转载自:http://blog.csdn.net/u011534057/article/details/51247388
【论文信息】
《Fully Convolutional Networks for Semantic Segmentation》
CVPR 2015 best paper
Reference link:
http://blog.csdn.NET/tangwei2014
http://blog.csdn.net/u010025211/article/details/51209504
概览&主要贡献
提出了一种end-to-end的做semantic segmentation的方法,简称FCN。
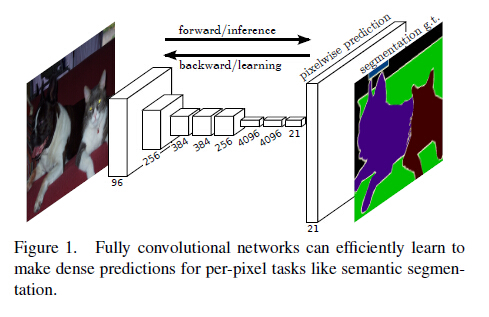
如下图所示,直接拿segmentation 的 ground truth作为监督信息,训练一个端到端的网络,让网络做pixelwise的prediction,直接预测label map。
(笔者自己类比思想:faster rcnn中的rbn->(fc->region proposal) label map-> fast-rcnn for fine tuning)
【方法简介】
主要思路是把CNN改为FCN,输入一幅图像后直接在输出端得到dense prediction,也就是每个像素所属的class,从而得到一个end-to-end的方法来实现image semantic segmentation。
我们已经有一个CNN模型,首先要把CNN的全连接层看成是卷积层,卷积模板大小就是输入的特征map的大小,也就是说把全连接网络看成是对整张输入map做卷积,全连接层分别有4096个6*6的卷积核,4096个1*1的卷积核,1000个1*1的卷积核,如下图:
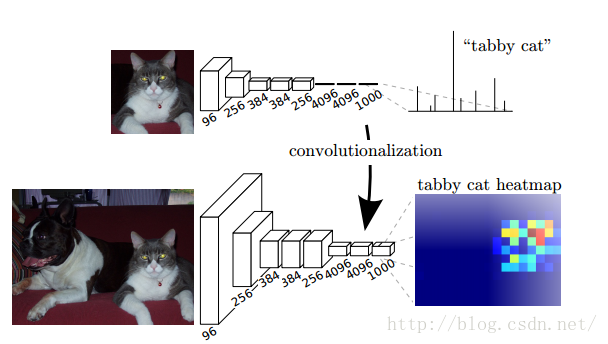
接下来就要对这1000个1*1的输出,做upsampling,得到1000个原图大小(如32*32)的输出,这些输出合并后,得到上图所示的heatmap。
【细节记录】
dense prediction
这里通过upsampling得到dense prediction,作者研究过3种方案:
1,shift-and-stitch:设原图与FCN所得输出图之间的降采样因子是f,那么对于原图的每个f*f的区域(不重叠),“shift the input x pixels to the right and y pixels down for every (x,y) ,0 < x,y < f." 把这个f*f区域对应的output作为此时区域中心点像素对应的output,这样就对每个f*f的区域得到了f^2个output,也就是每个像素都能对应一个output,所以成为了dense prediction。
2,filter rarefaction:就是放大CNN网络中的subsampling层的filter的尺寸,得到新的filter:
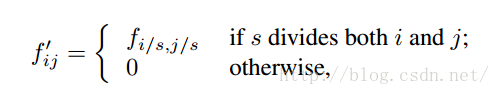
其中s是subsampling的滑动步长,这个新filter的滑动步长要设为1,这样的话,subsampling就没有缩小图像尺寸,最后可以得到dense prediction。
以上两种方法作者都没有采用,主要是因为这两种方法都是trad-off的,原因是:
对于第二种方法, 下采样的功能被减弱,使得更细节的信息能被filter看到,但是receptive fileds会相对变小,可能会损失全局信息,且会对卷积层引入更多运算。
对于第一种方法,虽然receptive fileds没有变小,但是由于原图被划分成f*f的区域输入网络,使得filters无法感受更精细的信息。
重点方法:
反卷积层->pixel wise->bp parameters->实现把conv的前传和反传过程对调一下即可
3,这里upsampling的操作可以看成是反卷积(deconvolutional),卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。
fusion prediction
以上是对CNN的结果做处理,得到了dense prediction,而作者在试验中发现,得到的分割结果比较粗糙,所以考虑加入更多前层的细节信息,也就是把倒数第几层的输出和最后的输出做一个fusion,实际上也就是加和:
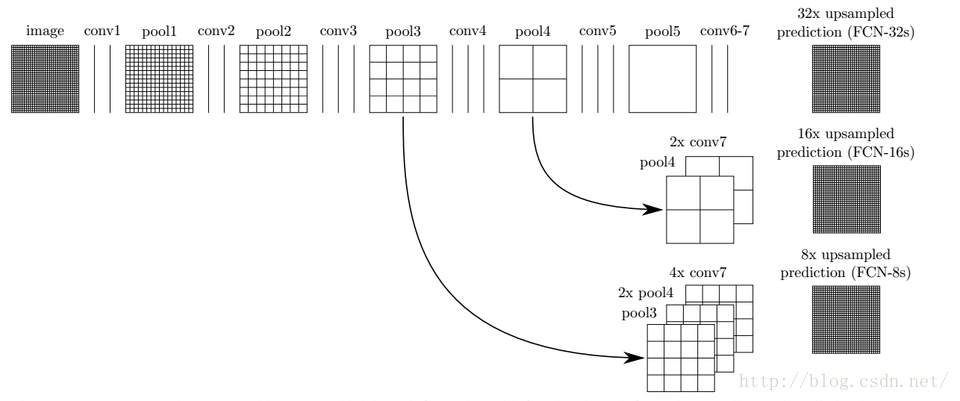
这样就得到第二行和第三行的结果,实验表明,这样的分割结果更细致更准确。在逐层fusion的过程中,做到第三行再往下,结果又会变差,所以作者做到这里就停了。可以看到如上三行的对应的结果:

问题&解决办法
1.如何做pixelwise的prediction?
传统的网络是subsampling的,对应的输出尺寸会降低,要想做pixelwiseprediction,必须保证输出尺寸。
解决办法:
(1)对传统网络如AlexNet,VGG等的最后全连接层变成卷积层。
例如VGG16中第一个全连接层是25088x4096的,将之解释为512x7x7x4096的卷积核,则如果在一个更大的输入图像上进行卷积操作(上图的下半部分),原来输出4096维feature的节点处(上图的上半部分),就会输出一个coarsefeature map。
这样做的好处是,能够很好的利用已经训练好的supervisedpre-training的网络,不用像已有的方法那样,从头到尾训练,只需要fine-tuning即可,训练efficient。
(2)加In-network upsampling layer。
对中间得到的featuremap做bilinear上采样,就是反卷积层。实现把conv的前传和反传过程对调一下即可。
2.如何refine,得到更好的结果?
upsampling中步长是32,输入为3x500x500的时候,输出是544x544,边缘很不好,并且limit thescale of detail of the upsampling output。
解决办法:
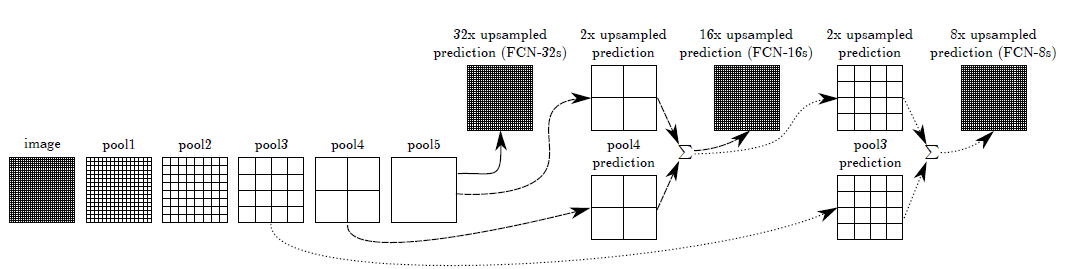
采用skiplayer的方法,在浅层处减小upsampling的步长,得到的finelayer 和 高层得到的coarselayer做融合,然后再upsampling得到输出。
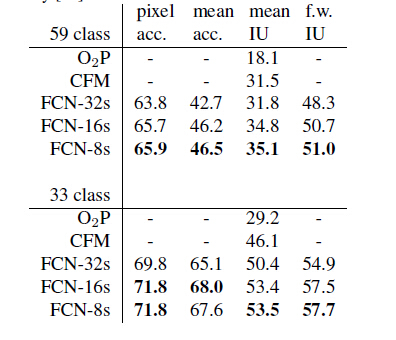
这种做法兼顾local和global信息,即文中说的combiningwhat and where,取得了不错的效果提升。FCN-32s为59.4,FCN-16s提升到了62.4,FCN-8s提升到62.7。可以看出效果还是很明显的。
3.训练细节
用AlexNet,VGG16或者GoogleNet训练好的模型做初始化,在这个基础上做fine-tuning,全部都fine-tuning。
采用wholeimage做训练,不进行patchwise sampling。实验证明直接用全图已经很effectiveand efficient。
对classscore的卷积层做全零初始化。随机初始化在性能和收敛上没有优势。
【实验设计】
1,对比3种性能较好的几种CNN:AlexNet, VGG16, GoogLeNet进行实验,选择VGG16
2,对比FCN-32s-fixed, FCN-32s, FCN-16s, FCN-8s,证明最好的dense prediction组合是8s
3,FCN-8s和state-of-the-art对比是最优的,R-CNN, SDS. FCN-16s
4,FCN-16s和现有的一些工作对比,是最优的
5,FCN-32s和FCN-16s在RGB-D和HHA的图像数据集上,优于state-of-the-art
【总结】
优点
1,训练一个end-to-end的FCN模型,利用卷积神经网络的很强的学习能力,得到较准确的结果,以前的基于CNN的方法都是要对输入或者输出做一些处理,才能得到最终结果。
2,直接使用现有的CNN网络,如AlexNet, VGG16, GoogLeNet,只需在末尾加上upsampling,参数的学习还是利用CNN本身的反向传播原理,"whole image training is effective and efficient."
3,不限制输入图片的尺寸,不要求图片集中所有图片都是同样尺寸,只需在最后upsampling时按原图被subsampling的比例缩放回来,最后都会输出一张与原图大小一致的dense prediction map。
缺陷
根据论文的conclusion部分所示的实验输出sample如下图:

可以直观地看出,本文方法和Groud truth相比,容易丢失较小的目标,比如第一幅图片中的汽车,和第二幅图片中的观众人群,如果要改进的话,这一点上应该是有一些提升空间的。