这一个章节中作者主要运用了Logistic回归分类器进行分类,分类器的函数形式是Sigmoid函数,过程可以概括为:每个输入特征乘以一个回归系数,然后将所有的结果值相加,将总和带入Sigmoid函数中进行分类,整个过程也可以被看成概率估计。
首先先来看书中的一段程序(程序5-1 Logistic回归梯度上升优化算法)
#此函数的作用是读取数据集文件,将数据分别存于两个列表中,在函数最后返回
def LoadDataSet(): #加载数据信息函数
dataMat = [] #创建空列表
labelMat = [] #同上
fr = open('machinelearninginaction/Ch05/testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
def Sigmoid(inX):
return 1.0/(1+exp(-inX))
#梯度上升优化算法
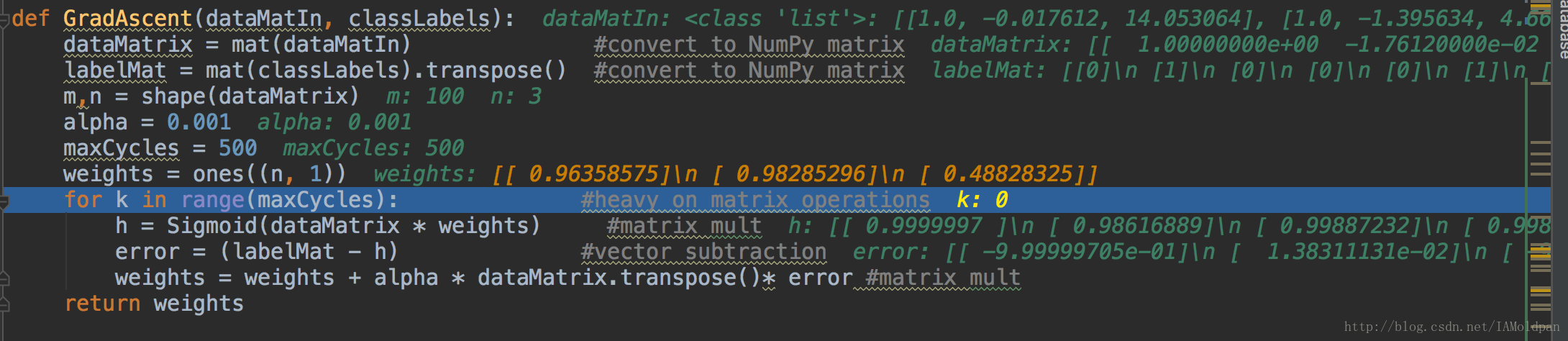
def GradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #numpy中的array转(mat)矩阵函数
labelMat = mat(classLabels).transpose() #同上,另外转置
m,n = shape(dataMatrix)
alpha = 0.001 #梯度移动步长
maxCycles = 500 #移动循环次数
weights = ones((n, 1))
for k in range(maxCycles):
h = Sigmoid(dataMatrix * weights) #回归系数与数据向量相乘带入Sigmoid函数中,得到h,注意h是向量
error = (labelMat - h) #误差为标记值(labelMat)-预测值(h)
weights = weights + alpha * dataMatrix.transpose()* error #这个为梯度更新公式,后文介绍
return weights执行代码如下,这里省略了import。
if __name__ == "__main__":
dataArr, labelMat = logRegres.LoadDataSet()
weights = logRegres.GradAscent(dataArr, labelMat)
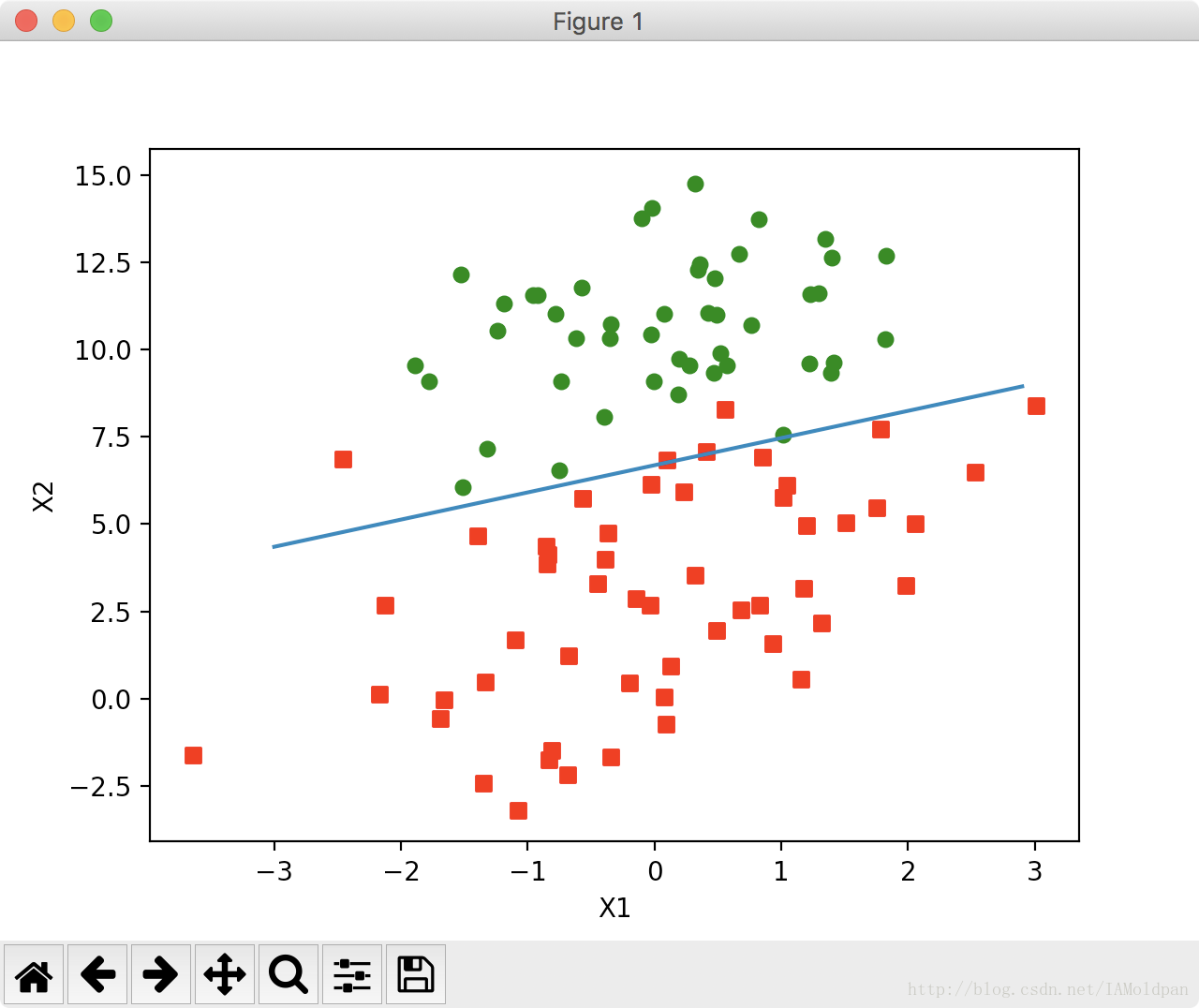
logRegres.PlotBestFit(weights.getA())上述方程实现的步骤:
1、初始化回归系数;
2、计算整个数据集的梯度;
3、使用alpha*gradient更新回归系数的向量
4、返回回归系数
5、重复2-4步骤R次
设置断点,将程序的debug一下,可以发现:
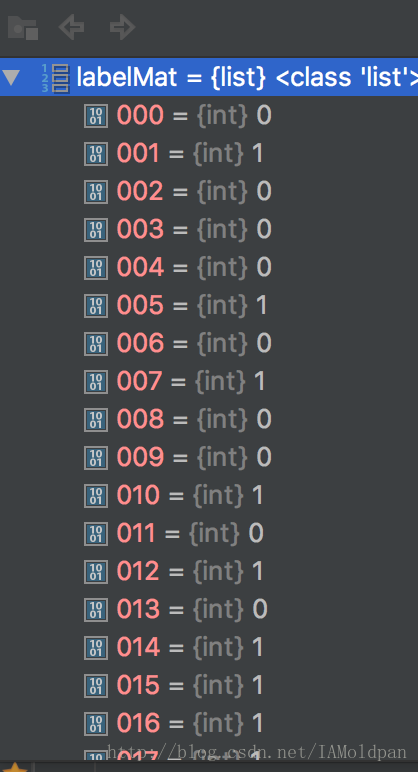
在LoadDataSet函数中dataArr和labelMat分别为二维列表和一维列表
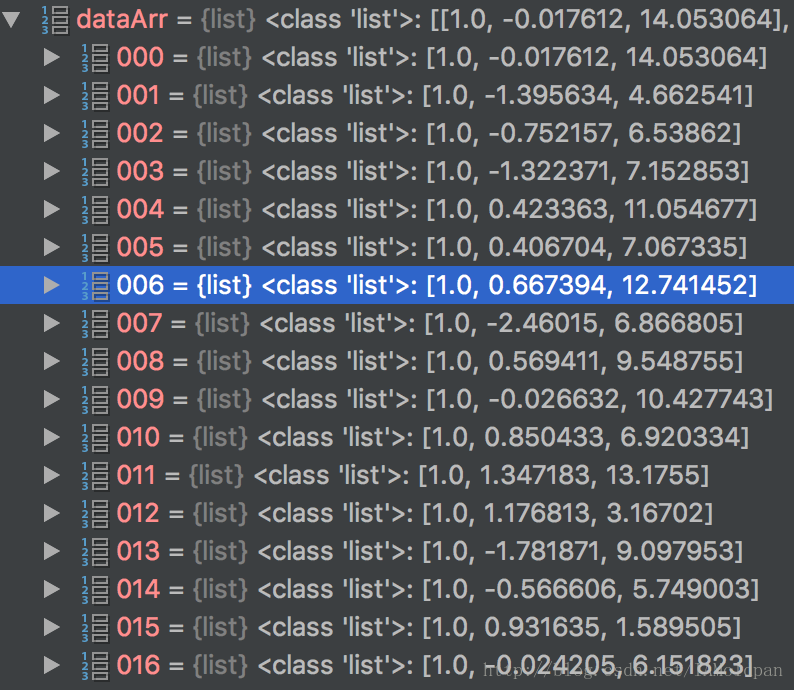
而在GradAscent函数中,dataArr和labelMat变化为100*3和1*100的矩阵,过程中的乘法是矩阵运算不是单独的变量运算。
现在来介绍程序中涉及到的知识点:
Sigmoid函数
Sigmoid的函数形式为
相比于阶跃函数,Sigmoid函数具有在突变处较平滑、数学上好处理的特点。
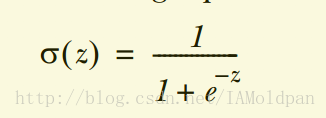
下面两个图片为Sigmoid函数在不同尺度下的函数图:
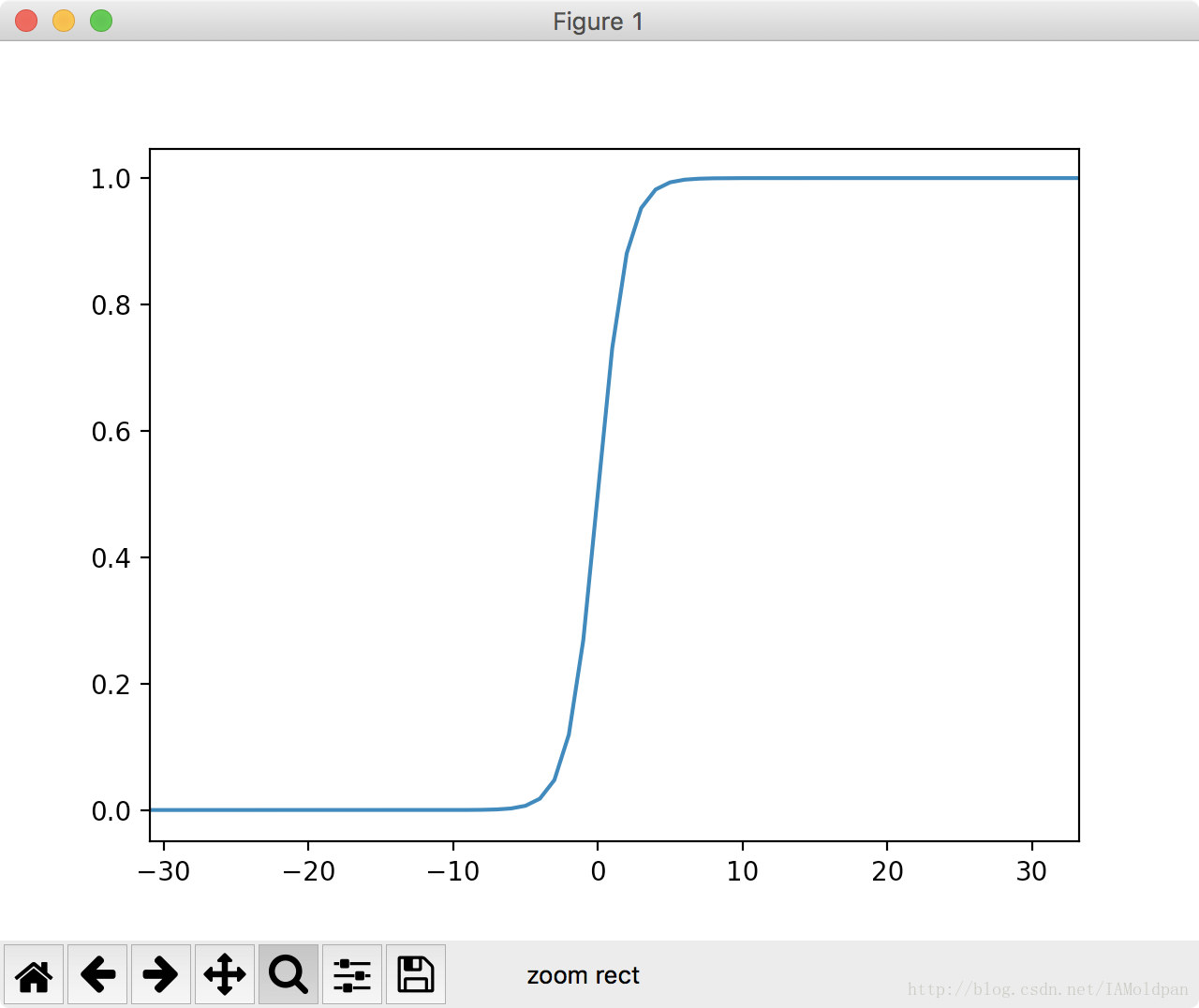
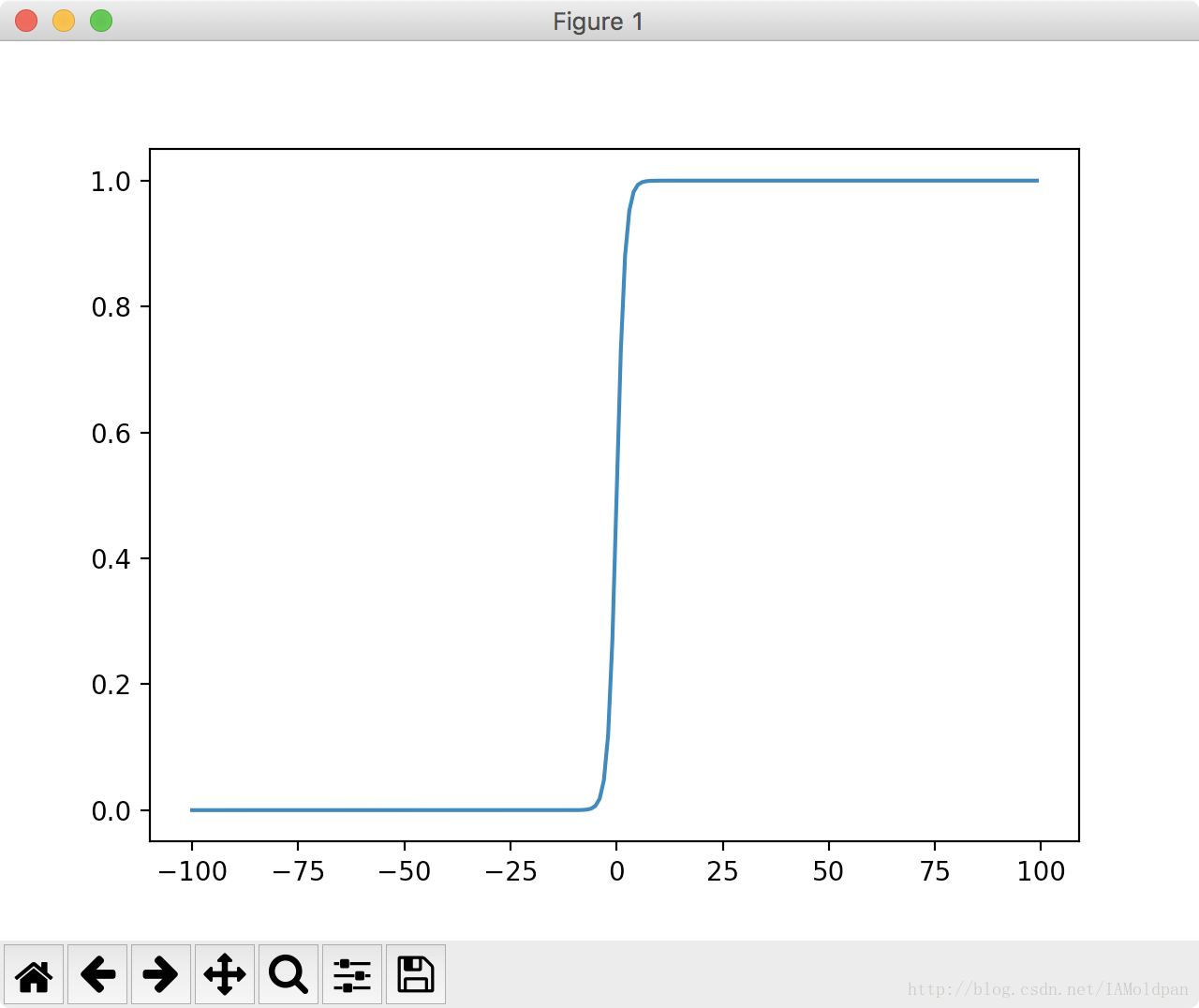
可以看到只要尺度足够大,在x=0点处Sigmoid函数看起来就像阶跃函数一样。
程序中是将回归系数(weights)与数据集相乘(dataMatrix),带入sigmoid函数中得到一个0-1的数(h),h将会与标记值进行比较(label),标记值即准确值,h即预测值,它们两个之间的差距越小代表预测越准确,所以程序的目的主要是使error(误差)变得最小,这就是梯度进行移动的目的。
递推公式
上面程序中有一段程序:
weights = weights + alpha * dataMatrix.transpose()* error文中并没有进行推导,这里借用吴恩达老师的机器学习课来说明一下
首先来说明一下损失函数,损失函数说白了就是预测值与标记值的均平方和,当预测值与标记值愈加相同时,损失函数的返回值越小

而我们程序中的需要改变weights(回归系数)来达到最佳的分类效果,在这个程序中我们的weights中有很多参数(大于等于2),这里就用到了这个公式:
这个公式在书中也进行了讲解,只不过书中讲解较为简单,上式中为两个参数的梯度移动公式,吴恩达老师的意思是这两个参数应该同时变化: 
进而推导出以下的式子,这是一个递推式子。
进行推导:
最终化为如下的式子:
上式就是程序中那个递推公式。这里只是简单的公式推导,具体的请大家看吴恩达老师的机器学习课程,讲解的比较详细。
https://www.coursera.org/learn/machine-learning/lecture/zcAuT/welcome-to-machine-learning


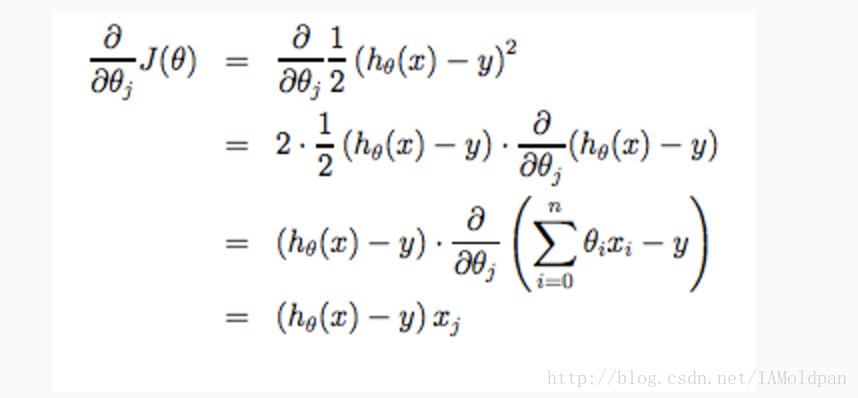

程序运行后,得到如下的图像: