基于遗传规划的自动机器学习
自动机器学习(Automated/Automatic Machine Learning, AutoML)作为近年来逐渐兴起的热门研究领域,旨在降低机器学习的门槛,使其更加易用。
一般而言,一个完整的机器学习(特别是监督式机器学习)工作流通常包含以下部分,数据清洗,特征工程,模型选择,训练测试以及超参数调优。每一道工序都有相当多的实现选项,且工序之间相互影响,共同决定最终的模型性能。
对于机器学习使用者而言,针对具体任务设计实现合适的工作流并不容易,在很多情况下可能会耗费大量的时间进行迭代。AutoML 的目标便是尽可能地使以上的过程自动化,从而降低使用者的负担。
本次我们要同大家分享的是近年来在 AutoML 领域内比较有影响力的一个工作,基于树表示的工作流优化(Tree-based Pipeline Optimization Tool, TPOT)。
TPOT 的作者为 Randal S. Olson 等人,相关文献为 [1] (2016 EvoStar Best Paper) 和[2] (2016 GECCO Best Paper),我们在这里将两篇文献的内容统一为大家作介绍。
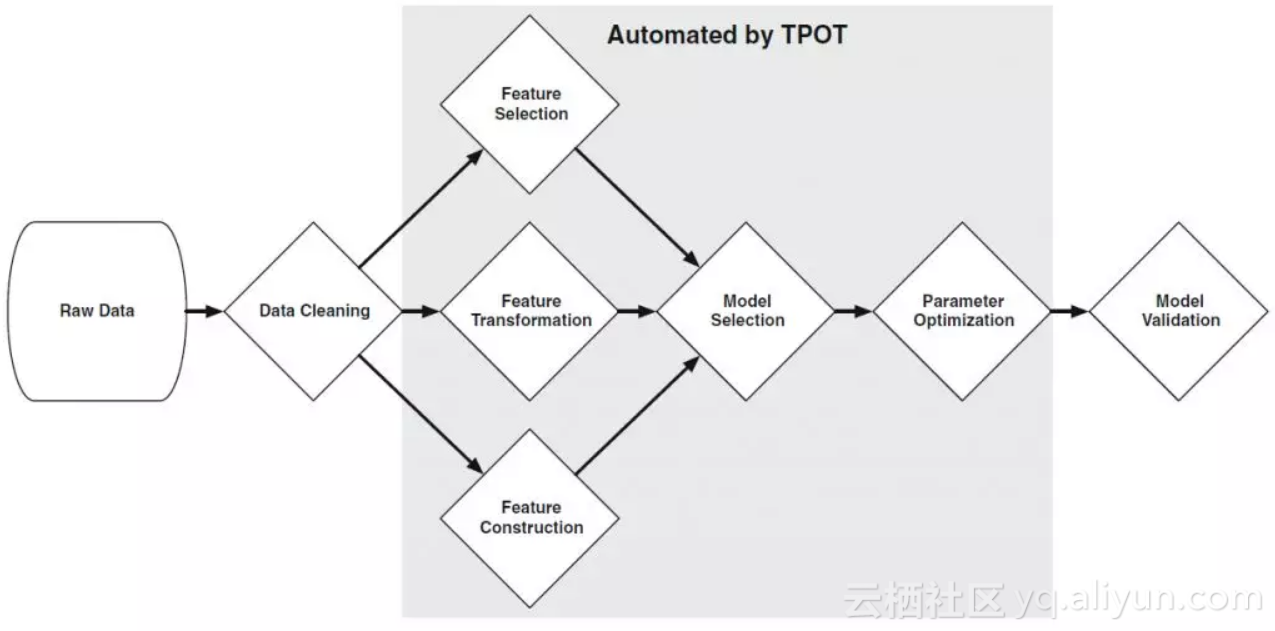
▲ 图1:机器学习工作流中被TPOT优化的部分
如图 1 所示,TPOT 希望从整体上自动优化机器学习的工作流 。在 TPOT 中,一个工作流被定义为一棵树,树上每一个非叶子节点为操作(Operator)节点,叶子节点则为数据节点。数据集从叶子节点流入,经过操作节点进行变换,最终在根节点处进行分类/回归,图 2 给出了一个例子。
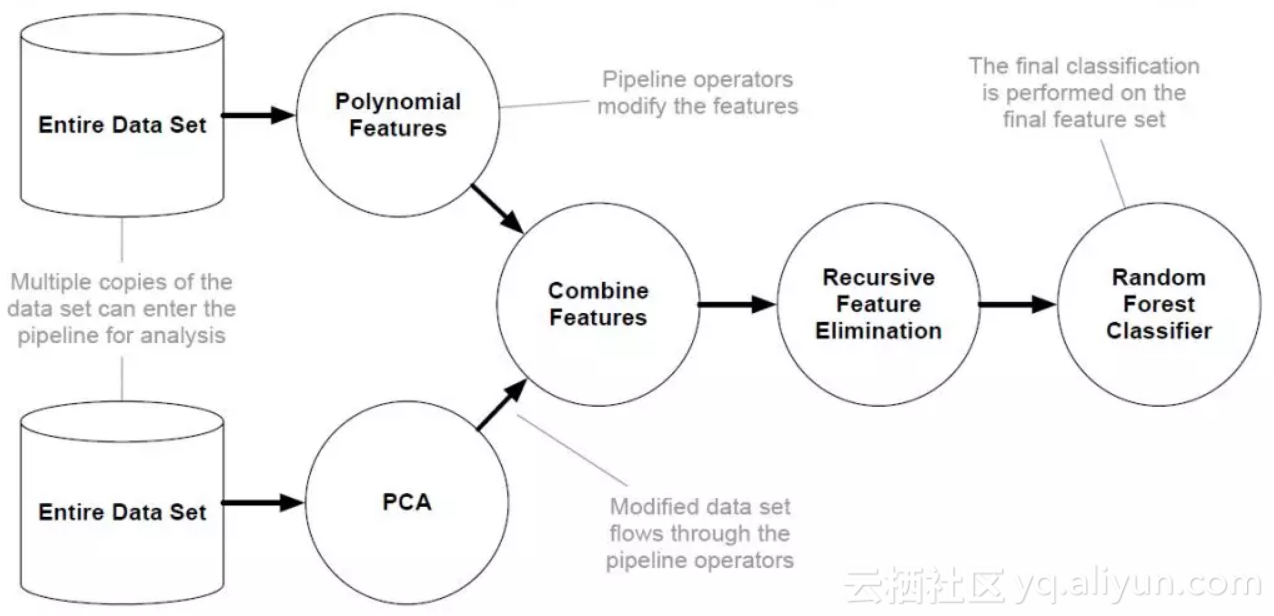
▲ 图2:基于树表示的工作流的一个例子
TPOT 一共定义了 4 种操作节点类型(见图 3),分别是预处理、分解/降维、特征选择以及学习模型。这些操作的底层实现均是基于 Python 的机器学习库 scikit-learn。

▲ 图3:TPOT操作节点类型
有了以上基于树的表示,TPOT 直接利用遗传规划(具体来说,是 Python 库 DEAP 中的 GP 实现)对工作流进行优化。在搜索过程中,任一工作流首先在训练集上训练,然后在独立的验证集上评估(另一种更为耗时的选项是交叉验证)。在搜索结束后,TPOT 将返回最好的工作流所对应的代码。
TPOT 的一个潜在问题在于可能会产生过于复杂的工作流,从而导致过拟合。针对这个问题,论文 [2] 对 TPOT 作出了拓展,将工作流复杂度(即包含的操作节点个数)作为第二个优化目标,提出了 TPOT-Pareto,其使用了类似于 NSGA 中所采用的选择算子。

▲ 图4:部分实验结果
论文 [1] 和 [2] 在很多任务上对 TPOT 和 TPOT-Pareto 进行了评估,实验结果(图 4 给出了在 UCI 数据集上的部分实验结果,其中 Random Forest 包含了 500 棵决策树,TPOT-Random 采用了随机搜索而不是 GP)表明了 TPOT 系的方法在很多任务上都能取得不错的效果。
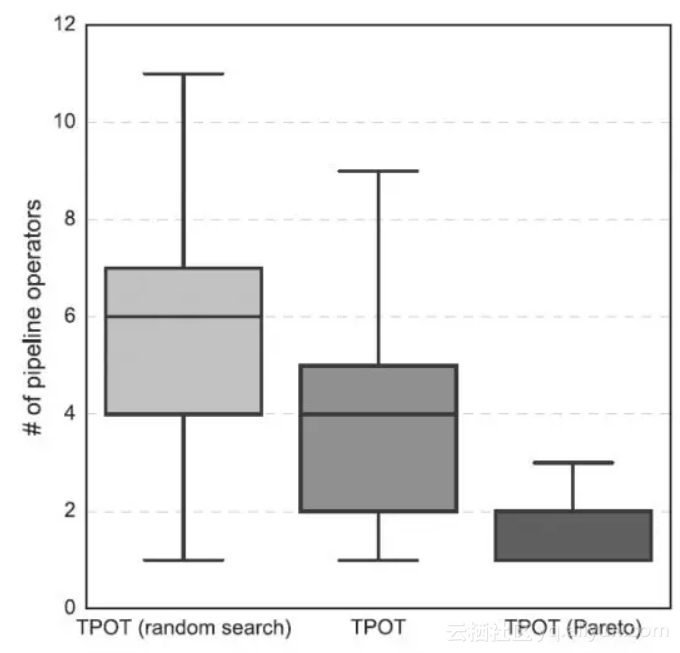
▲ 图5:工作流复杂度对比
图 5 给出了不同方法得到的模型的复杂度,可以看出 TPOT-Pareto 确实能得到更为精简的工作流。一个比较有趣的问题是采用随机搜索的 TPOT-random 在很多任务上(以更高的工作流复杂度)也能够达到 TPOT 以及 TPOT-Pareto 相当的效果。
TPOT 项目已经开源,且仍在开发迭代中,目前整个社区相当活跃,已经有了 4000+ 的 star 和 680+ 的 fork。
TPOT项目地址:
https://github.com/EpistasisLab/tpot
参考文献
[1] Olson, Randal S., et al. “Automating biomedical data science through tree-based pipeline optimization.” European Conference on the Applications of Evolutionary Computation. Springer, Cham, 2016.
[2] Olson, Randal S., et al. “Evaluation of a tree-based pipeline optimization tool for automating data science.” Proceedings of the Genetic and Evolutionary Computation Conference 2016. ACM, 2016.
多目标演化优化深度神经网络
本文主要侧重于分享近期基于多目标演化优化深度神经网络的工作。由于笔者能力有限,如果分享过程中存在疏忽,还请大家不吝赐教与指正。
第一个工作发表于 IEEE Transaction on Neural Networks and Learning Systems 2016,来自 Chong Zhang,Pin Lim,K. Qin 和 Kay Chen Tan 的文章Multiobjective Deep Belief Networks Ensemble for Remaining Useful Life Estimation in Prognostics,本文为预估系统剩余使用周期设计了多目标深度网络集成算法(Multiobjective Deep Belief Networks Ensemble,MODBNE)。
MODBNE 是一个集成学习模型,其以单个 DBN(Deep Belief Networks)模型的准确性和多样性作为优化目标,使用 MOEA/D 算法对 DBN 模型进行优化,将最终获得的一系列占优的 DBN 模型用于集成学习模型。
其中,演化种群中的每一个个体代表一个 DBN 模型,其决策空间由 DBN 模型的隐藏神经元数量、神经网络中的权重以及推理过程中需要的学习率构成,这意味着每一个个体都代表着不同结构的 DBN 模型。
最后,通过以平均学习错误率为目标的单目标 DE 算法优化集成学习模型中各个模型的比重。
MODBNE 在 NASA 的 C-MAPSS 数据集上进行实验,结果表明该算法明显优于其他现有的算法。
第二个工作发表于 IEEE Transaction on Neural Networks and Learning Systems 2017,来自 Jia Liu,Maoguo Gong,Qiguang Miao,Xiaogang Wang 和 Hao Li 的文章 Structure Learning for Deep Neural Networks Based on Multiobjective Optimization,论文提出一种使用多目标优化算法优化深度神经网络的连接结构的方法。
首先,将多层神经网络看成多个单层的神经网络,逐层优化。在优化每一层的时候,以神经网络的表达能力(Representation Ability)和神经网络连接的稀疏性作为优化目标,使用 MOEA/D 算法进行优化。
其中,演化种群中的每一个个体代表单层神经网络的一种配置,神经网络的表达能力用观测数据的 PoE(Products of Experts)评估,稀疏性由神经节点之间连接的个数表示。
通过用该算法优化单层神经网络、多层神经网络以及一些应用层面的神经网络进行测试,实验验证该方法可以大幅提升深度神经网络的效率。
演化深度神经网络
演化算法和人工神经网络都可以看作是对某些自然过程的抽象。早在上世纪 90 年代早期,就有研究试图将二者结合起来,并最终形成了演化人工神经网络(Evolutionary Artificial Neural Networks,EANN)这一分支。
EANN 旨在利用演化算法强大的搜索能力在神经网络的多个层面上(全局参数如学习率,网络拓扑结构,局部参数如连接权值)寻优。
在实际中,这种利用工具来自动设计算法的思路可以在很大程度上减轻算法设计者的负担。同时,在计算资源充足的条件下,针对给定的任务,演化算法往往能成功地发现有效的神经网络结构。
近年来,计算能力的大幅提升和大数据时代的到来助推了深度学习的兴起,在此期间各种深度神经网络(Deep Neural Networks,DNN)被相继提出。然而即使在今天,针对特定问题设计有效的深度神经网络仍然是一项非常困难的任务。
以此为背景,利用自动化工具(比如演化算法)来设计深度神经网络逐渐受到了学术界的一些关注。本文将同大家分享演化深度神经网络的一项近期工作。由于笔者能力有限,如果分享过程中存在疏忽,还请大家不吝赐教与指正。
由于 DNN 连接数巨大,利用演化算法直接优化 DNN 权值的计算代价太高。因此一般采用两层(bilevel)策略对 DNN 进行优化,其顶层由演化算法优化 DNN 的结构和全局参数,其底层依然采用随机梯度下降的方法训练连接权值。
发表在 ICML 2017,来自 Google Brain 的 Esteban Real,Sherry Moore,Andrew Selle,Saurabh Saxena,Yutaka Leon Suematsu,Quoc Le,Alex Kurakin 的文章Large-Scale Evolution of Image Classifiers,提出了一种针对图像分类的 DNN 的分布式演化算法。

▲ 图1:文章提出的分布式演化算法
算法的流程如图 1 所示,该算法维护了一个 DNN 种群,种群中每一个个体都是一个已经训练好的 DNN 模型,其适应度即为该模型在验证集上的准确率。
大量的计算节点(worker)被用来对 DNN 种群进行演化。具体而言,所有的 worker 处在分布式环境下,共享存储 DNN 种群的文件系统,并以异步的方式工作。
每一个当前空闲的 worker 都会从 DNN 种群中随机选取两个 DNN 模型,然后将较差的 DNN 直接从种群中删除,并基于较好的 DNN 变异生成一个子代个体加入 DNN 种群。
整个过程中个体的编码是图,图上每一个顶点表示一个三阶张量(比如卷积层)或者一个激活函数,每一条边则表示恒等连接(identity connection)或者卷积。变异操作则包括重置权值,插入删除神经层,插入删除神经层之间的连接等等。
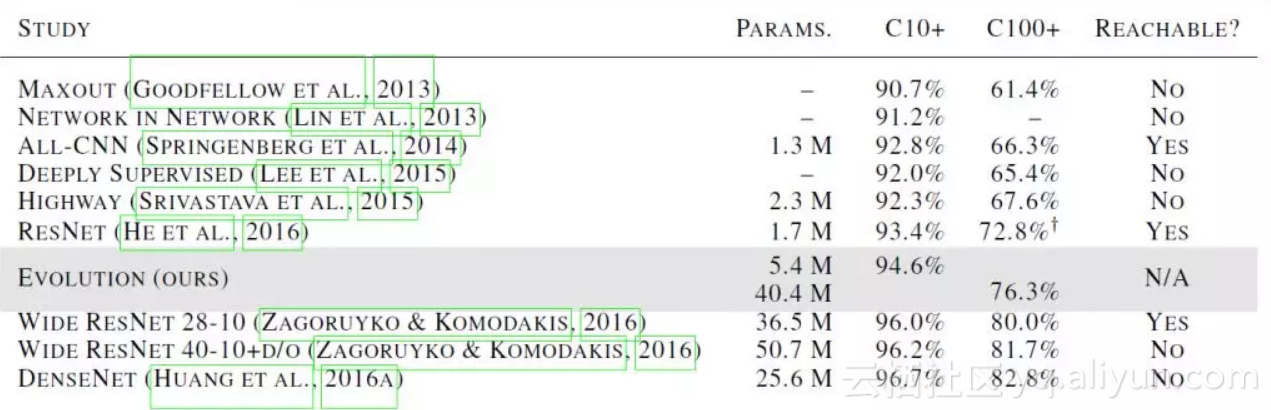
实验中,种群规模被设置为 1000,并有 250 个 worker 参与,在 CIFAR-10 和 CIFAR-100 数据集上的实验结果如图 2 所示,相比于手工设计的 DNN,用此分布式演化算法得到的 DNN 能够取得有竞争力的结果。
最后,再附上 Github 上几篇进化计算在 AutoML 上的应用论文。

■ 论文 | Evolving Neural Networks through Augmenting Topologies
■ 链接 | https://www.paperweekly.site/papers/1979
■ 作者 | Kenneth O. Stanley / Risto Miikkulainen
Abstract
An important question in neuroevolution is how to gain an advantage from evolving neural network topologies along with weights. We present a method, NeuroEvolution of Augmenting Topologies (NEAT), which outperforms the best fixed-topology method on a challenging benchmark reinforcement learning task. We claim that the increased efficiency is due to (1) employing a principled method of crossover of different topologies, (2) protecting structural innovation using speciation, and (3) incrementally growing from minimal structure. We test this claim through a series of ablation studies that demonstrate that each component is necessary to the system as a whole and to each other. What results is significantly faster learning. NEAT is also an important contribution to GAs because it shows how it is possible for evolution to both optimize and complexify solutions simultaneously, offering the possibility of evolving increasingly complex solutions over generations, and strengthening the analogy with biological evolution.

■ 论文 | Autostacker: A Compositional Evolutionary Learning System
■ 链接 | https://www.paperweekly.site/papers/1980
■ 作者 | Boyuan Chen / Harvey Wu / Warren Mo / Ishanu Chattopadhyay / Hod Lipson
Abstract
We introduce an automatic machine learning (AutoML) modeling architecture called Autostacker, which combines an innovative hierarchical stacking architecture and an Evolutionary Algorithm (EA) to perform efficient parameter search. Neither prior domain knowledge about the data nor feature preprocessing is needed. Using EA, Autostacker quickly evolves candidate pipelines with high predictive accuracy. These pipelines can be used as is or as a starting point for human experts to build on. Autostacker finds innovative combinations and structures of machine learning models, rather than selecting a single model and optimizing its hyperparameters. Compared with other AutoML systems on fifteen datasets, Autostacker achieves state-of-art or competitive performance both in terms of test accuracy and time cost.

■ 论文 | Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
■ 链接 | https://www.paperweekly.site/papers/1981
■ 源码 | https://github.com/uber-common/deep-neuroevolution
Abstract
Deep artificial neural networks (DNNs) are typically trained via gradient-based learning algorithms, namely backpropagation. Evolution strategies (ES) can rival backprop-based algorithms such as Q-learning and policy gradients on challenging deep reinforcement learning (RL) problems. However, ES can be considered a gradient-based algorithm because it performs stochastic gradient descent via an operation similar to a finite-difference approximation of the gradient. That raises the question of whether non-gradient-based evolutionary algorithms can work at DNN scales. Here we demonstrate they can: we evolve the weights of a DNN with a simple, gradient-free, population-based genetic algorithm (GA) and it performs well on hard deep RL problems, including Atari and humanoid locomotion. The Deep GA successfully evolves networks with over four million free parameters, the largest neural networks ever evolved with a traditional evolutionary algorithm. These results (1) expand our sense of the scale at which GAs can operate, (2) suggest intriguingly that in some cases following the gradient is not the best choice for optimizing performance, and (3) make immediately available the multitude of neuroevolution techniques that improve performance. We demonstrate the latter by showing that combining DNNs with novelty search, which encourages exploration on tasks with deceptive or sparse reward functions, can solve a high-dimensional problem on which reward-maximizing algorithms (e.g.\ DQN, A3C, ES, and the GA) fail. Additionally, the Deep GA is faster than ES, A3C, and DQN (it can train Atari in ∼4 hours on one desktop or ∼1 hour distributed on 720 cores), and enables a state-of-the-art, up to 10,000-fold compact encoding technique.

■ 论文 | Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
■ 链接 | https://www.paperweekly.site/papers/1982
■ 源码 | https://github.com/uber-common/deep-neuroevolution
Abstract
Evolution strategies (ES) are a family of black-box optimization algorithms able to train deep neural networks roughly as well as Q-learning and policy gradient methods on challenging deep reinforcement learning (RL) problems, but are much faster (e.g. hours vs. days) because they parallelize better. However, many RL problems require directed exploration because they have reward functions that are sparse or deceptive (i.e. contain local optima), and it is not known how to encourage such exploration with ES. Here we show that algorithms that have been invented to promote directed exploration in small-scale evolved neural networks via populations of exploring agents, specifically novelty search (NS) and quality diversity (QD) algorithms, can be hybridized with ES to improve its performance on sparse or deceptive deep RL tasks, while retaining scalability. Our experiments confirm that the resultant new algorithms, NS-ES and a version of QD we call NSR-ES, avoid local optima encountered by ES to achieve higher performance on tasks ranging from playing Atari to simulated robots learning to walk around a deceptive trap. This paper thus introduces a family of fast, scalable algorithms for reinforcement learning that are capable of directed exploration. It also adds this new family of exploration algorithms to the RL toolbox and raises the interesting possibility that analogous algorithms with multiple simultaneous paths of exploration might also combine well with existing RL algorithms outside ES.
原文发布时间为:2018-05-30
本文作者:让你更懂AI
本文来自云栖社区合作伙伴“PaperWeekly ”,了解相关信息可以关注“PaperWeekly”。
