DeepMind在2013年发表了一篇题为《用深度强化学习玩Atari》的文章,介绍了一种新的用于强化学习的深度学习模型,并展示了它仅使用原始像素作为输入来掌握Atari 2600计算机游戏难度控制策略的能力。在本教程中,我将使用Keras实现本文。我们将从增强学习的基础开始,然后深入代码中进行实践性的理解。

AI玩游戏
我在2018年3月初开始了这个项目,并取得了一些不错的成果。但是,只有CPU的系统是学习更多功能的瓶颈。强大的GPU极大地提升了性能。
在我们运行模型之前,我们需要了解许多步骤和概念。
步骤:
- 在浏览器(JavaScript)和模型(Python)之间构建双向接口
- 捕获和预处理图像
- 训练模型
- 评估
源代码:https://github.com/Paperspace/DinoRunTutorial.git
入门
要按照原样训练和玩游戏,请在设置环境后克隆GitHub存储库
Git克隆:https://github.com/Paperspace/DinoRunTutorial.git
并在jupyter notebook上工作。
Reinforcement Learning Dino Run.ipynb
确保你第一次运行init_cache()来初始化文件系统结构。
强化学习
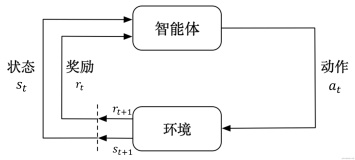
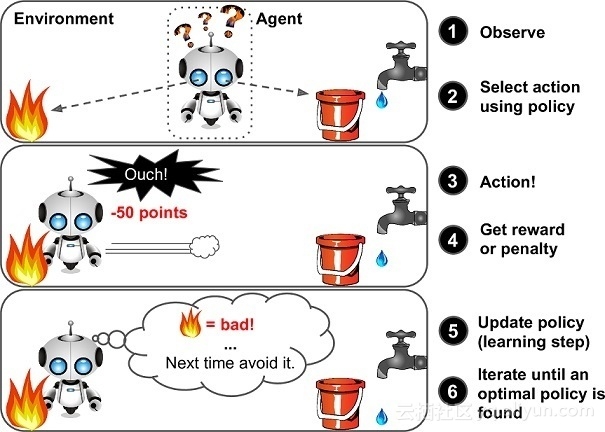
对许多人来说,这可能是一个新词,但我们每个人都已经学会了使用强化学习(RL)的概念,这就是我们的大脑仍然工作的方式。奖励系统是任何RL算法的基础。如果我们回到儿童走路的比喻,积极的奖励将是来自父母的鼓掌或能够得到糖果,而负面奖励将是没有糖果。孩子在开始走路之前首先学会站起来。就人工智能而言,代理商的主要目标(在我们的案例中是Dino)是通过在环境中执行特定的操作序列来最大化某个数值奖励。RL中最大的挑战是缺乏监督(标记数据)来指导代理人。它必须自己探索和学习。代理从随机执行行动开始,观察每个行动带来的回报,并学习如何在面临类似环境状况时预测最佳行动。
一个普通的强化学习框架
Q-learning
我们使用Q-learning, RL的一种技术,在这里我们尝试去近似一个特殊的函数,它可以驱动任意环境状态序列的动作选择策略。Q- Learning是一种没有模型的强化学习的实现,它根据每个状态、所采取的行动和所产生的奖励来维护一个Q值表。一个示例q表应该告诉我们数据是如何构造的。在我们的例子中,状态是游戏截图和动作,什么都不做,然后跳转[0,1]。
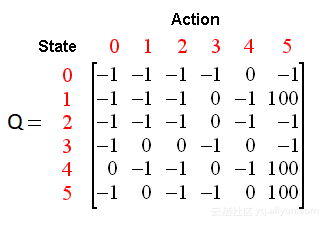
样本Q表
我们利用深度神经网络通过回归来解决这个问题,并选择具有最高预测Q值的动作。有关Q-learning的详细了解,请参阅Tambet Matiisen撰写的这篇令人惊叹的博客文章。你也可以参考我以前的文章,了解所有Q-learning特有的超参数。
建立
让我们设置我们的环境来开始训练过程。
1.选择虚拟机:
我们需要一个完整的桌面环境,在这里我们可以捕获和利用屏幕截图进行培训。我选择了一个Paperspace ML-in-a-box(MLIAB)Ubuntu镜像 MLIAB的优势在于它预装了Anaconda和许多其他ML库。
盒子中的机器学习
2.配置和安装Keras以使用GPU:
我们需要安装keras和tensorflow的GPU版本。Paperspace的虚拟机具有这些预先安装的,但是如果不安装它们的话
pip install keras
pip install tensorflow
另外,确保GPU可以被设置识别。执行下面的python代码,你应该看到可用的GPU设备
from keras import backend as K
K. tensorflow_backend._get_available_gpus()
3.安装依赖项
Selenium pip install selenium
OpenCV pip install opencv-python
从 http://chromedriver.chromium.org上下载Chromedriver
游戏框架
你可以通过将浏览器指向chrome://dino或只要拔掉网络插头来启动游戏。如果我们想修改游戏代码的话,另一种方法是从chromium的开源存储库中提取游戏。
我们的模型是用python编写的,游戏是用JavaScript构建的,我们需要一些接口工具让它们相互通信。
【Selenium是一种流行的浏览器自动化工具,用于向浏览器发送操作,并获取当前分数等不同的游戏参数。】
现在我们有一个接口来发送动作到游戏中,我们需要一种机制来捕获游戏屏幕。
【Selenium和OpenCV分别为屏幕捕获和图像预处理提供了最佳性能,实现了6-7 fps的下降帧率。】
我们每个时间帧只需要4帧,足以将速度作为一项功能来学习。
游戏模块
我们使用这个模块实现了Python和JavaScript之间的接口。下面的代码片段会给你一个关于模块中发生的事情的要点。
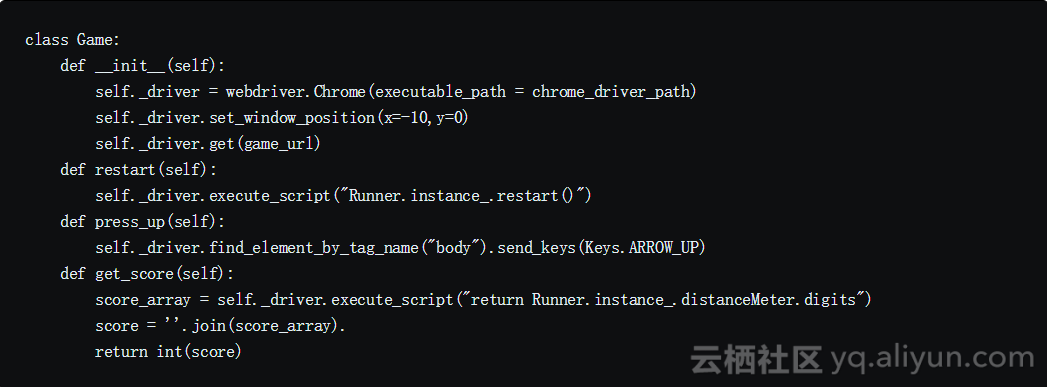
代理模块
我们使用代理模块来封装所有的接口。我们使用此模块控制Dino,并获取环境中的代理状态。
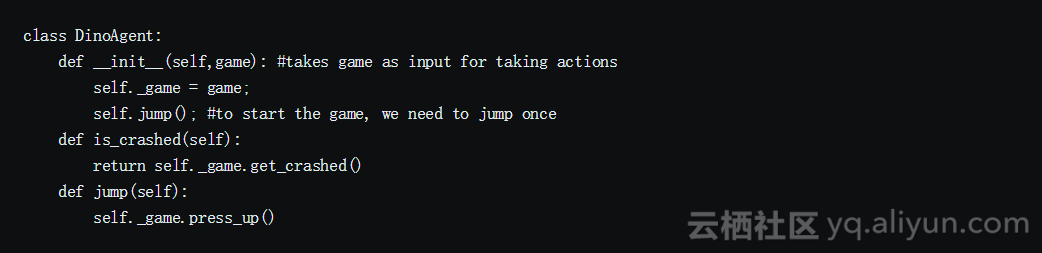
游戏状态模块
要将操作发送到模块并获得环境作为该操作的结果转换为的结果状态,我们使用游戏状态模块。它通过接收和执行动作、决定奖励和返回经验元组来简化过程。
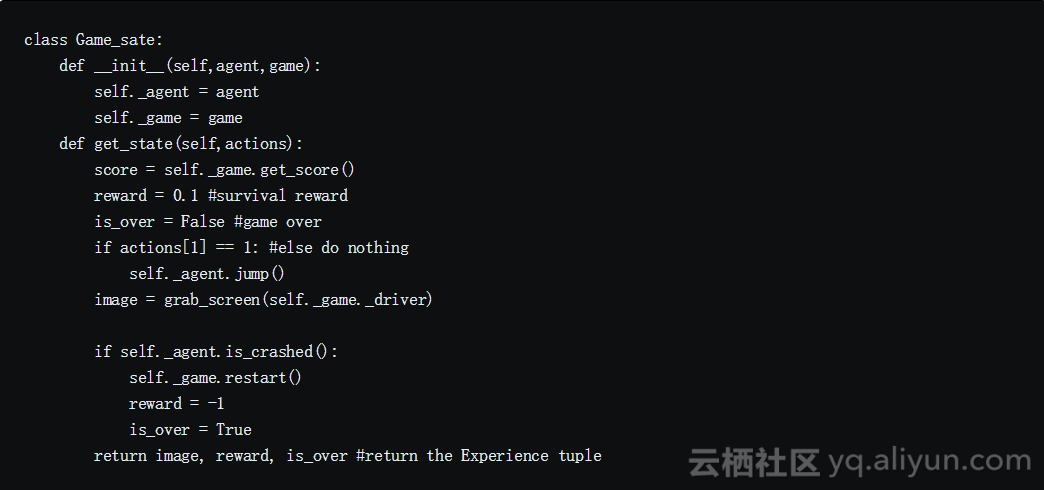
图像管道
图像捕捉
我们可以通过多种方式捕获游戏屏幕,例如使用PIL和MSS python库截取整个屏幕和裁剪区域。 然而,最大的缺点是对屏幕分辨率和窗口位置的敏感度。幸运的是,游戏使用了HTML Canvas。我们可以使用JavaScript轻松获得base64格式的图像。我们使用selenium来运行这个脚本。


从画布中提取图像

图像处理
所捕获的原始图像的分辨率约为600x150,有3个(RGB)通道。我们打算使用4个连续的屏幕截图作为模型的一个输入。这就使得我们对尺寸600x150x3x4的单个输入。这在计算上是昂贵的,并不是所有的功能都可用于玩游戏。所以我们使用OpenCV库来调整大小、裁剪和处理图像。最终的处理输入仅为80x80像素和单通道(灰度)。
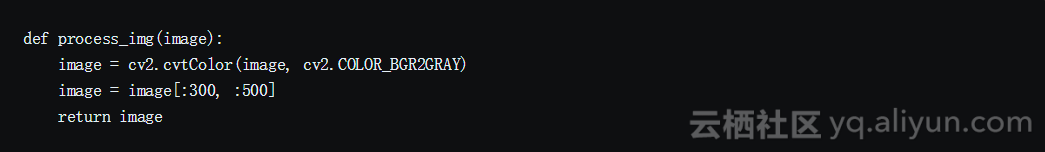
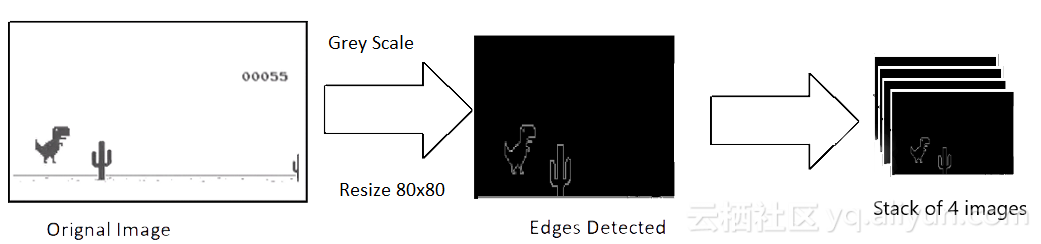
图像处理
模型架构
我们得到了输入和一种利用模型输出来玩游戏的方法,让我们来看看模型架构。
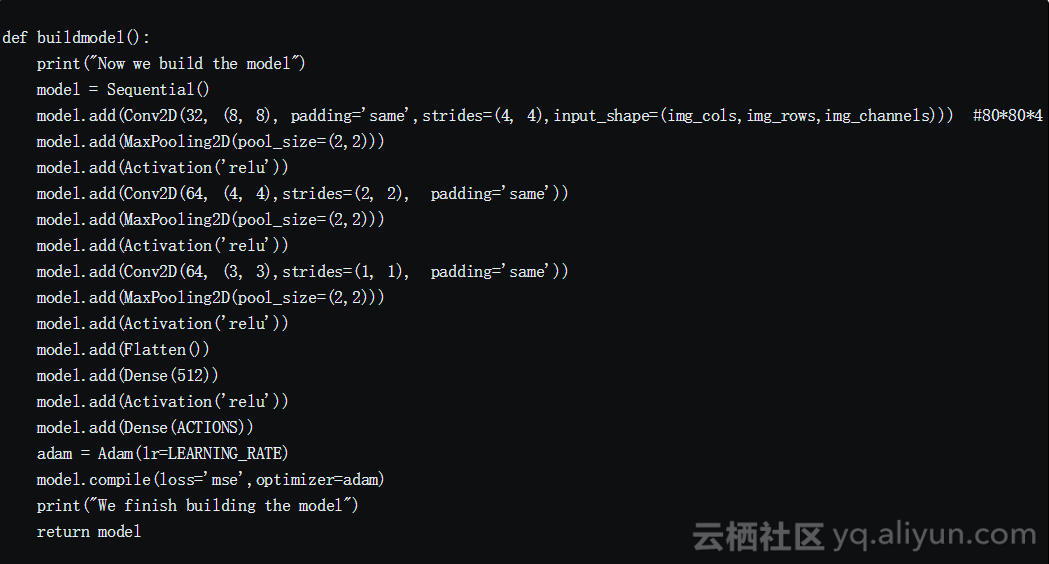
我们使用了一系列的三层卷积层,然后将它们压平为密集层和输出层。仅限CPU的模型不包含池化层,因为我已经删除了许多功能,并且添加池化层会导致已稀疏功能的显着损失。但借助GPU的强大功能,我们可以容纳更多功能,而不会降低帧频。
【最大池图层显着改善了密集特征集的处理。】
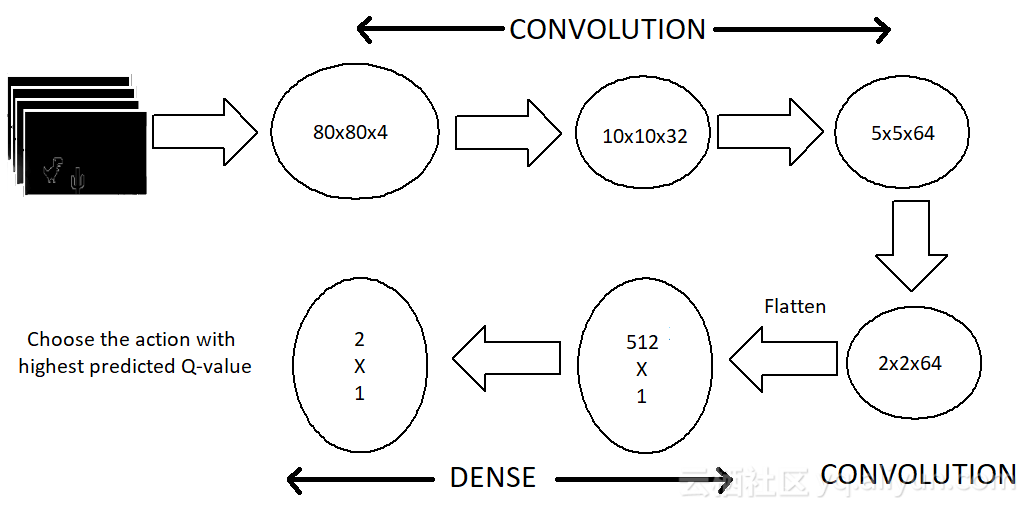
模型架构
我们的输出图层由两个神经元组成,每个神经元代表每个动作的最大预测回报。然后我们选择最大回报(Q值)。
训练
这些是训练阶段发生的事情:
- 以无动作开始并获得初始状态(s_t)
- 观察游戏步数
- 预测并执行操作
- 在回放记忆中存储经验
- 从回放记忆中随机选择一个批次并在其上训练模型
- 重新开始游戏结束
这个代码很长,但很容易理解
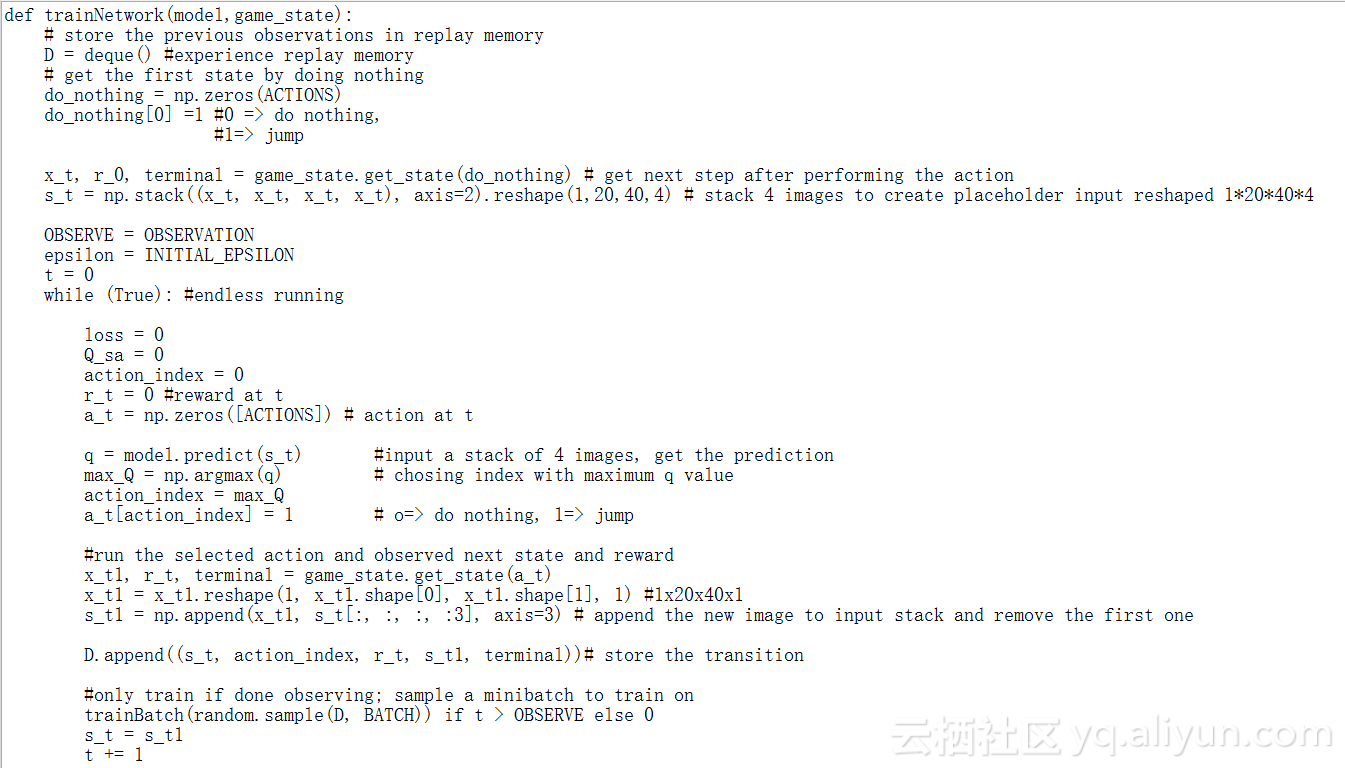
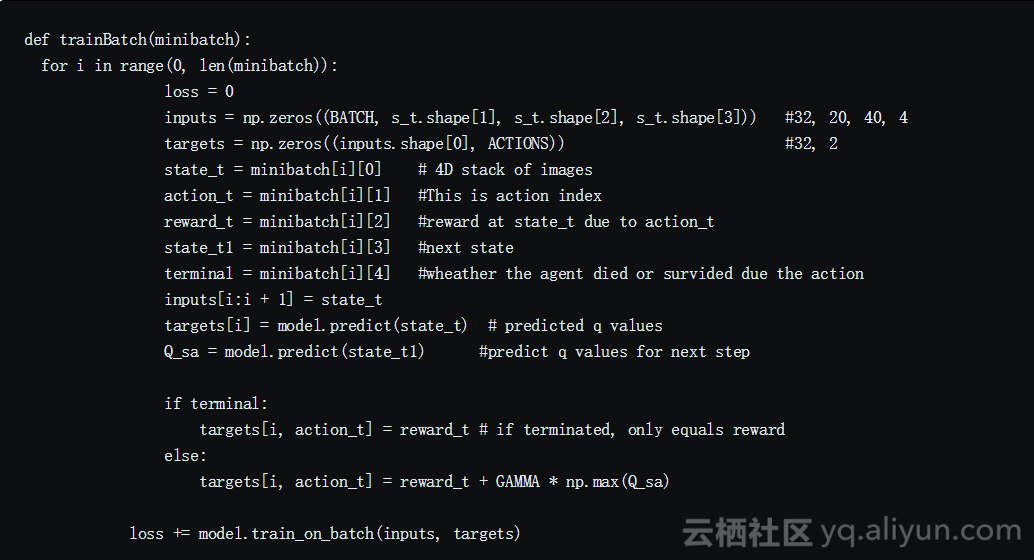
请注意,我们正在从回放记忆中抽取32次随机经验回放,并使用批量的训练方法。其原因是游戏结构中的动作分配不平衡,以及避免过度拟合。
结果
我们应该能够通过使用这个体系结构得到好的结果。GPU显著改善了结果,通过平均分数的提高可以验证。下图显示了训练开始时的平均成绩。每10场游戏的平均分在训练结束时都保持在1000分以上。
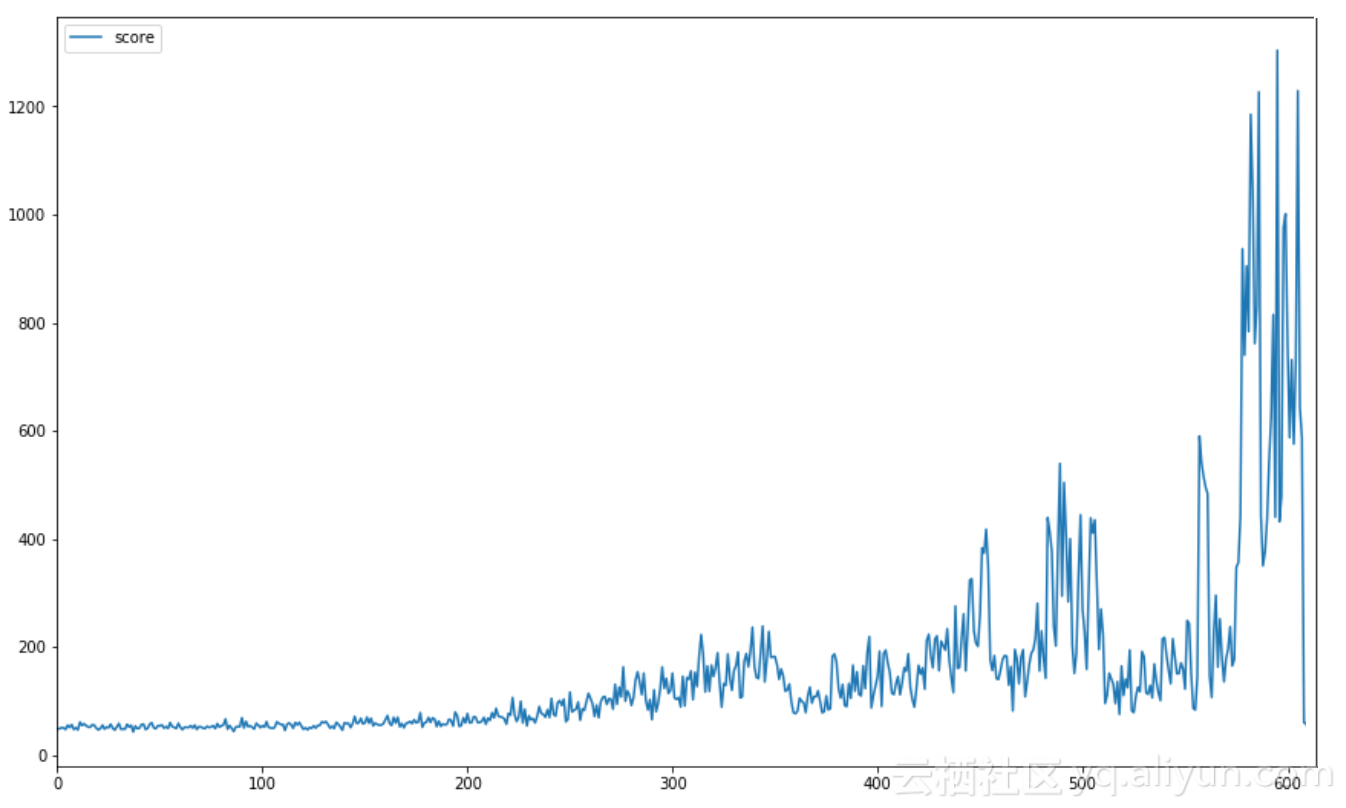
每10场游戏的平均分数
最高的记录是4000+,远远超过了之前250的模型(也远远超出了大多数人的能力!)图中显示了训练期间游戏最高分数的进度(比例= 10)。
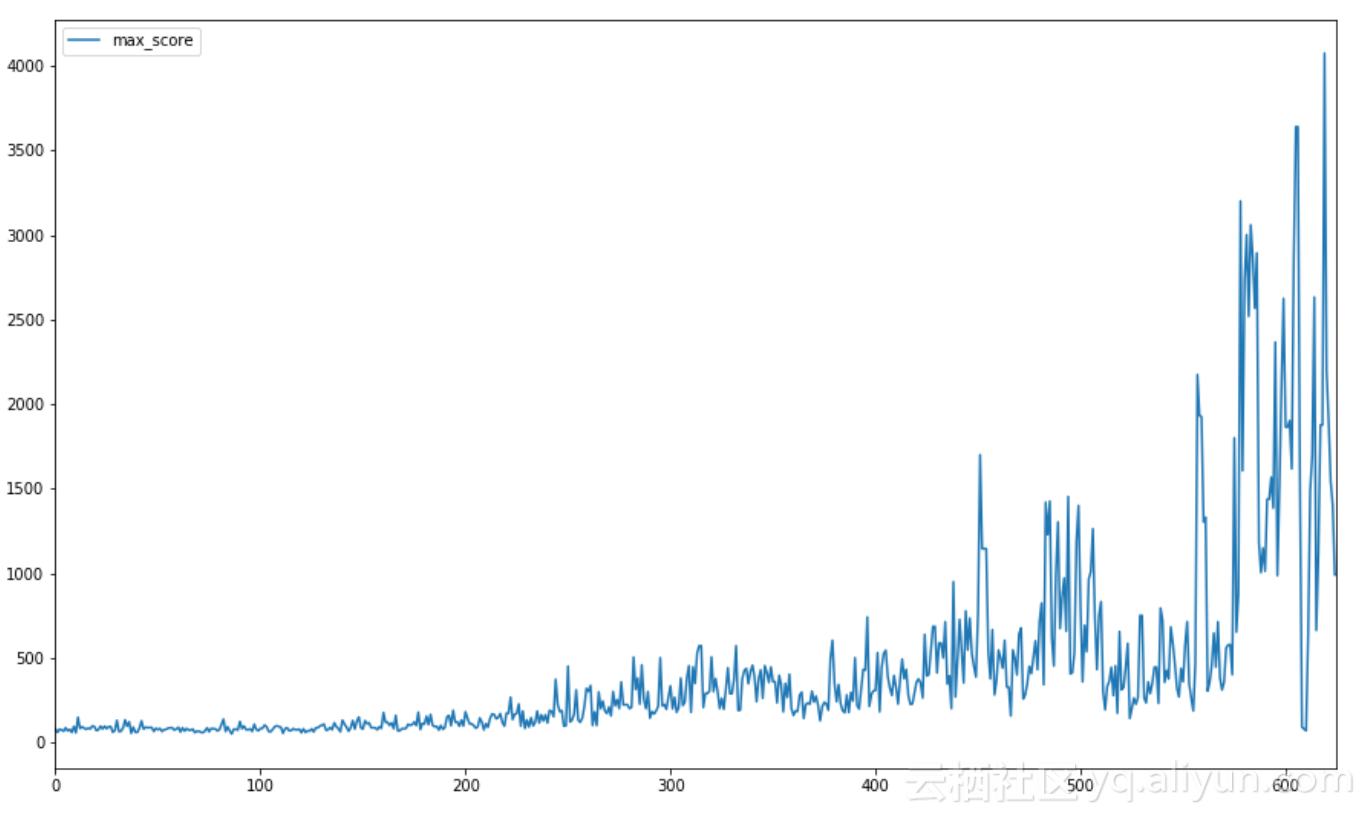
每10场游戏最高得分
Dino的速度与分数成正比,这使得它更难以检测并以更快的速度进行动作。因此整个游戏都是在恒定的速度下进行的。本博客中的代码片段仅供参考。请参考GitHub repo中的函数代码,并添加其他设置。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Build an AI to play Dino Run》,作者:Ravi Mude ,译者:董昭男,审校:。
文章为简译,更为详细的内容,请查看原文。