接着上一章我们讲的hive的连接策略,现在我们讲一下hive的数据存储。
下面是hive支持的数据存储格式,有我们常见的文本,JSON,XML,这里我们主要讲一下ORCFile。
Built-in Formats:
– ORCFile
– RCFile
– Avro
– Delimited Text
– Regular Expression
– S3 Logfile
– Typed Bytes
• 3
rd
-Party Addons:
– JSON
– XML
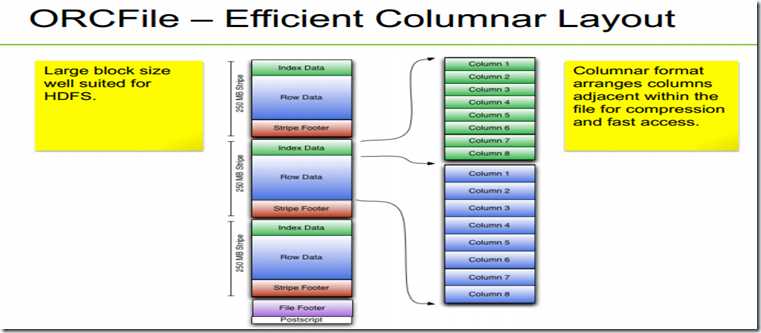
这种格式非常适合HDFS,它有以下的
优点:
•高压缩
– 高压缩比.
– 字典编码.
•高性能
– 自带索引.
– 高效的精确查询.
• 灵活的数据模型
– 支持所有的hive类型,包括maps.
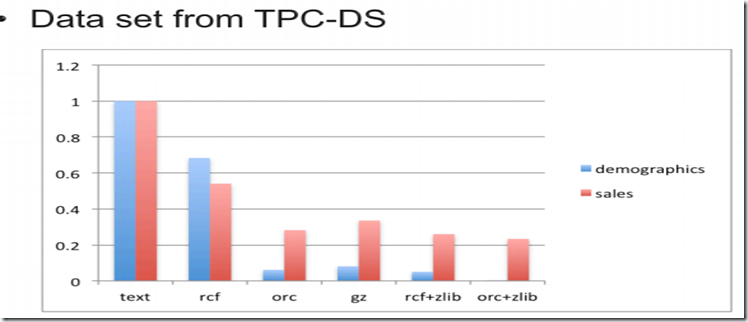
从图中可以看出,orc格式的文件存储大小仅为文本的30%左右,比gz格式的都小,采用zlib压缩的话,更小,仅有22%左右。
使用orc格式存储的方式很简单,在建表的时候STORED AS orc即可
CREATE TABLE sale(
id int, timestamp timestamp,
productsk int, storesk int,
amount decimal, state string
)STORED AS orc; 
不适用zlib压缩的话,查询速度更快,但是也大一些。
CREATE TABLE sale(
id int, timestamp timestamp,
productsk int, storesk int,
amount decimal, state string
)STORED AS orc tblproperties ("orc.compress"="NONE"); 下面是加快hive查询的一些可以参考的方式:
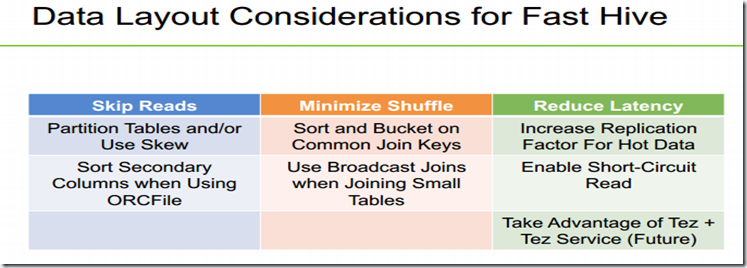
(1)跳跃读取:采用分区Partition或者使用Skew,才用ORCFile二次排序。
(2)在连接字段上排序并且bucket,在连接小表的时候采用Broadcast joins。
(3)对经常使用的数据,增加备份因子,激活Short-Circuit Read,采用Tez。

当某个表很大的时候,我们往往要对其进行分区,比如按照时间来分区。
CREATE TABLE sale(
id int, amount decimal, ...
)partitioned by (xdate string, state string);
其中的xdate和state是不存在的列,你可以认为它们是虚拟列,虚拟列会在HDFS当中建立子目录,属于分区的记录会存在那个子文件夹中。
使用分区之后,在查询和插入的时候,就必须带有至少一个分区字段,否则查询将会失败。
INSERT INTO sale (xdate=‘2013-03-01’, state=‘CA’)
SELECT * FROM staging_table
WHERE xdate = ‘2013-03-01’ AND state = ‘CA’;
如果你想一次查出所有数据,不想受这个限制的话,你可以 hive.exec.dynamic.partition.mode参数置为nonstrict。
set hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO sale (xdate, state)
SELECT * FROM staging_table;
有时候插入数据的时候,我们需要重新排序,在select 语句里面把虚拟列也加上,这样会有排序的效果。
INSERT INTO sale (xdate, state=‘CA’)
SELECT
id, amount, other_stuff,
xdate, state
FROM staging_table
WHERE state = ‘CA’;下面我们讲一下常用的hive查询调优

mapred.max.split.size和mapred.min.split.size
min 太大-> 太少mapper.
max 太小-> mapper太多.
Example:
– set mapred.max.split.size=100000000;
– set mapred.min.split.size=1000000;
当然也有个原则,当mappers出现抢占资源的时候,才调整这些参数。

– set io.sort.mb=100;
• All the time:
– set hive.optmize.mapjoin.mapreduce=true;
– set hive.optmize.bucketmapjoin=true;
– set hive.optmize.bucketmapjoin.sortedmerge=true;
– set hive.auto.convert.join=true;
– set hive.auto.convert.sortmerge.join=true;
– set hive.auto.convert.sortmerge.join.nocondi1onaltask=true;
• When bucketing data:
– set hive.enforce.bucketing=true;
– set hive.enforce.sortng=true;
• These and more are set by default in HDP 1.3(明显的广告词,说明HDP比较强大,已经给我们设置好了).
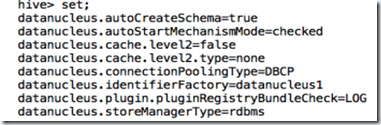
这些参数我们可以在hive-site.xml中查询到,我们也可以在shell中查询。
(1)查询所有的参数
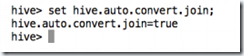
(2)查询某一个参数
(3)修改参数