AWR相信DBA们都不陌生。Automatic Workload Repository,自动负载信息库,就是Oracle把数据库中比较重要的性能视图里的信息,定期从内存保存到数据库里面。默认情况下,Oracle 会每个一个小时保存一次。另外,Oracle也有机制保证信息库的大小不至于无限增长,所以一般信息库只保留7天的数据。默认是保存在SYSAUX表空间中。主要的信息涵盖了Oracle较重要的性能相关信息。

底层存储为WRH$* 表, 通常可通过DBA_HIST_*访问,总共有100多张表。
对于AWR, 常规的用法是生成AWR或者ASH报告。
下面列举了几个最常见的方法。
@?/rdbms/admin/awrrpt.sql -- 标准报告,特定时间段内总体性能报告
@?/rdbms/admin/awrddrpt.sql -- 对比报告,两个时间段内性能对比
@?/rdbms/admin/ashrpt.sql -- ASH报告,特定时间段内历史会话性能报告
@?/rdbms/admin/awrsqrpt.sql -- SQL报告,特定时间段内SQL性能报告
AWR/ASH报告很不错,但也有一些缺陷。
首先,AWR反应的是点对点的数据。比如说,我生成一个今天9:00到12:00的AWR报告,那么,我看到的,就是12:00和9:00两个时间点的变化。但是,9:00-10:00, 10:00-11:00,11:-12:00 分别是什么样的,我们看不到。
另外一个问题,AWR把数据都罗列出来,但却缺乏数据间的联系.
AWR混入大量无用数据, 导致生成AWR报告需要30秒到几分钟的时间,所以,如果我们有裸数据,其实可以更高效,更深入的挖掘Oracle数据库的性能信息。
在裸数据里面,记录的各种指标主要有4类
最多的一种是"累计值"
举个例子 dba_hist_sysstat 里会记录数据库的逻辑读。记录的不是这一个小时产生的逻辑读,而是从数据库启动到产生快照的时候的总的逻辑读。这就叫累计值,大多数的指标的是累计值。
也有部分数据记录的是"当前值"
比如说,数据库当前的PGA使用量,数据库的会话数等,还有比较特殊的,会记录两次快照之间的变化值。我们可以认为,这是一种预计算,最常见的记录变化值的两类数据,分别是SQL相关统计信息,以及段(segment)相关统计信息,当然,SQL/Segment记录变化值的同时,也记录了累计值。
还有一类,记录的是”统计值“
就是把一段时间内的数据,做了统计之后保存了起来,这些主要是METRIC类的数据。比如说,每秒CPU, 每秒最大等待时间等。
对于DBA来说,最关心的一般是变化值,
两次快照之间的变化量。这是一个简单的SQL, 获取数据库的历史性能信息里的redo size 信息
select SNAP_ID,STAT_NAME,VALUE from DBA_HIST_SYSSTAT
where STAT_NAME=‘redo size’ order by snap_id;
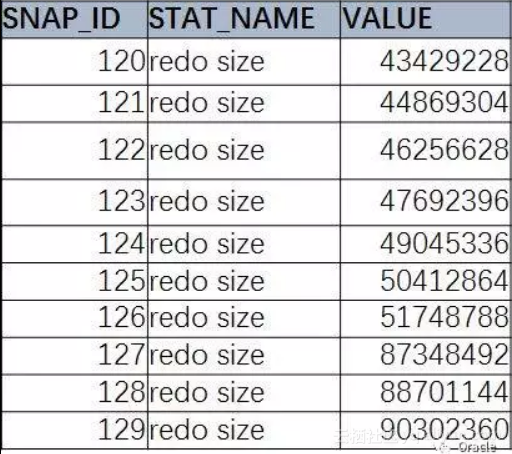
我们现在看到的,就是累计值。那么,怎么方便的获取变化值呢?
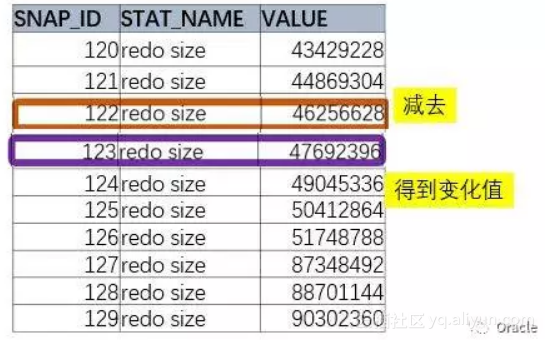
1、要取得变化值,需要取出后面的记录,减去前面的记录。
如果仅仅是两个时间点,最简单的方法就是访问这个表两次,然后相减。
select a.value - b.value
from DBA_HIST_SYSSTAT A,DBA_HIST_SYSSTAT B
where A.STAT_NAME=‘redo size’ and
A.STAT_NAME = B.STAT_NAME and a.snap_id = 123 and b.snap_id = 122
这样得到是两个点之间的差值,但是对我们来说,玩玩是不够的。
2、有时候,我们希望得到一个时间段内,每两个连续快照之间的变化值。比如说,9:00-21:00, 我们希望获得 9:00-10:00, 10:-11:00... 20:00-21:00, 每个时间段分别的变化值。
这里就涉及到Oracle的分析函数了分析函数
Oracle的分析函数提供了在一个结果集内,跨行访问数据的能力。分析函数里面的LEAD/LAG正是跨行获取数据的利器
LAG : 同一组内,排在当前行之前的数据
LEAD : 同一组内,排在当前行之后的数据
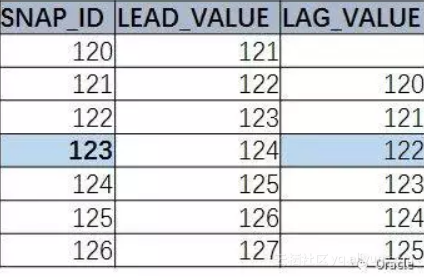
如图所示,可以看到,我们要的是拿当前value 减去 lag value。
select snap_id,stat_name,
value-lag(value) over
(partition by stat_name order by snap_id)
from dba_hist_sysstat
where stat_name = 'redo size'
order by snap_id;
这就是分析函数LAG的完整语法。
3、我们一般不会满足获取一个指标的变化值的,下面的表,才是我们希望获得的。
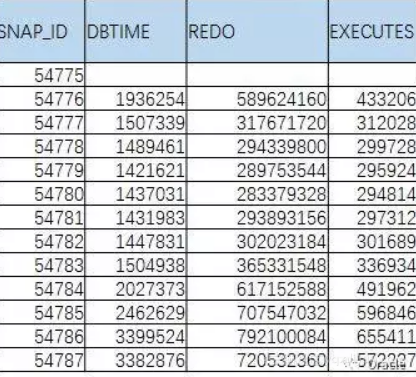
这里又引入了进阶SQL的另一个写法:行列转换。

大家可以体会一下,如何使用sum(case when .. then .. end )或者max(case when .. then .. end )的形式的形式来进行行列转换,但用Case when来写行列转换,很容易使SQL冗长,而且容易出错。
Oracle 11g中,提供了更方便的方式进行行列转换

大家可以看到,标黄大写的PIVOT, 正是Oracle 11g中引入的行列转换利器。使用PIVOT, 增减指标极其简单:

很轻松就加了两个指标,如果觉得列名不好看,也可以自己指定。

其实,我们可以很轻松的就把AWR报告中的"Load Profile"部分通过行列转换给取出来,而且,是多个连续变化的值。

把跑的结果拷到Excel, 很容易就出来一个漂亮的趋势图。
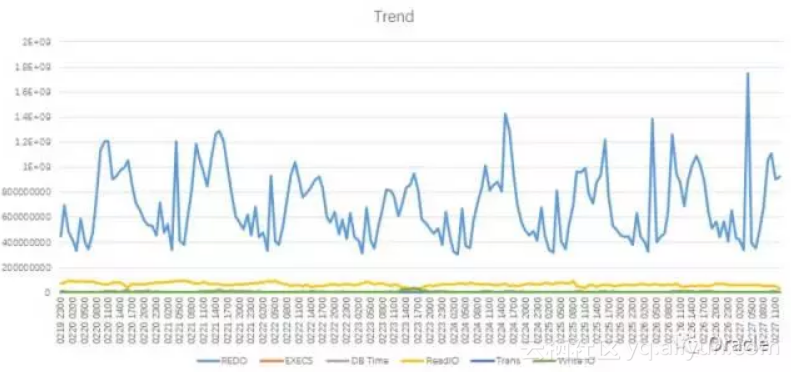
但是,这个图是有问题的:图里的REDO Size是以byte为单位的,值太大,把别的指标统统压到和0差不多,多个指标要到同一个图,还能看出各自的趋势,对于多指标关联的分析很有作用。
这时候,又有一个分析函数出来了。没错,因为我们是在对Oracle的性能数据进行分析,所以,需要大量的使用”分析函数“
分析函数: Ratio_To_Report 求当前行数据在所有同组数据内占的比例。比如说,我的结果集里有3行,分别是1,3,6. 那么1对应的那一行,占总数据(1+3+6)的10%, 出来的结果就是0.1(10%).

select * from (
select snaptime,RATIO_TO_REPORT(value) over(partition by stat_name) value,stat_name,snap_id
from (… )) PIVOT (sum(value) for stat_name in (
…))order by snap_id;
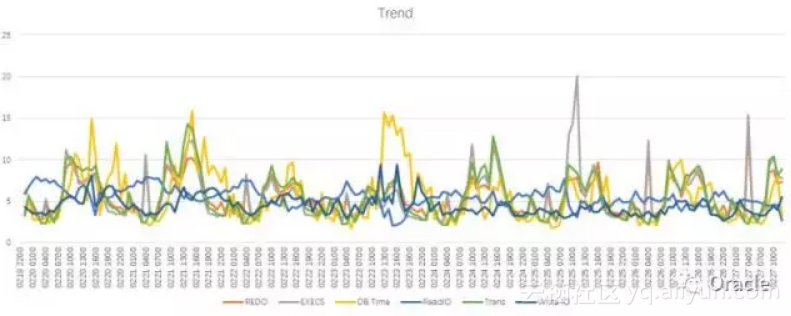
在这个图里面,大家就都平等了,也更方便的去看各个指标之间是否存在关联

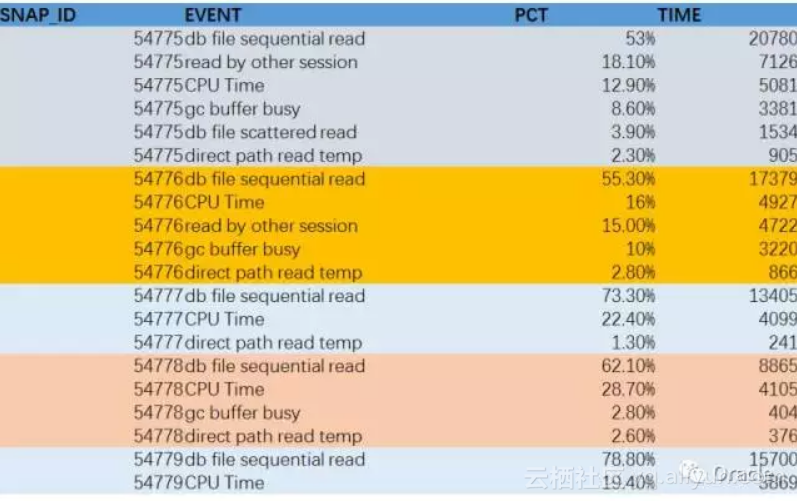
再给大家看另一个SQL, 还是ratio_to_report, 这次,我们拿到的结果,其实是AWR报告里另一个非常重要的数据:Top Timed Events
我把每个时间段的CPU时间和非空闲事件给放在一起,然后计算每个事件(含CPU)在每个时间段占的百分比,就得到 Top Timed Events,而且是连续的多个时间的数据。
在看AWR时,有几个区域是必看的。
-
第一个是LOAD PROFILE.
参考前面用来演示lag() 函数的部分:
select * from (select snap_id,STAT_NAME,
value-lag(value) over(partition by STAT_NAME
order by snap_id) value
from dba_hist_sysstat where stat_name in (
‘redo size’,‘execute count’,‘DB time’,‘physical reads‘
) ) PIVOT (sum(value) for stat_name in (
'redo size','execute count','DB time','physical reads‘
))order by snap_id;把stat_name里面的部分,加上LOAD PROFILE的其他指标,就是个完整的load profile了。
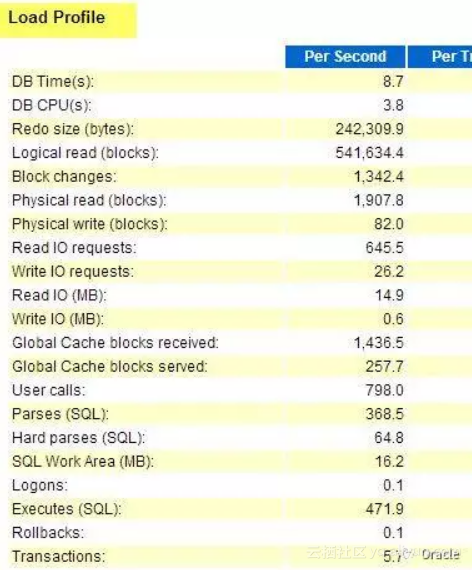
通过load profile, 大家可以对系统的总体负载有个准确的认识。
-
第二个部分,是Top timed events, 最耗时间的等待事件(包括CPU)的部分
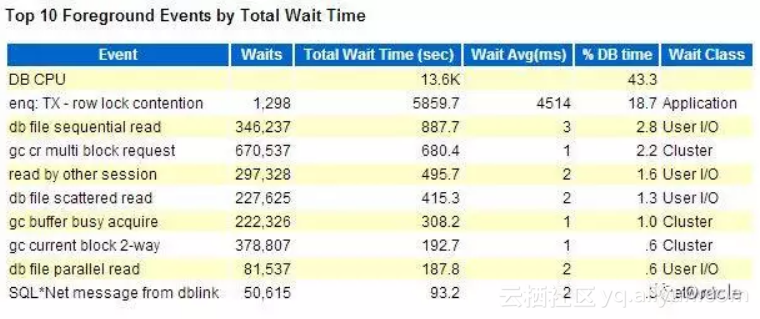
通过这个部分,大家可以了解整个系统的性能瓶颈:
select snap_id,event,pct||'%' PCT,time from (
select snap_id,event,round(time)time,
round(RATIO_TO_REPORT(TIME) over(partition by snap_id)*100,1) pct
from( select 'CPU Time' EVENT,snap_id,value/100 - LAG(value)over(partition by stat_name order by snap_id)/100 TIME
from DBA_HIST_SYSSTAT where stat_name = 'CPU used by this session'
union all select event_name,snap_id, time_waited_micro/1e6 -
LAG(time_waited_micro) over(partition by event_name order by snap_id)/1e6
from DBA_HIST_SYSTEM_EVENT where wait_class!='Idle'
)where time>0) where pct>1 order by snap_id,time desc-
通常来说,知道了系统负载,系统瓶颈,我们还需要了解的是第三个部分: Top SQL

通过Top SQL, 我们可以了解系统运行过哪些主要的语句。
但是,传统的AWR报告中的Top SQL是有缺陷的。最主要的问题,它的信息是分散的。
在对SQL进行判断时,我会结合多个指标。执行时间(elapsed Time)、CPU时间(CPU Time)、逻辑读(Buffer gets)、物理读(disk reads)、执行次数(executions)、返回行数(rows_processed),但是,传统的awr报告,这些指标分布在不同位置。看起来很不方便。比如说这个,有执行时间,执行次数,CPU时间。但缺乏逻辑读,物理读,返回行数等,有时候,还得专门去找。
所以呢,我经常访问裸数据,使用SQL, 直接从数据库里取出包含完整信息的Top SQL.
另外,根据不同的情况,我们可能关心的点也不一样。比如说,系统CPU消耗严重,我们更关心SQL order by CPU, I/O严重时,关心的则是物理读。所以我用的SQL, 可以支持同时取出按不同指标的排序的Top N SQL.
比如说, Top 10 by elapsed time, Top 10 by CPU, Top 10 by disk reads.
大家都知道,传统的order by + rownum < N 的方式只支持对其中一个指标进行排名,显然是不够的。而分析函数,又再次发挥了作用。
select sql.*, (select SQL_TEXT from dba_hist_sqltext t
where t.sql_id = sql.sql_id and rownum=1 ) SQLTEXT
from (select a.* ,
RANK() over( order by els desc) as r_els,
RANK() over( order by phy desc) as r_phy,
RANK() over( order by get desc) as r_get,
RANK() over( order by exe desc) as r_exe,
RANK() over( order by CPU desc) as r_cpu
from (
select sql_id,sum(executions_delta) exe,round(sum(elapsed_time_delta ) / 1e6, 2) els
,round(sum(cpu_time_delta) / 1e6, 2) cpu,
round(sum(iowait_delta) / 1e6, 2) iow,sum(buffer_gets_delta) get,
sum(disk_reads_delta) phy,sum(rows_processed_delta) RWO,
round(sum(elapsed_time_delta) / greatest(sum(executions_delta), 1) / 1e6,4) elsp,
round(sum(cpu_time_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) cpup,
round(sum(iowait_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) iowp,
round(sum(buffer_gets_delta) / greatest(sum(executions_delta), 1), 2) getp,
round(sum(disk_reads_delta) / greatest(sum(executions_delta), 1), 2) phyp,
round(sum(rows_processed_delta) / greatest(sum(executions_delta), 1), 2) ROWP
from dba_hist_sqlstat s
--where snap_id between ... and ...
group by sql_id ) a
)SQL where r_els <= 10 or r_phy <=10 or r_cpu<=10 order by els desc大家可以看到,这里面用到了 RANK() 函数。这个函数可以得出根据某个指标排序的排名。然后再通过最后的 r_els <= 10 or r_phy <=10 or r_cpu<=10 的过滤条件,就可以获取按照多个指标排序的Top N了。
有时候,我会把这个结果想办法做成HTML, 就变成这个效果了。

在分析SQL中,还有很重要的信息。
第一个是执行计划。
select * from table(dbms_xplan.display_awr('&SQLID'))
除了执行计划,还有一个信息不可或缺,就是绑定变量。
我碰到的SQL问题里面,有一个典型分类,就是SQL本来执行好好的,突然变差。这时候,在分析时,需要很关注的,就是历史绑定变量。Oracle在AWR裸数据中也保留了绑定变量:
DBA_HIST_SQLSTAT.BIND_DATA 这个栏位里面,保存了绑定变量
通过以下SQL, 可以获取历史绑定变量:
select snap_id,sq.sql_id,bm.position, dbms_sqltune.extract_bind(sq.bind_data,bm.position).value_string value_string
from dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id --and sq.sql_id = '&sql'出来的是行格式的,读起来不方便。用PIVOT 做一个行列转换就漂亮了。
select * from ( select snap_id, to_char(sn.begin_interval_time,'MM/DD-HH24:MI') snap_time, sq.sql_id,bm.position, dbms_sqltune.
extract_bind(bind_data,bm.position).value_string value_string from dba_hist_snapshot sn natural join dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id and sq.sql_id = '&sql'
) PIVOT (max(value_string) for position in (1,2,3,4,5,6,7,8,9,10))
order by snap_id完美的取出不同时间段的历史绑定变量值.
对于“SQL本来执行好好的,突然变差”的问题,有一个比较简洁的解决方式,就是尝试让SQL走回以前的执行计划。
Select plan_hash_value ,Sum(Elapsed_time_Delta) /greatest(Sum(Executions_Delta),1),sum(Executions_Delta) From dba_hist_sqlstat where sql_id = '&SQLID' group by plan_hash_value ;通过以上SQL, 可以快速获取某个SQL多个执行计划的执行效果。然后再想办法应用其执行计划,往往可以收到奇效。绑定执行计划的方法有多种,SPM/SQL Profile/SQL Patch等,具体我就不展开了。
不知道大家有没有碰到过这样的情况, 有时候,明明性能瓶颈在SQL,但Top SQL中DB Time(%)指标却很低,前10个加起来也不足20%.
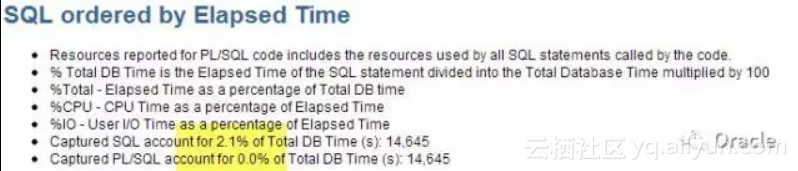
像这个AWR, Top SQL by elapsed Time才记录了2%. 也就是说,你只能看到2%的性能相关的SQL.
其中一个主要原因是由于Shared Pool大小限制以及非绑定变量问题,导致SQL可能会被漏记,这种情况下,怎么办呢?
其实,有个地方不会被漏记。就是Top Segments.通常,如果Top SQL中找不到太多信息,我们可以去看看Top Segments:
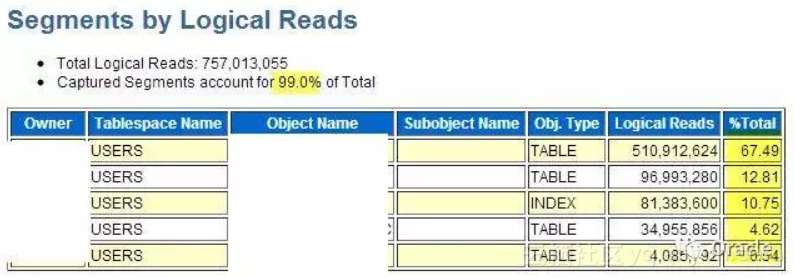
这是摘自同一个AWR的信息。 Top segments 告诉我们,对表的访问集中在前面3个,我们可以专注于这几个表的问题。
当然, 同样可以通过SQL直接访问裸数据获取相关信息:
Select begin_interval_time,seg.snap_id,PHYSICAL_READS_DELTA, object_name,subobject_name
from DBA_HIST_SEG_STAT SEG ,DBA_HIST_SEG_STAT_OBJ O , dba_hist_snapshot snap
where o.obj# = seg.obj# and o.dataobj# = seg.dataobj# and PHYSICAL_READS_DELTA > 1e5 and seg.snap_id = snap.snap_id
and begin_interval_time > sysdate - 4/24
order by PHYSICAL_READS_DELTA desc这是一个常用的AWR裸数据的列表:
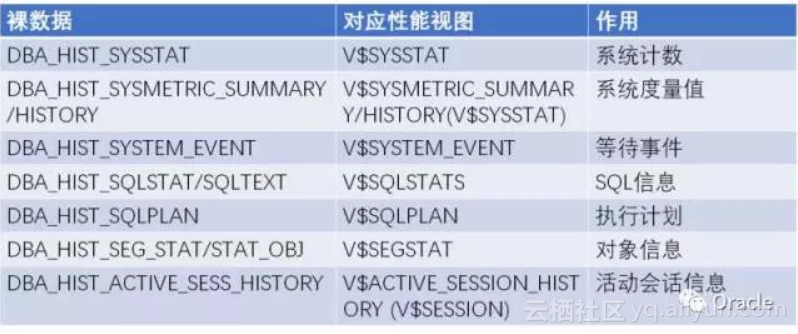
AWR裸数据如此的重要,对于关心数据库性能的DBA们,我们需要好好的保护好它们~
1. 系统保存时间,默认7天远远不足,建议改到30天以上,跨过一个月结周期
2. 需要的时候,我们可以对裸数据进行离线备份
@?/rdbms/admin/awrextr
3. 甚至,我们可以把裸数据专门找个数据库存起来,作为一个资料库使用。
@?/rdbms/admin/awrload
4. 有时候,也可以针对特定的表进行备份。比如说,我刚刚贴的这个列表
原文发布时间为:2018-05-22
本文作者:罗海雄