从整体上来看,子表和分区表有相同的地方也有差别,因为都使用了继承的特性,所以本质上是一样的。下面看一下二者的区别:
1.父子表:
--创建父表
CREATE TABLE cities (
name text,
population float,
altitude int
);
--创建子表
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
INSERT INTO cities values('Las Vegas', 1.53, 2174); --插入父表
INSERT INTO cities values('Mariposa',3.30,1953); --插入父表
INSERT INTO capitals values('Madison',4.34,845,'WI');--插入子表
--在父表上做查询,父表和子表的数据均被取出。
SELECT name, altitude FROM cities WHERE altitude > 500;
Las Vegas 2174
Mariposa 1953
Madison 845
--查看执行计划,实际上查询从扫描了两个表的数据,组合出想要的结果
explain analyze SELECT name,altitude FROM cities WHERE altitude > 500;
Append (cost=0.00..24.54 rows=361 width=36) (actual time=0.008..0.012 rows=3 loops=1)
-> Seq Scan on cities (cost=0.00..2.41 rows=38 width=36) (actual time=0.007..0.008 rows=2 loops=1)
Filter: (altitude > 500)
-> Seq Scan on capitals (cost=0.00..22.12 rows=323 width=36) (actual time=0.001..0.001 rows=1 loops=1)
Filter: (altitude > 500)
Planning time: 0.096 ms
Execution time: 0.044 ms
--在子表上做查询,只能查出子表上的数据。
SELECT name, altitude FROM capitals WHERE altitude > 500;
--如果只想从父表中取数据,则需要在SQL中加入ONLY关键字,如:
SELECT name,altitude FROM ONLY cities WHERE altitude > 500;
从这个例子看一看出,父子表使用了继承的特性,子表可以增加字断,另外子表可以继承于多个父表。但是仍然有个疑问,有什么卵用呢??
2.分区表:
分区表也是使用继承的特性,在逻辑上把一个大表分成几块数据,分区的字断和主表字断一致,不会再另行增加字断,另外可以人为定义约束,来约束每个表上的数据不重复。
--创建主表示例:
CREATE TABLE measurement (
city_id int NOT NULL,
logdate date NOT NULL,
peaktemp int
);
--创建几个子表,继承父表所有字断:
CREATE TABLE measurement_yy04mm02 (
CHECK ( logdate >= DATE '2004-02-01' AND logdate < DATE '2004-03-01')
) INHERITS (measurement);
CREATE TABLE measurement_yy04mm03 (
CHECK (logdate >= DATE '2004-03-01' AND logdate < DATE '2004-04-01')
) INHERITS (measurement);
...
CREATE TABLE measurement_yy05mm11 (
CHECK (logdate >= DATE '2005-11-01' AND logdate < DATE '2005-12-01')
) INHERITS (measurement);
CREATE TABLE measurement_yy05mm12 (
CHECK (logdate >= DATE '2005-12-01' AND logdate < DATE '2006-01-01')
) INHERITS (measurement);
CREATE TABLE measurement_yy06mm01 (
CHECK (logdate >= DATE '2006-01-01' AND logdate < DATE '2006-02-01')
) INHERITS (measurement);
从这个例子看出,分区表完全继承主表字断,并且不另外增加字断,每个分区表上定义好约束,保证数据不要发生重叠。分区表在生产上还是很有用的,可以提高查询效率。
PostgreSQL父子表和分区表对比
2018-05-11
8082
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
本文涉及的产品
简介:
相关实践学习
阿里云数据库产品家族及特性
阿里云智能数据库产品团队一直致力于不断健全产品体系,提升产品性能,打磨产品功能,从而帮助客户实现更加极致的弹性能力、具备更强的扩展能力、并利用云设施进一步降低企业成本。以云原生+分布式为核心技术抓手,打造以自研的在线事务型(OLTP)数据库Polar DB和在线分析型(OLAP)数据库Analytic DB为代表的新一代企业级云原生数据库产品体系, 结合NoSQL数据库、数据库生态工具、云原生智能化数据库管控平台,为阿里巴巴经济体以及各个行业的企业客户和开发者提供从公共云到混合云再到私有云的完整解决方案,提供基于云基础设施进行数据从处理、到存储、再到计算与分析的一体化解决方案。本节课带你了解阿里云数据库产品家族及特性。

目录
相关文章
|
6月前
|
SQL
监控
关系型数据库
|
9月前
|
存储
SQL
运维
PolarDB MySQL大表实践-分区表篇
背景:分区表到底是什么?分区作为传统企业级数据库的特性,早已经在很多大数据和数仓场景中得到广泛应用。基于维基百科的解释,分区是将逻辑数据库或其组成元素如表、表空间等划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性的原因,或者是为了负载平衡。它在分布式数据库管理系统中很流行,其中每个分区可能分布在多个节点上,节点上的用户在分区上执行本地事务。这提高了具有涉及某些数据视图的常规事务的站
334
0
0

|
存储
SQL
监控

|
存储
SQL
Cloud Native
直播预告 | PolarDB-X 动手实践系列—— PolarDB-X 的 TTL分区表功能介绍及原理解析
在某些业务场景下,数据库的数据会增量很快,并且数据热度随着时间推移会有明显的降低。如果数据一直存储在 PolarDB-X 中,既会占用存储空间,也会降低正常业务查询的效率。所以,需要有一个机制,能让冷数据定期地转移到其他成本更低的存储,以及让冷数据在 PolarDB-X 中自动删除,这就是TTL分区表。
306
0
0

|
存储
SQL
JSON
大分区表高并发性能提升100倍?阿里云 RDS PostgreSQL 12 特性解读
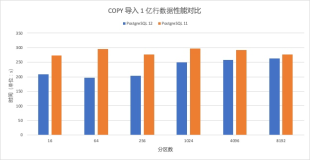
世界上几乎最强大的开源数据库系统 PostgreSQL,于 2019 年 10 月 3 日发布了 12 版本,该版本已经在阿里云正式发布。PostgreSQL 12 在功能和性能上都有很大提升,如大分区表高并发性能提升百倍,B-tree 索引空间和性能优化,实现 SQL 2016 标准的 JSON 特性,支持多列 MCV(Most-Common-Value)统计,内联 CTE(Common table expressions)以及可插拔的表存储访问接口等。本文对部分特性进行解读。
1977
0
0
|
SQL
弹性计算
算法
PostgreSQL 普通表在线转换为分区表 - online exchange to partition table
标签
PostgreSQL , 分区表 , 在线转换
背景
非分区表,如何在线(不影响业务)转换为分区表?
方法1,pg_pathman分区插件
《PostgreSQL 9.5+ 高效分区表实现 - pg_pathman》
使用非堵塞式的迁移接口
partition_table_concurrently(
relation REGCLASS,
2501
0
0
|
存储
NoSQL
关系型数据库
阿里云rds并发性能解读-大分区表高并发性能提升100倍?
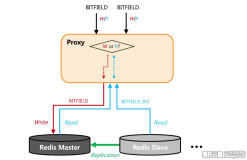
Redis读写分离实例的原理是:key统一写入到master,然后通过主从复制同步到slave,用户的请求通过proxy做判断,如果是写请求,转发到master;如果是读请求,分散转发到slave,这种架构适合读请求数量远大于写请求数量的业务
2455
0
0
|
SQL
算法
关系型数据库
PostgreSQL 普通表在线转换为分区表 - online exchange to partition table
PostgreSQL 普通表在线转换为分区表 - online exchange to partition table
2460
0
1
|
SQL
弹性计算
Oracle
PostgreSQL native partition 分区表性能优化之 - 动态SQL+服务端绑定变量
标签
PostgreSQL , 分区表 , native partition , 性能 , pg_pathman , plpgsql , 动态SQL , 服务端绑定变量 , prepare , execute
背景
目前PG的native partition分区性能不佳,一种解决方法是使用pg_pathman插件,另一种方法是业务上直接插分区,还有一种方法是使用UDF函数接口(函数内部使
1237
0
0
|
弹性计算
关系型数据库
测试技术
PostgreSQL 分区表如何支持多列唯一约束 - 枚举、hash哈希 分区, 多列唯一, insert into on conflict, update, upsert, merge insert
标签
PostgreSQL , 分区表 , native partition , 唯一 , 非分区键唯一 , 组合唯一 , insert into on conflict , upsert , merge insert
背景
PG 11开始支持HASH分区,10的分区如果要支持hash分区,可以通过枚举绕道实现。
《PostgreSQL 9.x, 10, 11 hash分区表 用法举例
2909
0
0
热门文章
最新文章
1
成都晨云信息技术完成阿里云PolarDB数据库产品生态集成认证
2
课程导航 | 学姐领航,共学PolarDB-X:从入门到精通实操课
3
电子好书发您分享《PolarDB分布式版架构介绍》
4
数据之势丨AI时代,云原生数据库的最新发展趋势与进展
5
【PolarDB-X从入门到精通】 第四讲:PolarDB分布式版安装部署(源码编译部署)
6
【公测】PolarDB PostgreSQL版Serverless功能免费使用!
7
「合肥 * 讯飞」4 月 19 日 PolarDB 开源数据库沙龙,报名中!
8
postgresql安装
9
ECS互通问题之与polarDB内网互通如何解决
10
PostgreSQL Json应用场景介绍和Shared Detoast优化
1
玩转阿里云RDS PostgreSQL数据库通过pg_jieba插件进行分词
439
2
使用ECS和RDS搭建个人博客
1147
3
PolarDB | PostgreSQL 高并发队列处理业务的数据库性能优化实践
597
4
【ECS生长万物之开源】如何一键本地部署PolarDB for PostgreSQL
831
5
NineData已支持「最受欢迎数据库」PostgreSQL
311
6
postgresql snapshot 快照源码解读
349
7
如何使用AnalyticDB PostgreSQL 版实现“一站式全文检索”业务
32157
8
将 PostgreSQL 迁移到 MySQL 数据库
1065
9
flink postgresql cdc实时同步(含pg安装配置等)
1768
10
PostgreSQL内存上下文[翻译]
161