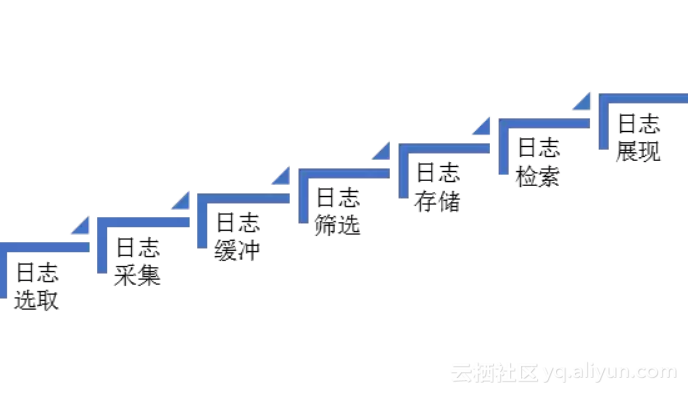
我们经过考量研究确定了一套适用于当下微服务架构日志管理流程。
1. 日志选取 ---- 确定选择哪些日志记录分析
2. 日志采集 ---- filebeat轻巧做收集
3. 日志缓冲 ---- kafka缓存本地做缓冲
4. 日志筛选 ---- logstash筛选过滤
5. 日志存储 ---- elasticsearch建索引入库
6. 日志检索 ---- 利用elasticsearch本身的检索功能
7. 日志展现 ---- 参考kibana风格实现日志数据可视化
在传统的ELK上替换了Logstash做日志采集的部分采取Filebeat,在日志存储前多了kafka缓冲和logstash筛选。这一套流程在保障功能完备同时提高性能、尽可能做到轻量部署。
三、日志中心的流程与实现
选择:以业务场景为原则
日志内容复杂多样,如何去收集有价值的日志是我们重点关注的。日志的价值其实是取决于业务操作的,不同的业务场景下相同类型的日志的价值会截然不同。
根据以往的业务实践,结合企业级的一些业务需求,我们选定关注以下几类日志。
• 跟踪日志【trace.log】 Server引擎的调试日志,用于系统维护人员定位系统运行问题使用。
• 系统日志【system.log】 大粒度的引擎运行的入口、出口的日志,用于调用栈分析,可以进行性能分析使用。
• 部署日志【deploy.log】 记录系统启动、停止、构件包部署、集群通知等信息的日志。
• 引擎日志【engine.log】 细粒度的引擎运行日志,可以打印上下文数据,用于定位业务问题。
• 构件包日志【contribution.log】 构件包记录的业务日志(使用基础构件库的日志输出API写日志)
通过以上几种日志,我们可以在分析问题时明确我们要查找的位置,通过分类缩小查找范围提高效率。
采集(Filebeat):侧重考虑轻量级
微服务应用会分布在各个域内的各个系统。应用的日志也就相对应的产生在各个域内的各个系统。进行日志管理首先要做好日志的采集工作。日志采集工作我们选择Elastic Stack中的Filebeat。
-
Filebeat是一个开源的文件采集器,基于go语言开发,不需要java环境,它是对logstash的重构产物。Filebeat对环境依赖很低比较亲民。
-
Filebeat是一个轻量的采集器,最新版的Filebeat体积大约是20M左右,而logstash有近百兆。Filebeat更利于部署实施,减轻宿主压力。
-
之前曾有对filebeat和logstash的测试对比,在采集日志方面,filebeat比logstash花费更少CPU和内存。Filebeat在日志采集方面有更好的性能表现。
Filebeat和应用是挂钩的,因为我们需要知道针对每个落点去收集日志信息,所以轻量其实是我们考量的主要因素。
Filebeat会有一个或者多个的叫做Prospector的探测器,可以实时监听指定的文件或者制定的文件目录的变更状况,将变更状况及时的传递到下一层---Spooler处理。
Filebeat还有一个特性我们放到日志筛选那里进行介绍,它是定位来源的关键。
这两点刚好满足我们实现日志的实时采集的需求。通过Filebeat动态的将新增的日志进行及时存储取样。至此如何采集日志信息的问题已经可以完美解决。
缓冲(Kafka):吞吐量大、易扩展、上限高
在日志存储之前,我们引入了一个组件--- Kafka,作为日志缓冲层。 Kafka起一个缓冲的作用,避免高峰期应用对ES的冲击。造成由于ES瓶颈问题而引发数据丢失问题。同时它也起到了数据汇总的功能。
选用kafka来做日志缓冲有几个优点:
![]() Kafka的性能主要取决于它对磁盘的连续读写,它的性能很大程度上是取决于磁盘处理的能力。可以说只要磁盘性能允许,它就可以无限制的接收来自Filebeat的日志信息,从而实现一个缓冲的作用。
Kafka的性能主要取决于它对磁盘的连续读写,它的性能很大程度上是取决于磁盘处理的能力。可以说只要磁盘性能允许,它就可以无限制的接收来自Filebeat的日志信息,从而实现一个缓冲的作用。

筛选(Logstash):提前埋点、方便定位
日志信息经过filebeat、kafka等工具的收集传递,给日志事件加了很多附加信息。利用Logstash实现二次处理,可在filter里进行过滤或处理。
我们在Filebeat收集信息的时候通过将同一个Server上的日志信息发送到同一个Kafka的topic中来实现日志的汇总,这个topic名称就是server的关键信息。在更细粒度的层面上你也可以将每一个App的信息都当作一个topic来进行汇总。Kafka中通过Filebeat接受到的日志信息中包含了一个标识---日志是从哪里来的。Logstash的作用就是在日志汇入ES之前,通过标识将对应的日志信息进行二次筛选汇总处理,输送给ES,为之后的搜索提供依据。方便我们清楚的定位问题。
存储(ES):方便扩展、上手简单
Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。

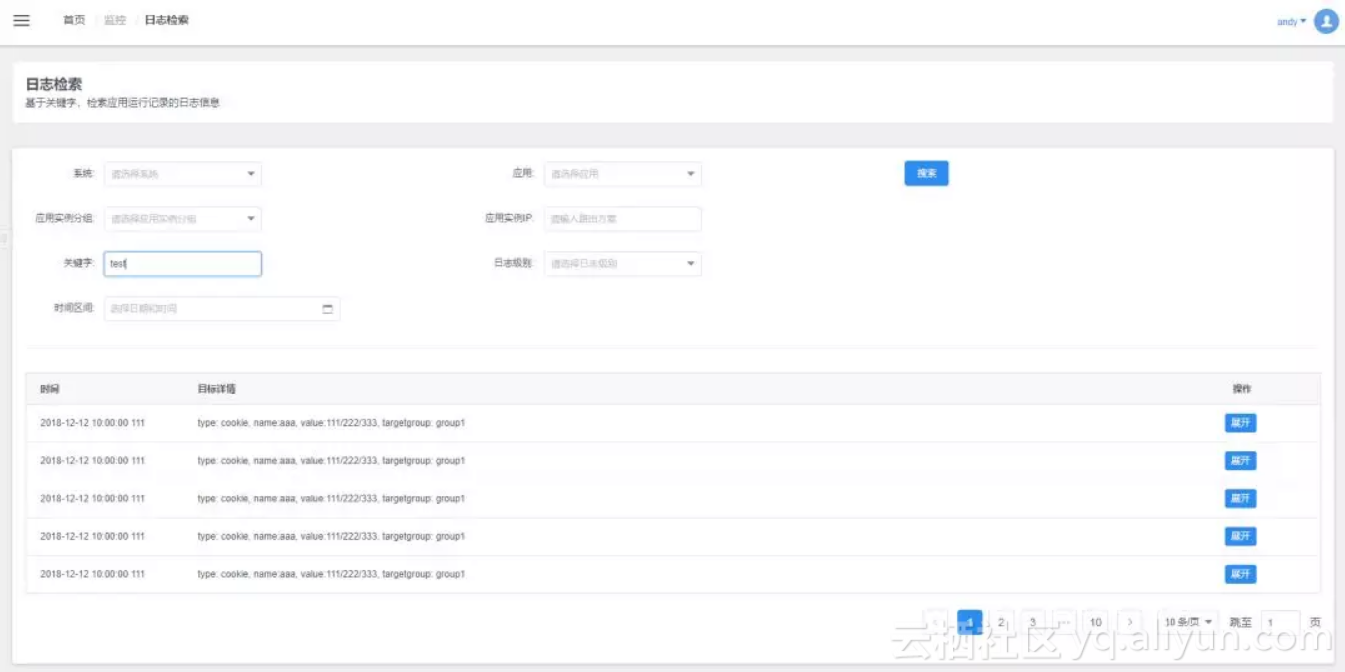
检索(ES):分门别类
Elasticsearch本身就是一个强大的搜索引擎,支持通过系统、应用、应用实例分组、应用实例IP、关键字、日志级别、时间区间来检索所需要的日志信息。
展现(Kibana):简单配置、清晰明了
查看密密麻麻的日志信息的时候,常常会有一种晕眩感。需要通过精简提炼日志信息,对日志信息进行整合分析,以图表的形式将日志信息进行展示。在展示的过程中我们可以借鉴和吸收Kibana在日志可视化方面的努力,实现日志的可视化处理,只需通过简单的配置就可以看到对某一个服务或者某一个应用的清晰的可视化的日志分析结果。
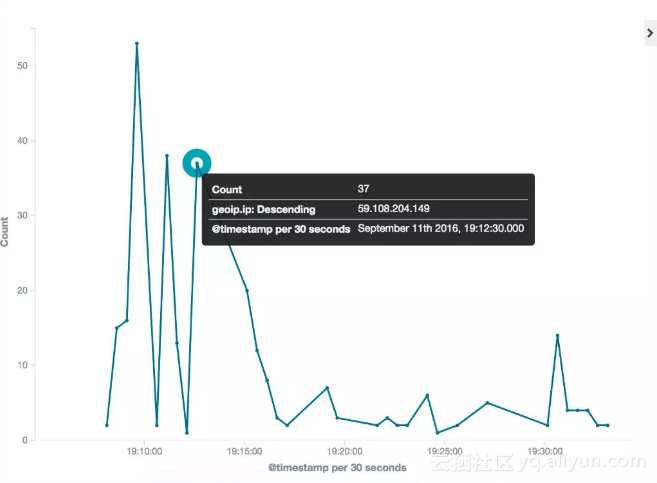
(注:图片摘自互联网
https://blog.csdn.net/my_bai/article/details/68062701 服务调用折线图)
四、日志中心的关键配置
在此就不再赘述关于各个组件的安装方法了,大家可以很轻松的从网络上找到相关教程。我们在这里介绍一些关键的配置,确保大家在安装过程中关键环节少走一些弯路。
Filebeat的关键配置
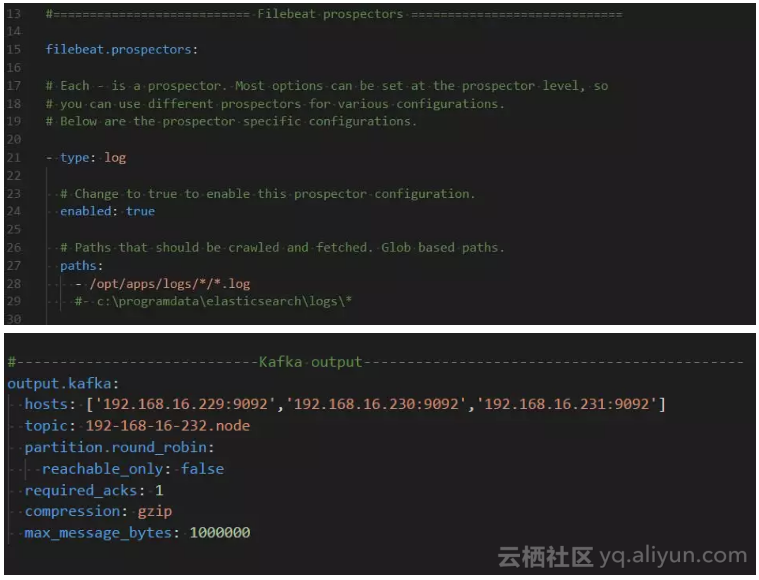
-
enabled配置为true,表示打开日志采集能力。
-
在path中配置文件路径或者是文件目录位置,支持多级搜索。
对于EOS的应用我们是这样做的:统一输出在/opt/apps/logs/目录下,如:/opt/apps/logs/应用ID/应用ID_system.log, /opt/apps/logs/应用ID/应用ID_trace.log
-
在output.kafka中配置输出对象。建议以自己的主机名作为topic名字,同一台机器上收取的各种日志会发送到kafka的同一个队列。
Kafka以及Zookeeper关键配置
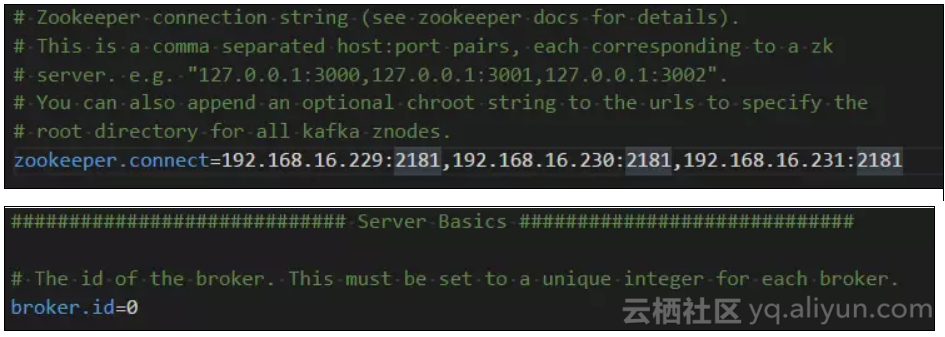
-
zookeeper.connect为zookeeper的集群地址
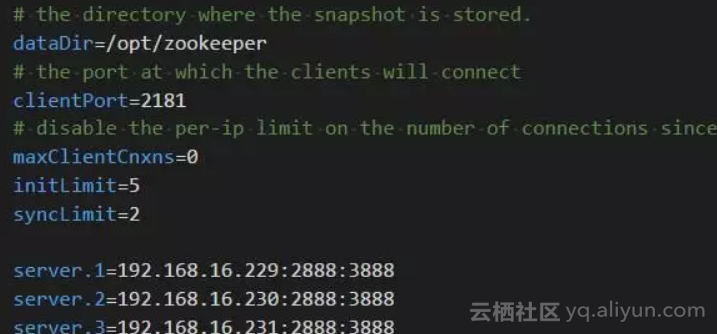
-
server.1,server.2, server.3,
注意和/opt/zookeeper/myid的内容里的数字一致用来标识server。
Logstash的关键配置
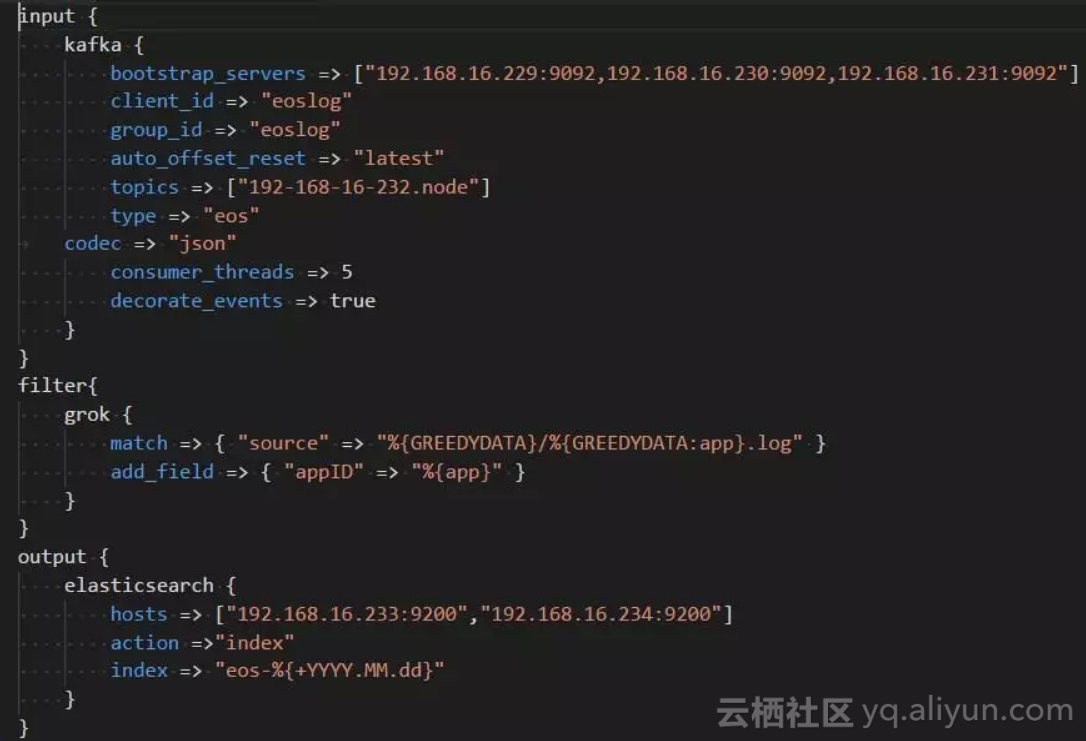
-
Input 配置数据源输入
-
Filter 将收取的源文件路径做截取,获取的文件名作为appid并将其存储在es数据中。作为后期筛选的标志。
-
Output 配置数据源输出,输出信息到elasticsearch中。
Elasticsearch关键配置
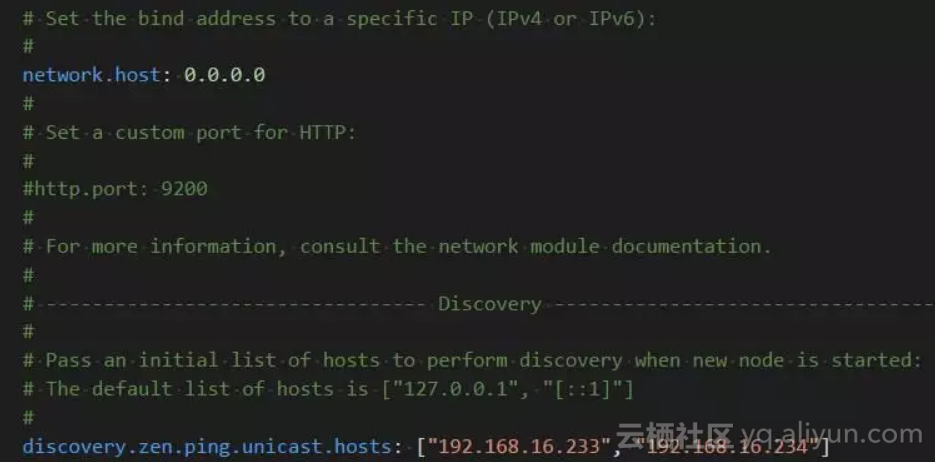
-
network.host 配置可访问es的地址,开发环境中配置为0.0.0.0代表允许任意一个ip访问,在生产环境中需配置为特定的ip,限制访问。
日志中心在微服务架构中起到了至关重要的作用,它是微服务监控的一个非常重要的切入点,本文以我们的团队技术实践为蓝本阐述了其设计、实现与关键配置,并详细阐述了日志管理的7个关键步骤和一些考量原则。
首先,在日志的选择上,要以业务场景为原则;选择之后的采集环节,可侧重考虑轻量级的Filebeat;在采集之后,选用吞吐量大的Kafka避免系统瓶颈造成的数据丢失;在存储之前,采用Logstash提前标识,便于问题的定位 ;充分利用ES和Kibana的功能来实现存储、检索和展现。
采用这样的架构和原则,我们可以通过日志中心提供对日志的实时采集、分析、展示能力。并通过日志中心可以及时了解系统性能、用户行为,保障微服务的高可靠运行。
原文发布时间为:2018-06-14
本文作者:赵瑞栋
