日志收集
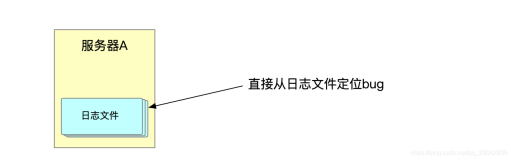
日志收集包括服务器日志收集和埋码日志收集两种。
服务器日志主要是nginx、tomcat等产生的访问和业务日志。
埋码收集主要是某些服务器无法收集,需要在前端进行收集的数据。
收集流程
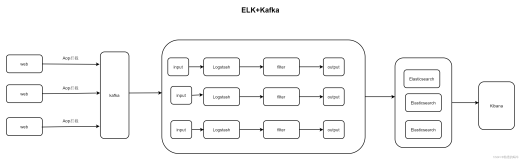
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
- Kafka消息队列,负责日志数据的接收,存储和转发;
- 日志处理应用:订阅并消费kafka队列中的日志数据;
下面是一个应用的实例图
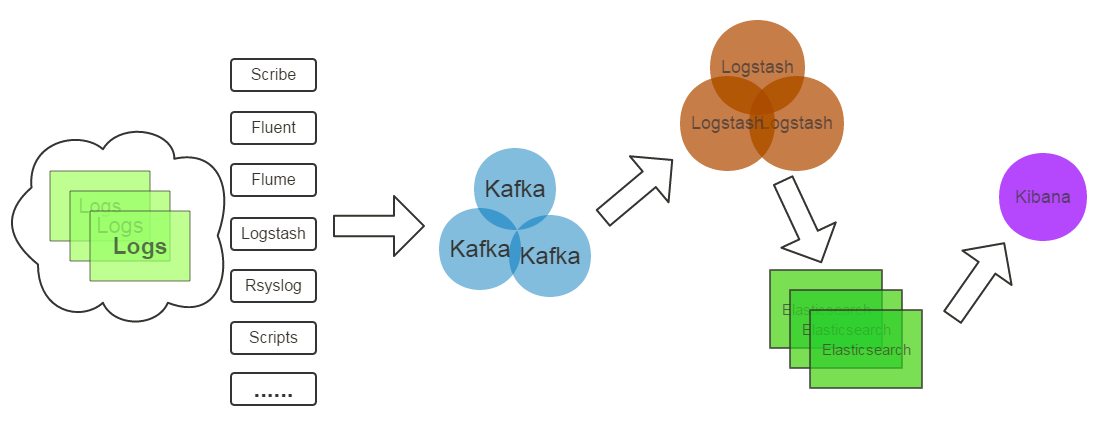
存储可以是Elasticsearch,对数据进行实时分析。
为什么kafka
Kafka 是分布式发布-订阅消息系统。它最初由 LinkedIn 公司开发,使用 Scala语言编写,之后成为 Apache 项目的一部分。Kafka 是一个分布式的,可划分的,多订阅者,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。如果对时时性要求较高的话,可以使用这种方案。
它具备以下特点:
- 同时为发布和订阅提供高吞吐量。据了解,Kafka 每秒可以生产约 25 万消息(50 MB),每秒处理 55 万消息(110 MB)。
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如 ETL,以及实时应用程序。通过将数据持久化到硬盘以及 replication 防止数据丢失。
- 分布式系统,易于向外扩展。所有的 producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。
- 消息被处理的状态是在 consumer 端维护,而不是由 server 端维护。当失败时能自动平衡。
- 支持 online 和 offline 的场景。
kafka的测试效果
下面是单机情况下的测试效果:

kafka的核心概念
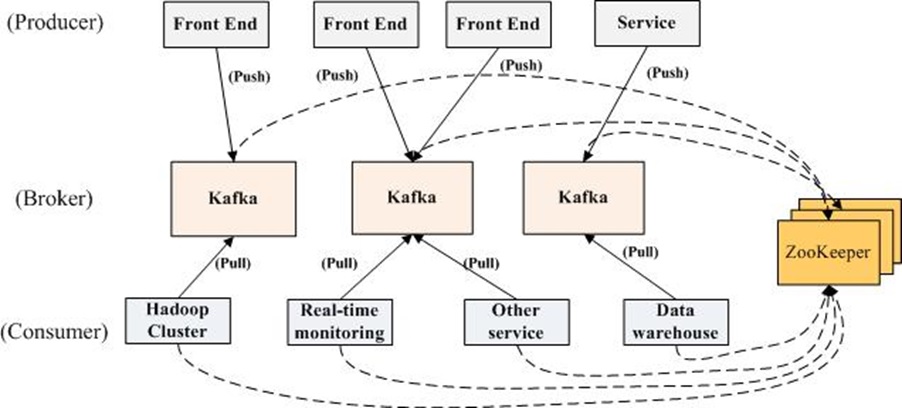
kafka中的核心概念如下:
- Producer 特指消息的生产者
- Consumer 特指消息的消费者
- Consumer Group 消费者组,可以并行消费Topic中partition的消息
- Broker:缓存代理,Kafa 集群中的一台或多台服务器统称为 broker
- Topic:特指 Kafka 处理的消息源(feeds of messages)的不同分类。
- Partition:Topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。
- Message:消息,是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
- Producers:消息和数据生产者,向 Kafka 的一个 topic 发布消息的过程叫做 producers。
- Consumers:消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers。
kafka的整体流程
kafka的整体流程:

数据通过flume在客户端进行代理,收集各种日志信息,整体模式使用生产者,消费者的模型。
producer可以根据配置设置发送的时间段。
broker中分为不同的topic,topic中又可以分为不同的partition,这个有点儿类似于数据库中的分区表,对于数据量大的情况下非常适合。
customer负责消费消息日志,如果需要时时消费,则可以使用storm或者spark streaming,如果离线消费,可以使用mapreduce。
kafka总结
kafka可以完全应用到不同的业务场景中,配合zookeeper,保证系统的高可用性。
作者:skyme
联系方式:
邮箱【cloudskyme@163.com】
QQ【270800073】
本文版权归作者和云栖社区共同所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。