在本文中,石沫针对用户遇到的各种实际问题,从实例层次到架构,通过8个SQL Server优化案例,分享了如何用最简单快捷的方式解决用户使用SQL Server数据库过程中的典型问题,使SQL Server能够稳定地提供持续服务。
以下是整理内容。
瓶颈诊断

工欲善其事,必先利其器。常见的分析性能问题的工具有三种:诊断硬件资源,等待类型,性能语句。
硬件资源通常有四个方面判断:
- CPU监控,性能计数器主要包括%Processor Time、Processor Queue Length、Batch request/sec、 Transactions/sec(total_)。这些参数能够判断CPU的处理能力,或者说一个实例的吞吐量。
- Memory监控,性能计数器主要为: Buffer Cache Hit Ratio、 Page Life Expectancy、Lazy Writes/sec。这几个性能参数基本上能反映内存问题,观察内存状态。
- IO监控,性能参数主要为:Current Disk Queue Length、Avg.Disk Sec/Read、Avg.Disk Sec/Write。
- Network 监控,尽管目前网络方面很少出现瓶颈,但仍需监控Bytes Total/sec和% Net Utilization,其中Net Utilization是一个系统级别的参数。
监控硬件资源的性能计数器有三个工具可以使用,分别是:Logman、Perfmon、sys.dm_os_performance_counters 。其中Logman是一个命令行工具,十分易用,且可设置很多参数,满足不同用户的需求;Perfmon是一个UI工具,也是目前最常用的工具之一;sys.dm_os_performance_counters是SQL Server内置的搜集性能计数器的系统视图,它可以定制性能参数收集,但OS的性能参数是无法收集的。
通常备受关注的等待类型主要有三种:返回执行的线程所遇到的所有等待的相关信息、有关按类组织的所有闩锁等待的信息、可以使用系统视图来诊断SQL Server 以及特定查询和批处理的性能问题。其中,上述每一项对应的诊断工具如下:
- sys.dm_os_wait_stats :服务器级别的收集数据
- sys.dm_os_latch_stats :服务器级别收集的闩锁等待信息
- sys.sysprocesses/sys.dm_exec_requests: 可以用在SESSION级别或者语句级别的等待类型分析
这里要注意两点:第一点,sys.dm_os_wait_stats 收集的数据是累计的结果,若需准确地判断当前问题,则要清理掉这些数据;否则,以前的某个数据/参数值可能会高于现在的值;第二点,sys.dm_os_wait_stats/sys.dm_os_latch_stats 确定是否需要清除缓存数据,使用DBCC SQLPERF。
性能语句方面,慢SQL是数据库性能表现最突出的方式,因此跟踪慢SQL是性能调优必须做的工作。一般可用工具如下:
- SQL Server Profiler:可跟踪数据库所有事件的工具,在扩展事件出现前,是最常用的工具。
- 活动监视器:它是快速诊断问题的一种工具,SSMS可方便查看资源瓶颈。
- 系统视图:sys.dm_exec_query_stats/sys.dm_exec_requests/sys.dm_exec_sql_text等,能根据个人需求定制系统信息,包括查询等待情况,查询执行计划,执行请求相关信息,执行SQL 的文本信息等。
- 扩展事件:建议SQL Server 2012之后的版本使用,此前的版本中,扩展事件是不完善的。
- 微软工具SQLDIAG/PSSDIAG/SQLNexus/Perfmance Dashboard
这里有一点需要使用者特别注意,使用SQL Server Profiler是一种比较重的方式,对系统性能影响为5~10%左右,为了减少性能影响,可以采用以下几个方面进行优化:
- 使用脚本创建并生成文件,不要远程收集数据;
- 收集数据时尽可能使用多的过滤条件,并去掉不必要的输出列;
- 收集的是原始数据,需要聚合和处理数据,可以自己写正则表达式处理。
下图所示的是一个跟踪当前执行语句的示例:
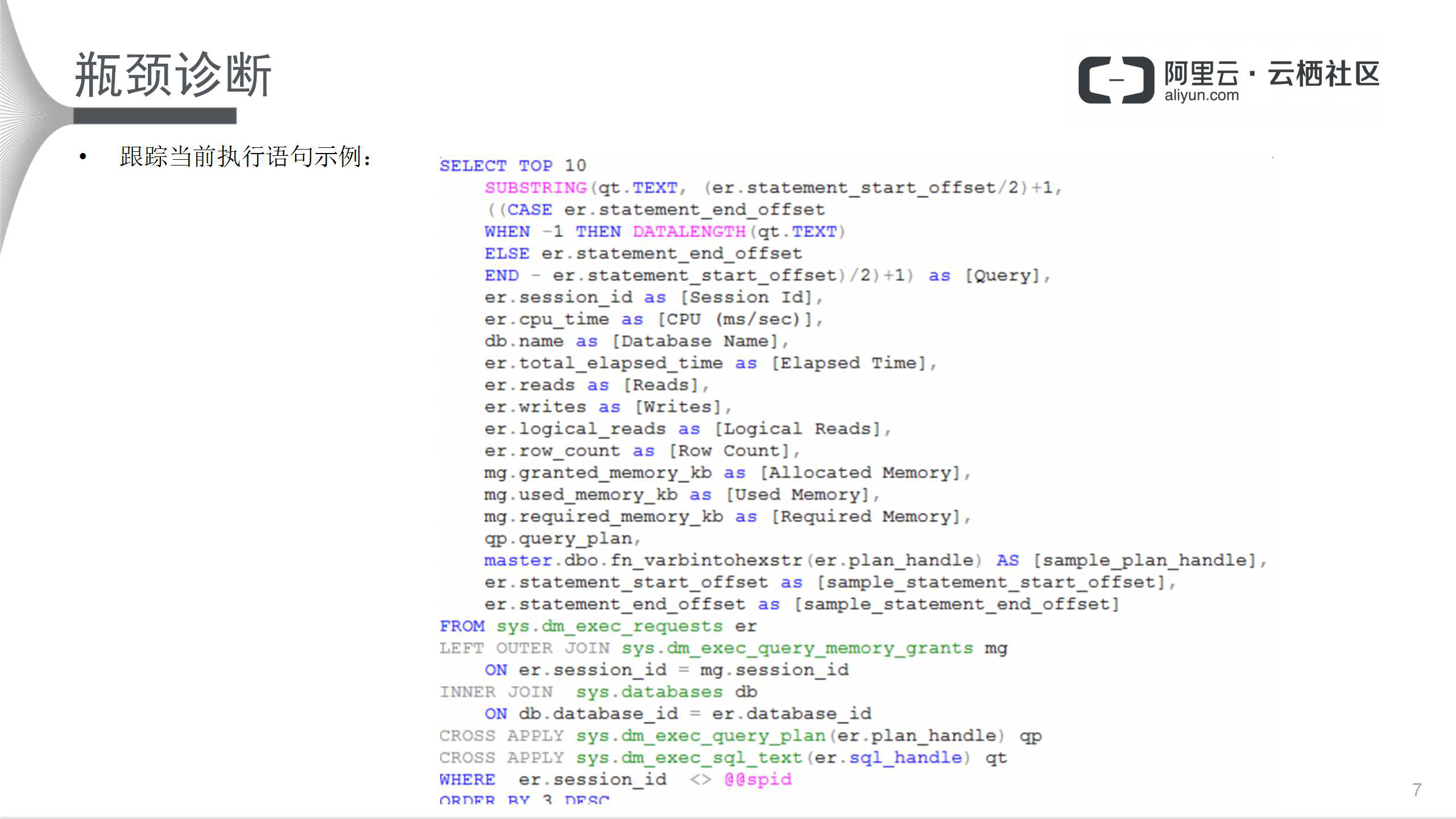
该SQL语句简单有效,用来抓取当前执行语句的SQL,可以方便地看到当前执行较长的语句,以及这些语句的资源开销情况。
接下来详细看一下具体的案例。
案例一:实例参数调试与选择

不同的业务场景,实例级别的参数也不同。在阿里云数据库中的实例级别,所遇最多需要调整的是并行度。并行参数如下,包括两个实例级别和一个语句级别:
- max degree of parallelism : 实例级并行度 。
- cost threshold for parallelism :并行执行的窜行开销阈值,其中开销为在特定硬件配置中运行串行计划估计所需时间,单位是秒,若串行执行计划超过了该值,就启用并行执行计划。
- option (dopmax N ):语句级并行执行控制。
除了并行参数之外,并行技术方面还要了解其他技术要点:首先,并行执行本质上是利用多个逻辑CPU执行某个语句;同时,并行执行需要初始化、同步、中止并行等开销,从而开销增加;此外,查询的开销计划小于开销阈值也可能并行执行;除此之外,option (dopmax N )提示会覆盖实例级别的并行设置;最后,当设置相关掩码映射逻辑CPU为1时不会并行执行。

下面来看一个具体的案例,该案例的主要现象是系统影响很慢,复制延迟6个小时,请求数和事务处理很低;同时大量的CXPACKET等待,大量SESSION被阻塞;此外,它的并行度设置是0。
此处等待类型为CXPACKET,在并行查询尝试使用同步查询处理器,交换迭代器时发生,这就要考虑调整并行度的开销阈值,或降低并行度。具体操作也是非常容易的,使用图中sp_configure语句,只要调整这个值,就会解决遇到的性能问题。
常见的最佳实践包括:
第一点,使用活动监视器快速诊断,了解梗概;
第二点,查看实例的TOP 10等待类型,查看SESSION的等待类型;
第三点,介于OLTP和OLAP的数据库,建议将实例并行度设置为2,是个经验值;
第四点,创建性能计数器,精确定位问题。
案例二:为何tempdb的设置如此重要

案例二是数据库级别的案例,一般情况下我们更关注的是用户的数据库。,在系统数据库中,Tempdb的主要作用为:tempdb 是一个系统数据库,是一个全局资源 。它可以显式创建的临时用户对象:例如临时表、临时存储过程、表变量或游标;数据库引擎创建的内部对象:例如存储假脱机或排序的中间结果的工作表;行版本号:例如行版本控制隔离或快照隔离事务或者联机索引操作、触发器等。Tempdb还可以进行性能提升,比如可缓存临时对象、分配混合页算法改善性能、最小日志写入。
Tempdb在使用中常导致三种问题:空间问题、资源争抢,PAGELATCH等待、高并发问题。
下面来看一个具体案例。
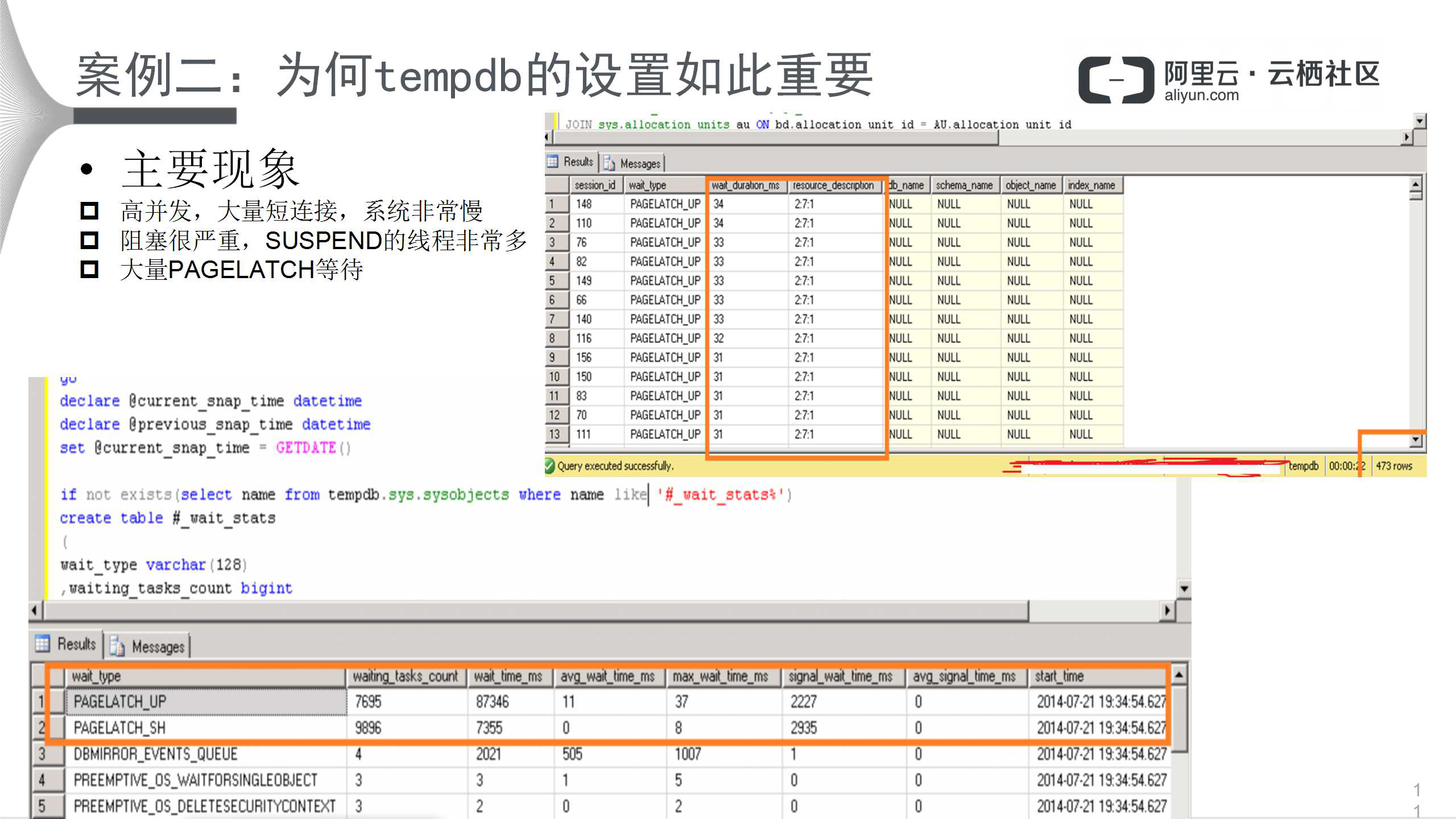
该案例的主要现象为:高并发,大量短连接,系统非常慢;阻塞很严重,SUSPEND的线程非常多;大量PAGELATCH等待。
上图是在实例级别统计的等待类型,很明显,最多的是LATCH_UP等待,那列红色框图的描述非常重要。其中2:7:1中的2指的是数据库,数据库的ID为2,即tempdb;7是它的第8个文件;1是一个特殊页,其实就是PFS,即每个数据库文件都有的页面设置空间。因此,高并发下,不断访问(扫描)tempdb的文件的PFS页使其变得尤为重要。
关于PFS页的争用,最佳实践为:
- 打开跟踪标记1118,消除单页分配
- 使用多个文件可以减少 tempdb 存储争用并获得更大的可伸缩性
- 文件多少一般与对应的逻辑CPU对齐,但并非完全按照这个规律
- 多个文件大小设置相同,按比例填充算法根据文件大小使用GAM页分配到最大文件
- 文件增量设置为合理的大小以避免 tempdb 数据库文件的增量过小,200~500M(10%)
- 磁盘尽可能使用用户数据库使用的磁盘以外的磁盘
做到以上这些要求,tempdb的竞争就会减少或消除,使用者如果有这方面的瓶颈,可以尝试一下。
案例三:隔离级别的正确选用
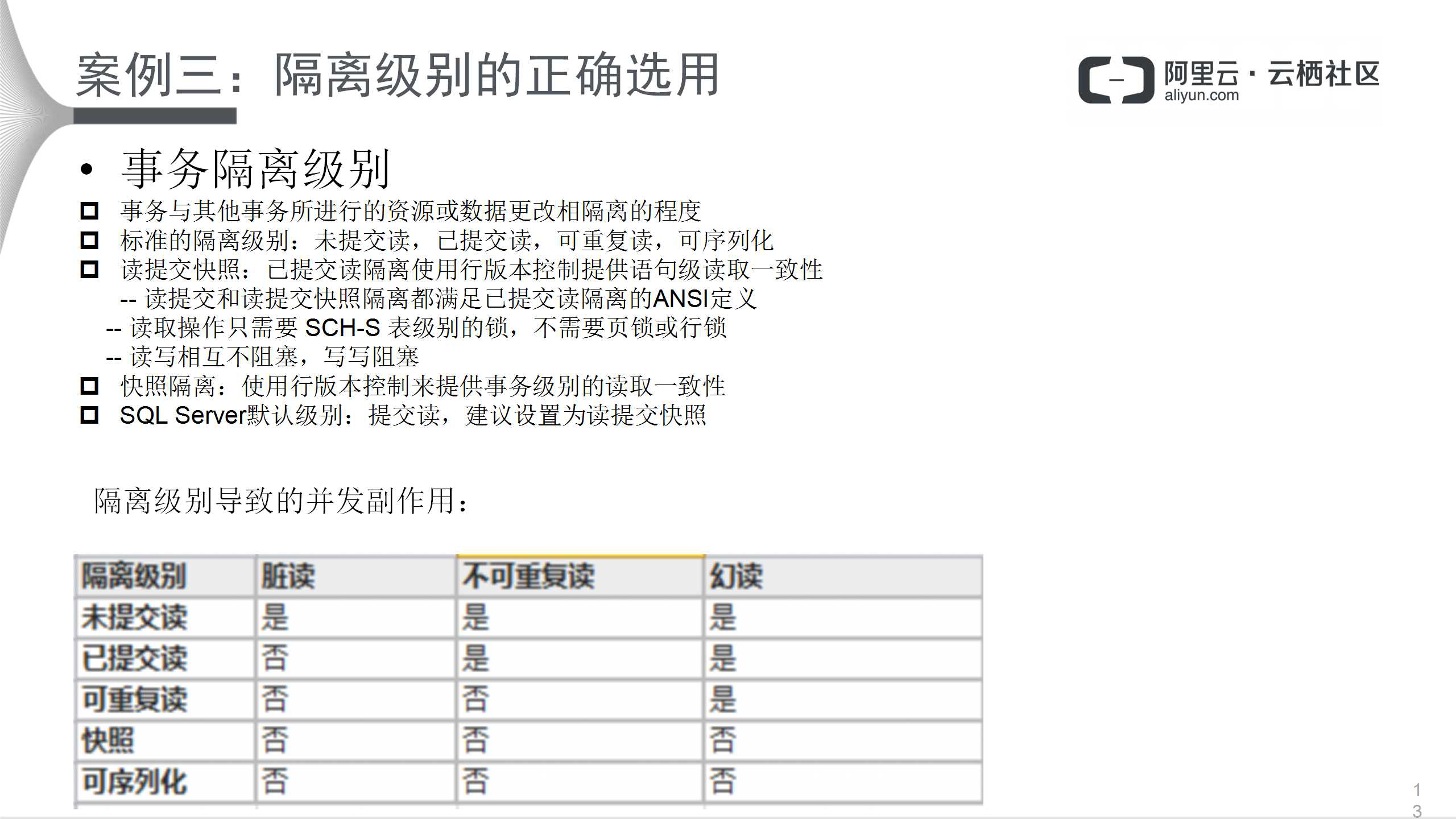
案例三为数据库隔离级别的影响。事务隔离级别是指事务与其他事务所进行的资源或数据更改相隔离的程度。标准的隔离级别有四种:未提交读,已提交读,可重复读,可序列化。除此之外,SQL Server还增加了读提交快照和快照隔离:
- 读提交快照是指已提交读隔离使用行版本控制提供语句级读取一致性:
- 读提交和读提交快照隔离都满足已提交读隔离的ANSI定义
- 读取操作只需要 SCH-S 表级别的锁,不需要页锁或行锁
- 读写相互不阻塞,写写阻塞
- 快照隔离是使用行版本控制来提供事务级别的读取一致性。
SQL Server默认级别是提交读,但建议设置为读提交快照。标准隔离级别可能导致并发的副作用,具体情形如上图表格所示。

该案例的主要现象是:系统比较慢,执行SQL超时;整个实例事务锁很严重,非常多的S锁(共享锁);数据库的隔离级别为默认提交读。
如上图所示,用户的事务锁信息达到了26W之多,进而严重影响整体性能。对于这些整体性问题,考虑设置隔离级别、读提交快照可以有效解决。锁过多的原因在于:表的设计不合理,SQL写得不够优化;或者从实例级别整体上来看,数据库隔离级别设置不合理。
因此最佳实践为将数据库设置为读提交快照,获取性能参数,对比结果:锁从5W降级到2K,TPS从1000增加到1600。所以优化时,通过设置数据库的隔离级别,能够提高相当可观的性能。
案例四:表的常见问题

常见的典型的表问题包括:范式与反范式应用不合理、数据类型选择不合理、主键选择不当、堆表和聚集索引表分不清、主表从表连接字段设计类型不一致。
下面看一个模拟用户案例。
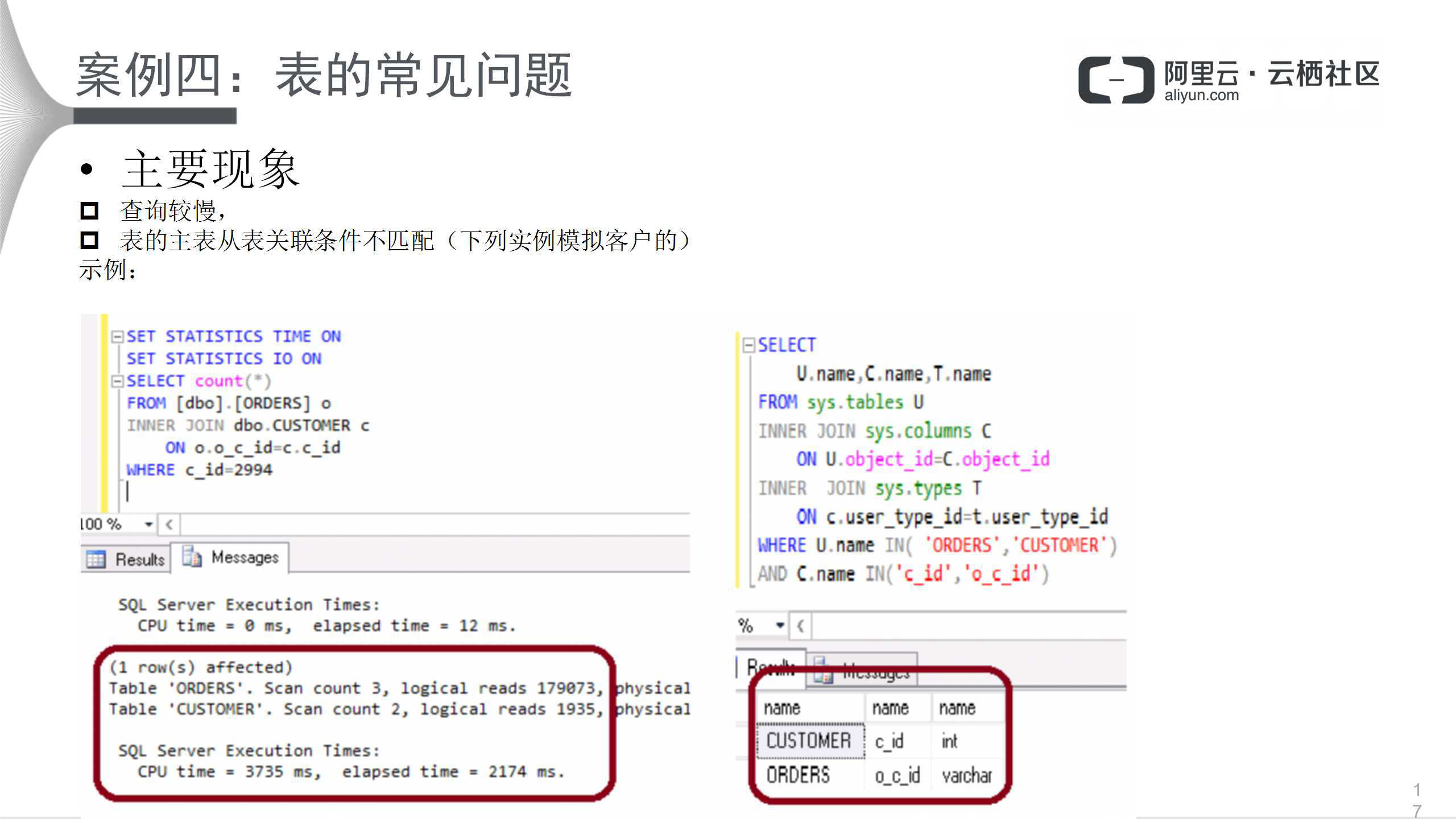
该用户的主要现象是查询较慢;表的主表和从表关联条件不匹配。上图左侧语句非常简单,执行结果中,CPU用时3.735秒,执行时间2.174秒,时间较长。查看系统视图,发现表的类型一个是int型、一个是varchar型,直接很难看出来,但是查看执行计划就很清楚。
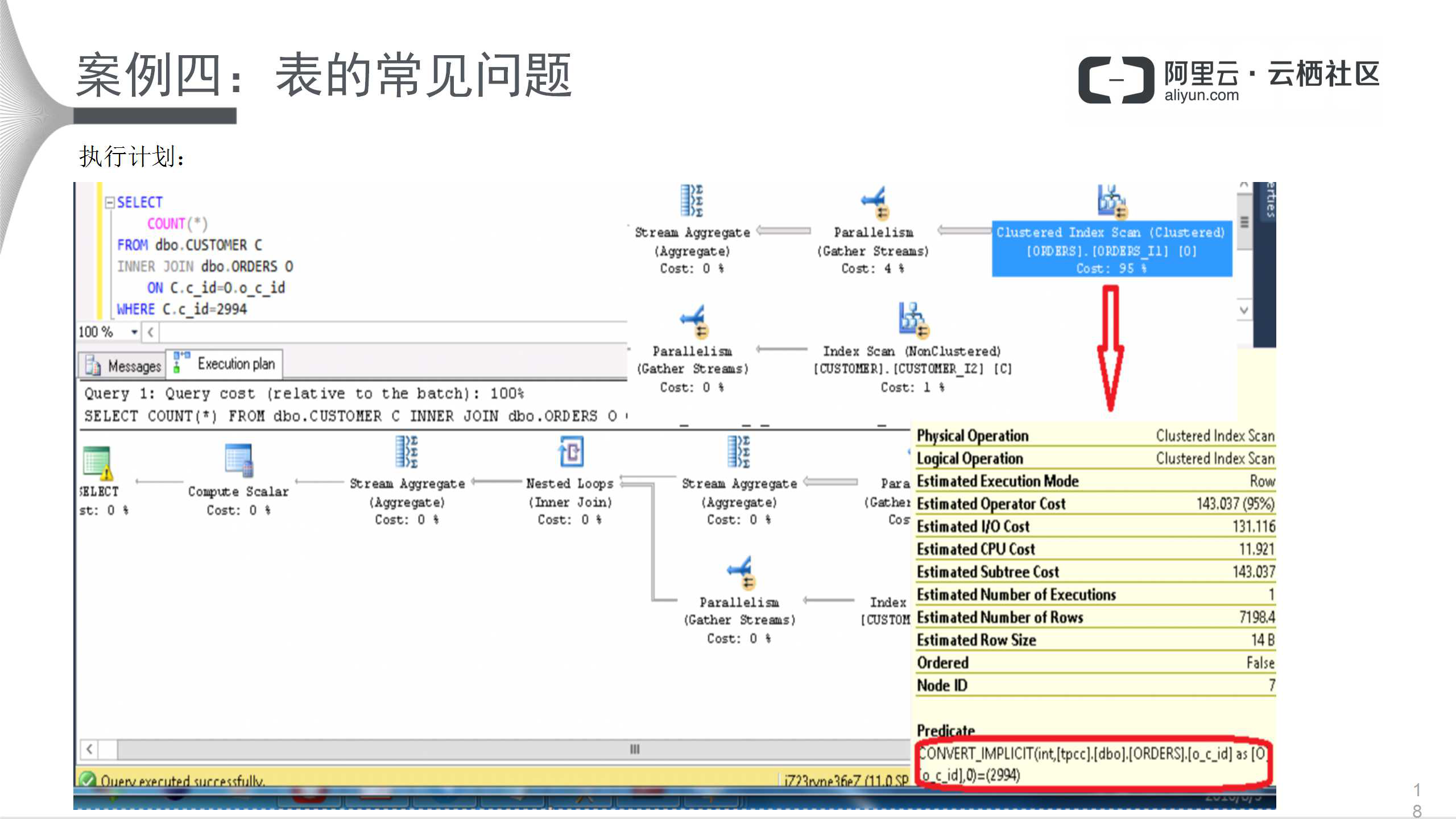
很明显,关联条件存在类型不一致,导致执行效率低下。因此,将关联条件类型调整一致,修改表的结构是最好的方式。不过修改时请注意,始终在业务空闲时操作,如果列有INDEX,需要先DROP 掉索引才可以更改。
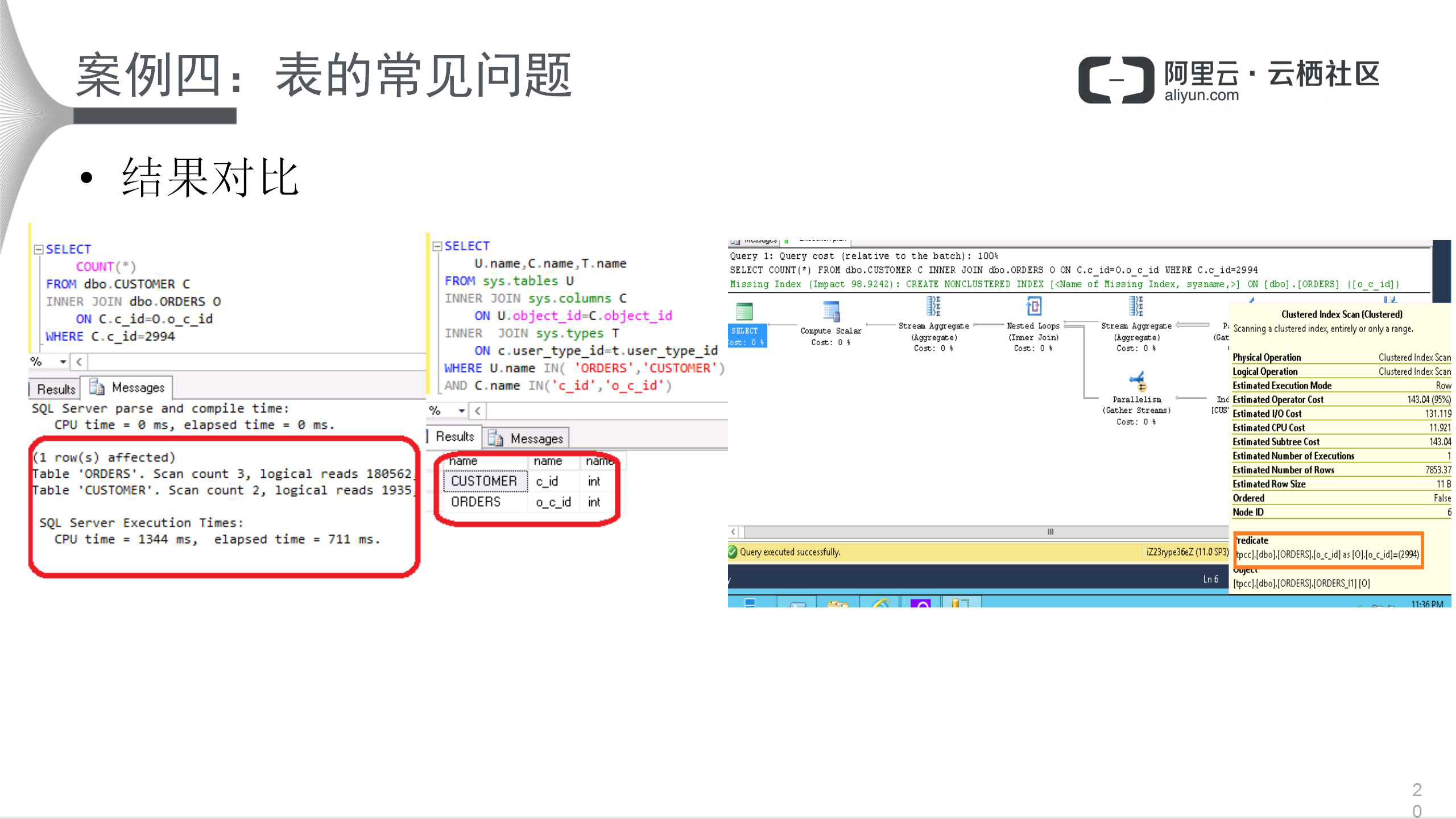
结果对比如上图所示。显然,结果得到提升,CPU开销从4秒到1秒多,数据结构类型也变一致,这就是SQL Server强大的地方。
关于表的设计,还有一些建议如下:
- 一般要求第三范式,可适当冗余;
- 应该优先考虑数字类型,其次是日期或二进制类型,最后是字符类型;
- 表的列长度尽可能短,即可减少空间,也可以提高性能;
- 字符变长可能出现行溢出,定长消耗更多的空间导致分割更多的页,需权衡;
- LOB数据类型请使用nvarchar(max)/varchar(max)/varbanary(max);
- 正确认识UNICODE字符带来的好处和坏处;
- 查询和变更频繁的表建议设计为聚集索引表,插入更新和查询需要平衡;
- 外键可以提升性能,但后期维护比较麻烦,建议业务上规范主外键关系;
- 避免关联条件出现数据类型不一致,非常重要;
案例五:索引的常见问题
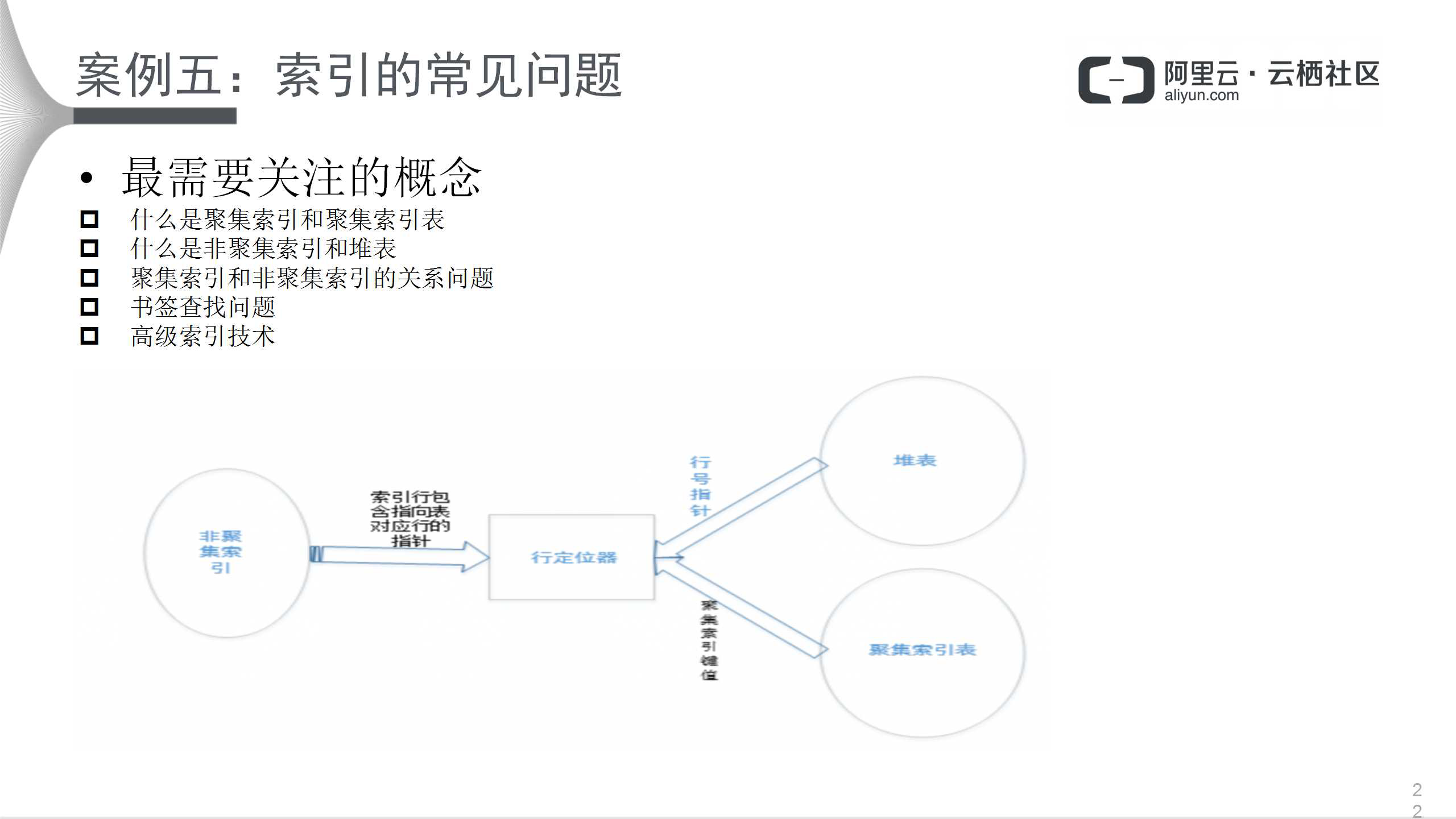
从表再细分一层,从索引的角度出发。关于索引,使用者需要了解以下几个概念:
- 什么是聚集索引和聚集索引表
- 什么是非聚集索引和堆表
- 聚集索引和非聚集索引的关系问题
- 书签查找问题
- 高级索引技术
其中聚集索引和非聚集索引的关系如上图所示,聚集索引有一个指针,指针即为行定位器,与堆表和聚集索引表都有关系。
下面来看一个具体例子。
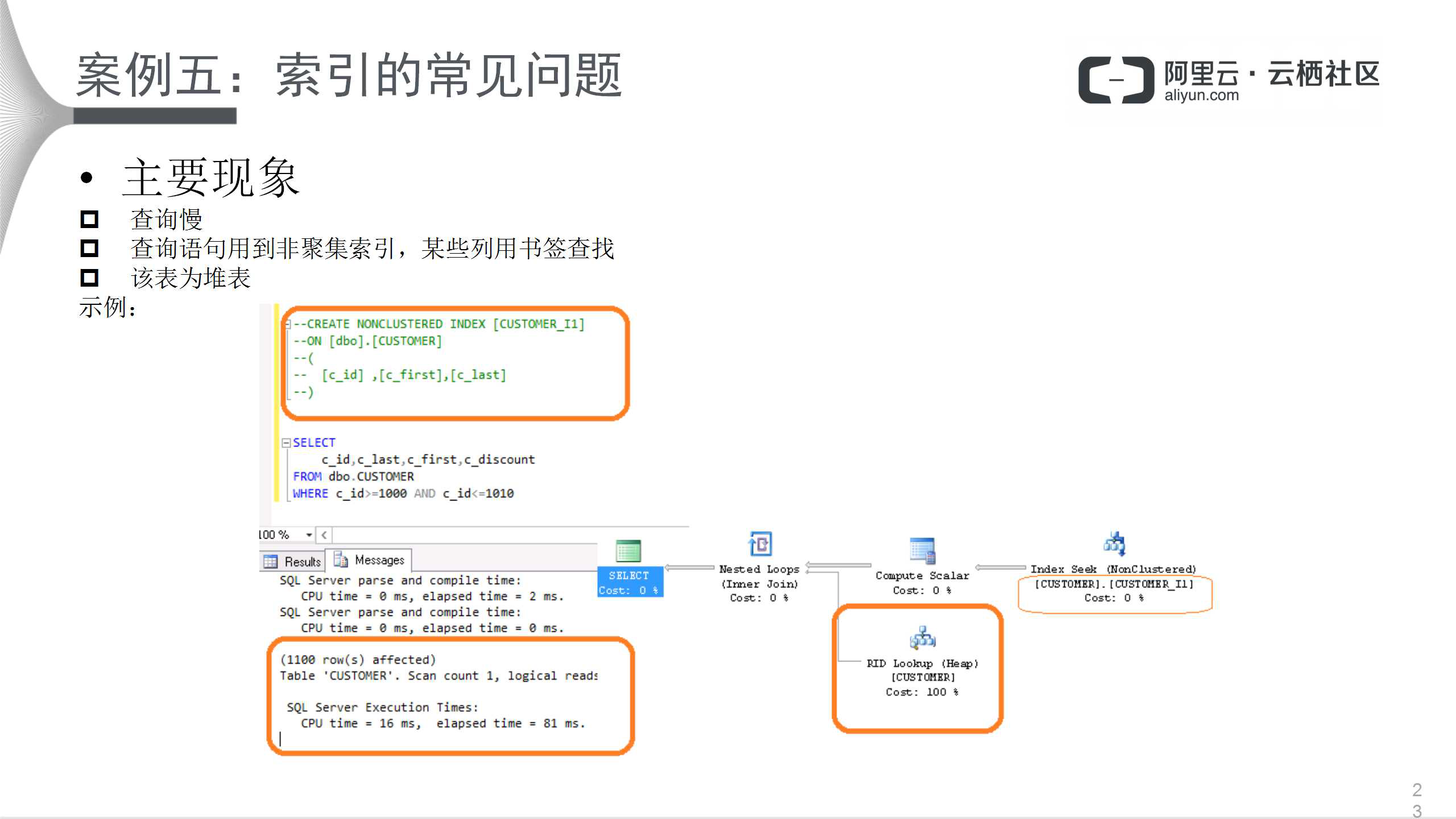
该典型案例主要现象是查询慢;查询语句用到非聚集索引,某些用书签查找。这是书签查找的典型问题,语句很简单,查询某些范围的可获得信息,该非聚集索引包含三个列,不包括c_discount,执行情况为1100行数据,CPU开销为16ms,执行时间81ms。该执行计划没有使用到索引的列,通过行号查找,可以看得出开销100%。
竖线查找有两个解决办法:
(1)消除书签,覆盖所有列,把c_discount列包含进来,语句不变,情况马上得到改善。
(2)把表更改为聚集索引表。
索引设计建议如下:
- 检查WHERE子句和连接条件列
- 使用窄的索引
- 检查列的唯一性
- 检查列的数据类型
- 考虑列的顺序
- 优化书签查找,使用覆盖索引,聚集索引或者索引连接消除书签查找
- 检索一定范围和预先排序数据适合聚集索引
- 频繁更新的列上不要设计聚集索引,他将导致所有的非聚集索引的更新
- 首先创建聚集索引,再创建非聚集索引,整理索引碎片也是如此
案例六:阻塞分析
阻塞可能有很多种,这从系统视图中可以看得很清楚。分析阻塞,最重要的是看当前阻塞的资源是什么,在等待什么资源释放,那么关于阻塞,需要了解的基本知识如下:
- 锁能有效管理数据库资源的并发,并且保证数据的一致性
- 死锁是连接不可退让的僵死局面,是一种永久的阻塞
- 锁粒度是什么
- 锁模式有是什么
- 必须了解事物的ACID属性
- 隔离级别对阻塞的影响
其实阻塞主要还是因为有锁,因为锁能有效管理数据库资源的并发,并且保证数据的一致性。死锁是连接不可退让的僵死局面,是一种永久的阻塞,一旦出现死锁,会保留回滚资源最大的连接。只要涉及数据库,事务的ACDI属性就必须要了解。下面看一个具体的用户真实案例,程序执行非常缓慢,很多连接超时。
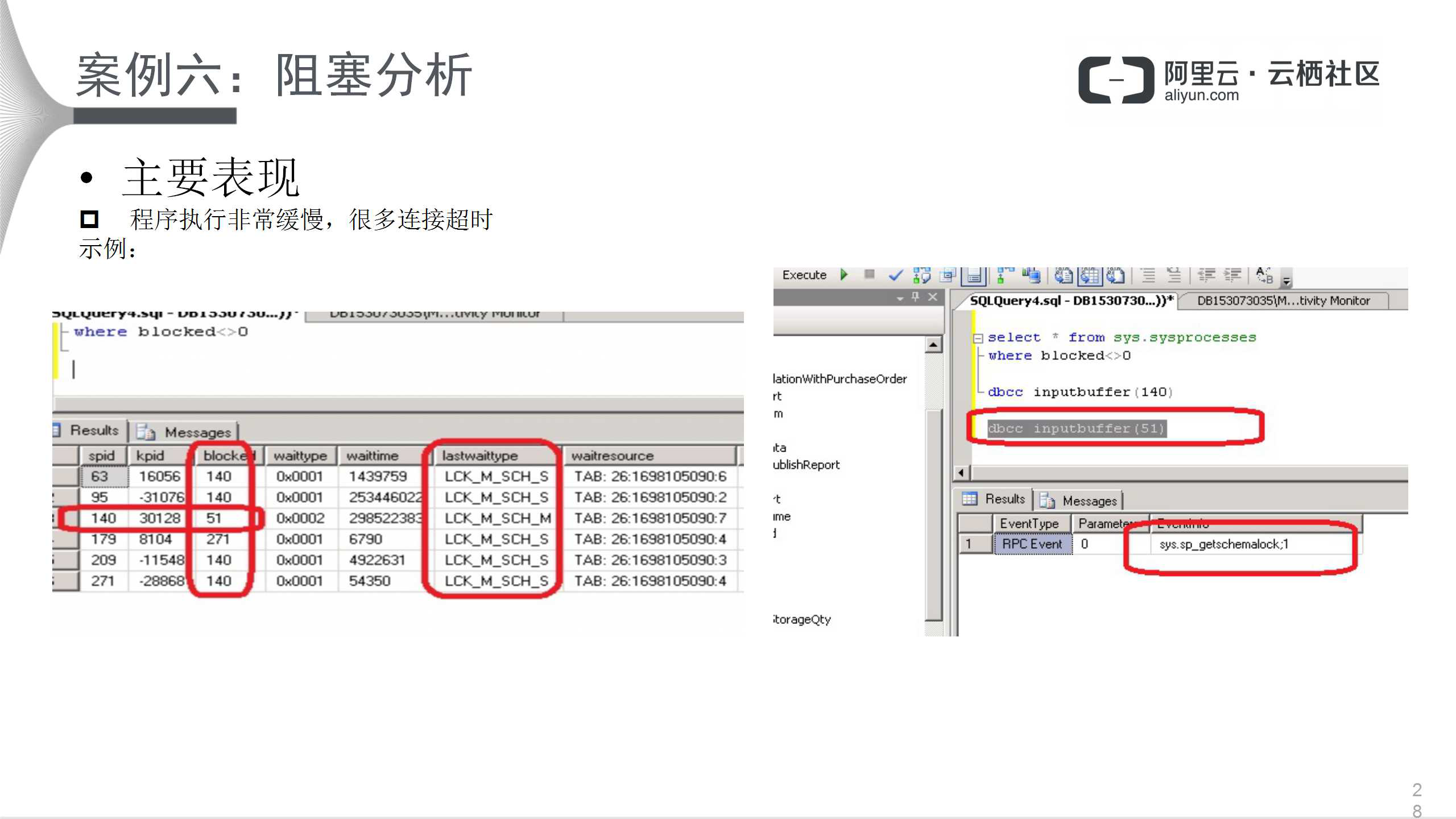
上图的执行脚本非常简单,右图的sys.sysprocesses清楚地描述了阻塞情况,51号进程阻塞了140号,140号又大量阻塞了其他进程。51号SESSION在努力得到架构锁,140号在做REBUILD INDEX,从而51号SESSION被系统资源阻塞,而无法释放,140号SESSION 的REBUILD INDEX 必然影响业务的正常运转。因此直接KILL 51就可以解决问题。通常kill一个进程,别忘了看其成本。

阻塞分析的几点建议如下:
- 保持短的事务
- 事务中尽可能执行少的逻辑
- 事务中不要干非数据处理相关的事
- 使用索引加快执行
- 使用覆盖索引解决查询性能
- 使用分区提升争用的表
- 使用行版本号控制资源争用
- 控制好事务处理,切莫让事务失去控制
- 使用提交读快照隔离级别
另外,阻塞最严重的就是死锁问题,可打开1222/1204跟踪和分析死锁信息。
案例七:SQL语句优化
当有问题出现,首先查看mySQL,如果是它出现的问题,则再考虑以下几个问题:
- 无索引或者索引不正确
- 隐式转换让SQL执行效率低下
- 列上使用函数进而算术运算
- LIKE语句导致全表扫描
- WHERE条件的使用OR连接
现在看一下案例。第一个案例说明了使用函数导致性能低下。
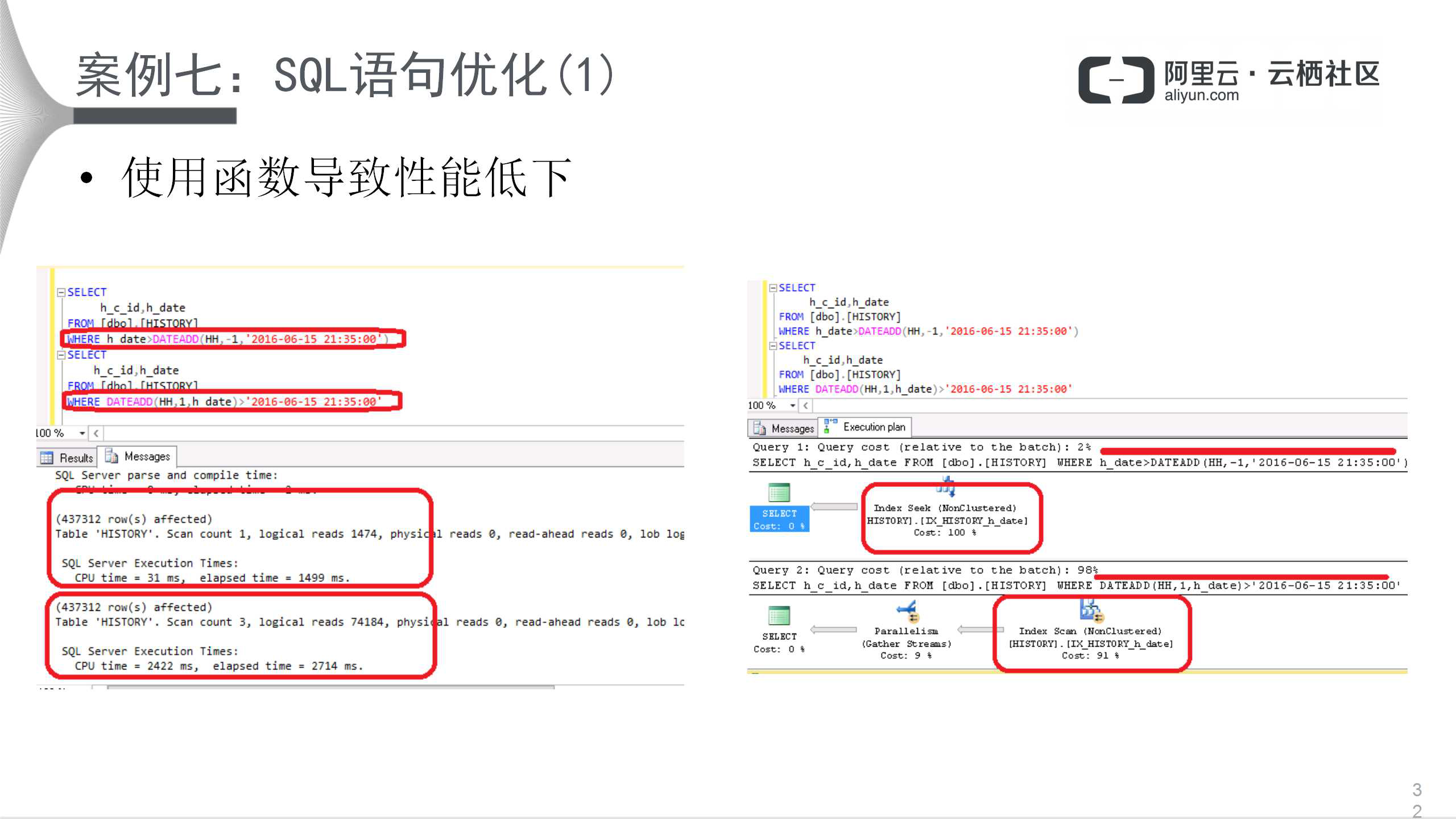
上面的语句是正确的写法,下面语句是错误的、使用函数的写法。左图下方,数据量同样是437312,,执行效率大相径庭,说明使用函数的危害非常大;同时看一下右边,和左边相呼应,index seek和scan会扫描更多的逻辑页,因此会显著降低性能,很多这种情况都可以避免。
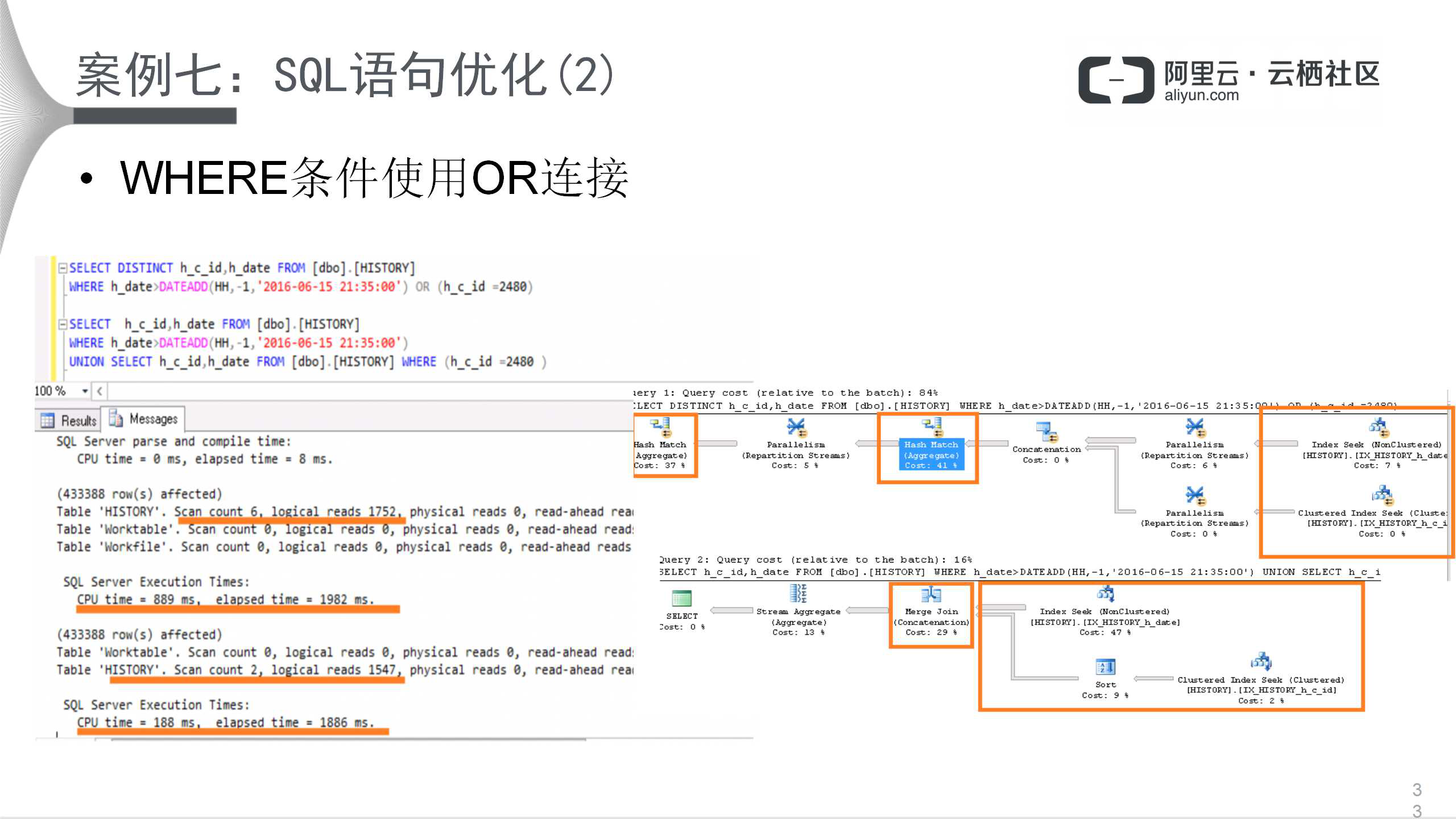
案例2解释了当WHERE条件使用了OR连接,上面和下面的语句执行结果一致,但是扫描的明显不一样,开销也不一样:上面的CPU使用了9ms左右,下面的接近200ms。右边为执行计划,很明显,使用了OR连接,执行计划要复杂的多,这也是性能差异的主要原因。
下图是总结的相关建议:

案例八:架构优化的演进
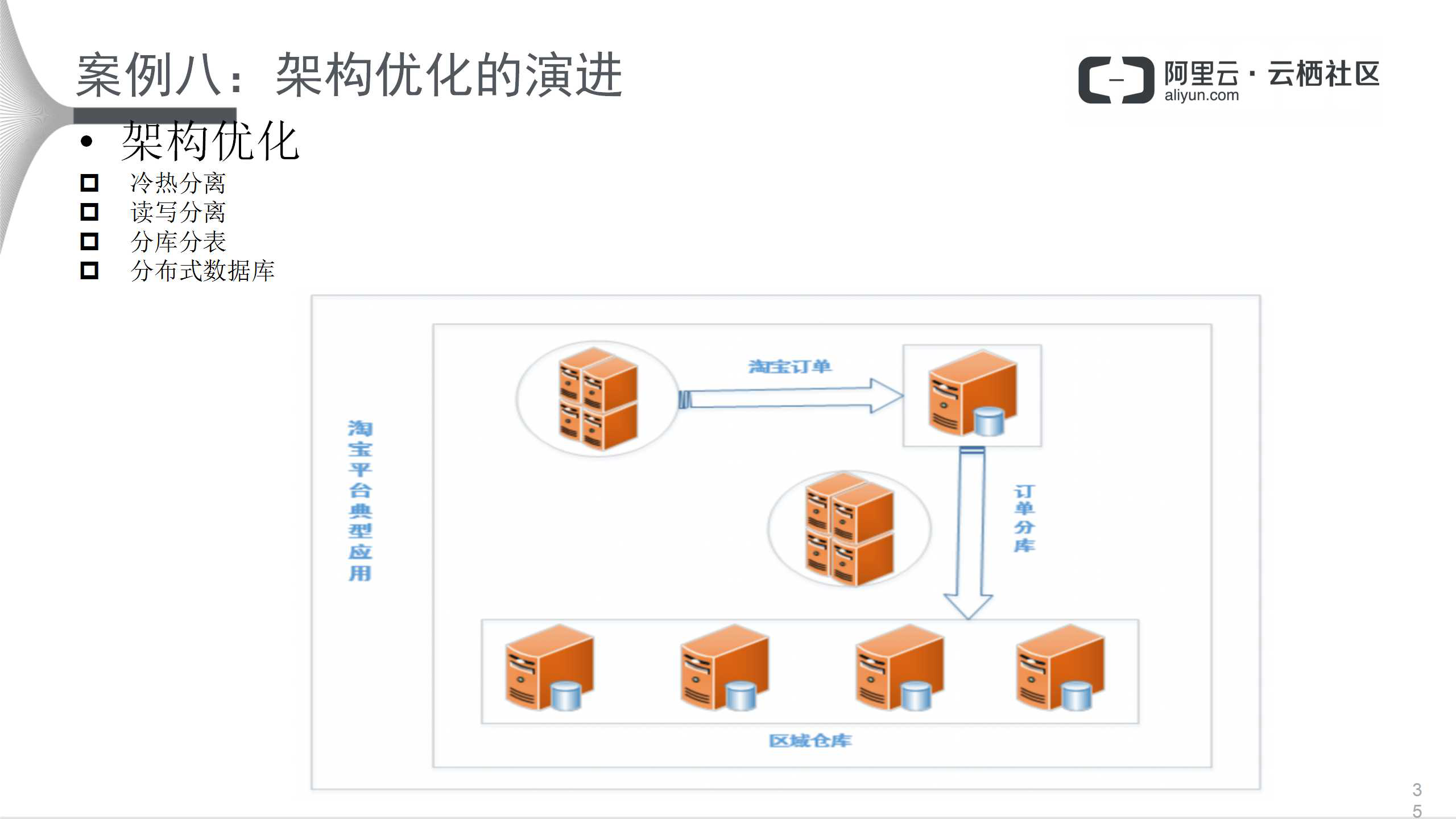
最后看一下架构。前面从数据库的角度考虑,如果性能没有提升,那就从架构考虑。架构优化方式有以下几种:
- 冷热分离。例如,一个大表,可以把各个数据比如说三个月数据放入当前表,三个月之外的数据放入历史表,这样可以显著减少表的大小。
- 读写分离能够减少读和写的压力。
- 分库分表可从业务上来看,也可从数据上来看。业务上,比如说一个购物流程,有订单系统、用户信息、滞后信息还有仓库配送。那么,系统初始阶段放在一个图上,当业务扩大,需要从业务上将其分开,将业务放到不同的层次上,不同的数据库实例上去,从而减小压力。如果还不够,就再进行冷热分离和读写分离。
- 分布式数据库为前三个的延伸,把不同的业务和数据放到不同的实例中去。


