第一章 GPU虚拟化发展史
GPU的虚拟化发展历程事实上与公有云市场和云计算应用场景的普及息息相关。如果在10年前谈起云计算,大部分人的反应是“不知所云”。但是随着云计算场景的普及,概念的深入人心,慢慢地大家都对云计算有一个较清晰的概念和实例化的理解。自然,随着应用场景从单一依赖CPU的计算单元的应用扩展到多种体系架构,异构计算场景的应用上来后,对GPU,FPGA,TPU等专业计算芯片也提出了虚拟化和上云的强烈要求。尤其是最近几年机器学习、深度学习等领域的快速发展,催生了异构计算场景搬迁上云的高潮。
那么这个异构计算应用场景的市场规模有多大呢?异构计算作为机器学习人工智能的计算载体,先来看看人工智能前景如何?(引用出处:https://bg.qianzhan.com/report/detail/459/180116-3c060b52.html)
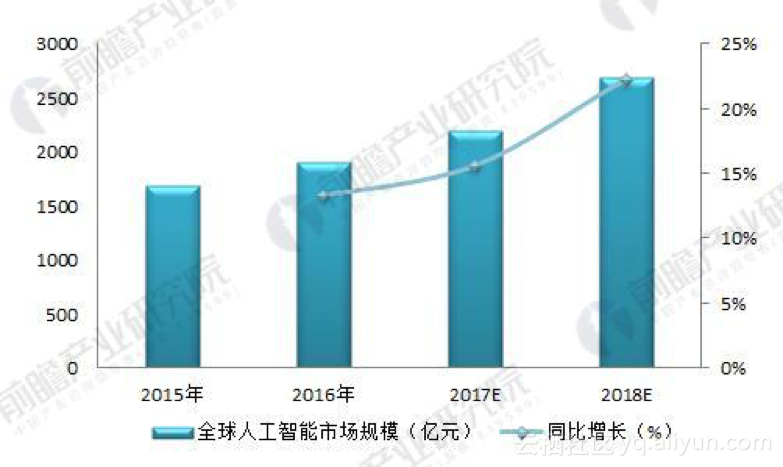
图一:2015-2018年全球人工智能市场规模及预测(单位:亿元,%)
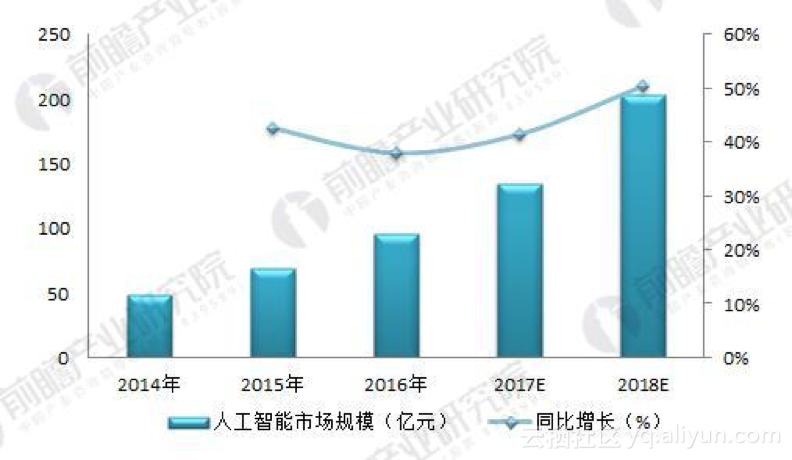
图二: 2014-2018年中国人工智能产业市场规模及增速(单位:亿元,%)
所以我们不难理解,为什么各大云计算厂商无论大小,都会极力研发异构计算产品,争抢市场的主导地位。
由于GPU是异构计算的主力军,让我们来回顾一下GPU虚拟化的发展历史,并对各个GPU厂商做一个横向比较,大家就不难看出来,哪些厂商处于领导地位,哪些是酱油党 :)
2008年:序言
VMware的GPU全虚拟化VSGA技术是第一次对GPU共享虚拟化的尝试,于2008年底在VMware商业化的Workstation 6.5和Fusion 2.0版本中首度问世,后续又在面向数据中心的产品vSphere中有集成。但这是一个VMware专有的闭源解决方案,在开源社区和VMware之外的产品中没有见到大规模应用,不是本篇关注的重点。
2012年:开始
随着kernel VFIO模块的引入和直通设备的慢慢普及,GPU的虚拟化之路得以开启。而开始大规模运用,则大体是伴随着VFIO模块的成功落地。事实上,在2012年左右,GPU直通技术一直是VFIO模块的一个重要应用场景。
2013年:第一个产品与群雄逐鹿
Nvidia 在2013 发布了GRID K1的产品,则标志着GPU虚拟化的成熟并逐渐开启了异构计算虚拟化的快速发展历程。
而事实上在2013同年,Intel OTC 针对HSW的GVT-d 和GVT-g的GPU虚拟化方案的也已经开发了一年有余。当初硬件基于SNB/HSW,而原型代码是基于Xen Hypervisor。(题外话:回头来看,会发现当初如日中天的Xen,竟然在几年后被后起之秀KVM逐渐取代。而当今公有云市场已鲜有Xen的身影了,替Citrix心疼几秒)。
Intel对GPU行业发展保持着敏锐的技术洞察力,早在2011年便已经开始了GPU虚拟化的提案,然而由于没有引起足够的重视,直到三年后的2014年,才有基于GVT-g的XenClient产品问世。
同年: VFIO 模块的社区维护者在KVM Forum上也正式发布了VGA的assignment。(详见:https://www.linux-kvm.org/images/e/ed/Kvm-forum-2013-VFIO-VGA.pdf)
同年初: AMD 也已经开始基于SRIOV的GPU虚拟化方案(Tonga架构),并开始研发SRIOV PF的GIM驱动和vGPU调度系统。由此推测SRIOV的硬件实现应该提前半年左右已经完成。直到两年后,AMD终于迎来了首款GPU SRIOV的产品:FirePro S7150 (2016年初发布)。
Nvidia作为GPU行业的龙头老大,基本上在GPU虚拟化的研发和产品化是领先了各位对手1-2年以上。而作为竞争对手的AMD在之后奋起直追。而Intel 基本上在那个时期还属于陪跑者。
2014年:vGPU 分片虚拟化诞生
一年后,也就是2014年,随着一篇Usenix ATC的论文的发表:“A Full GPU Virtualization Solution with Mediated Pass-Through” 默默无闻的GPU虚拟化的一个新技术正式进入了大家的视眼:GPU分片虚拟化(中文暂且这么叫吧,因为mediated passh-through的叫法根本就不能让人明白这个到底是什么)。
该论文由Intel OTC的两位Principal Engineer发表,也代表了Intel在GPU虚拟化领域的技术积累(产品化一直不见起色,说起来都是泪)。
应该说Nvidia作为行业龙头对分片虚拟化在社区的推动起到至关重要的角色,事实上VFIO的mdev框架是由Nvidia为了GRID vGPU 产品线而引入。mdev的概念由Nvidia率先提出的,并合并到了Linux 内核4.10。人家玩闭源生态系统也开始拥抱开源。
而AMD 2014 则没有消息,应该是继续研发全球首款基于SRIOV的GPU方案。
2015年:分化
Intel 与Citrix的合作,先后发布了基于GVT-d和分片虚拟化的GVT-g的XenClient 和 XenServer的产品。这些产品代表着当时Xen社区GPU虚拟化业界的标杆。为什么是Xen社区呢? 因为GVT-g当时还没有发布KVM 版本。
Intel 也开始在各大内外会议推送GVT-g的技术,当然是希望自己技术可以产品化并有一个好的市场前景。比如在当年“英特尔开发者大会”(IDF)上率先发布了基于GVT-g的多媒体视频处理云端方案。听的人很多一百多号吧,并且感兴趣的也不少。作为一个利用免费GPU来做音视频处理,比单独用E5 Server要划算的多。但是遗憾的是最终没有任何产品落地。究其原因还是内在Intel GPU的定位问题。后续会讲到Intel GVT-g 方案的致命伤和痛点。
而AMD继续研发全球首款SRIOV GPU。
当其他人都在玩技术的时候,Nvidia已经开始了产业布局。同年发布了AWS上和VMware合作的基于GRID的各种方案,比如非常炫酷的Game Streaming。
其实GRID 是大概念。代表了Nvidia的GPU虚拟化的一大摞产品。而其中的GRID vGPU便是基于mdev的分片虚拟化方案。
2016,2017年:回报
2016年AMD带来了全球首款GPU的SRIOV显卡FirePro S7150x2。而这款针对图形渲染应用的产品也成为了之后各大公有云厂商的必推业务。图形渲染虚拟化高性价比只此一款。
Intel继续在各大论坛极力宣传Intel GVT-g技术。并在技术上第一次领先行业龙头Nvidia率先实现了vGPU的热迁移技术,可以说Intel OTC的虚拟化部门在自己力所能及的情况下把GVT-g做到了极致,然而在产品化的道路上却越走越艰难。
Nvidia此时凭借着AI的风口一路狂奔,日益完善GRID技术和分片虚拟化,把对手远远地抛在了后面。此时Nvidia也开始在开源社区抛头露面。并在2016年的KVM Forum的第二天,Nvidia架构师Neo隆重介绍了GRID vGPU技术。而恰巧本人作为GVT-g技术的代表在同一会场做GPU Live Migration的主题介绍。
大家感受一下当时的场景:GRID vGPU听众与GVT-g的听众对比:


不得不说,早年Intel作为核显GPU的代表与Nvidia作为独立显卡的代表在GPU研发上有深度合作。而随后与AMD的合作开发CPU+GPU的芯片。以及最近的Intel与AMD合作对抗Nvidia在GPU领域的挤压。
以上三位既是对手又是朋友。
2018年:新领域
Nvidia继续保持着行业第一的身份把持了绝大部分市场份额。谁让人家有远见早早布局早早收割。
AMD 也有后续产品的发布。比如针对老对手Nvidia的对标Deep Learning的MI25的发布等。
随着GPU虚拟化应用的普及,GPU虚拟化的应用场景不再限于云计算市场。各种新兴行业也开始应用GPU虚拟化技术。最直接的便是车载娱乐系统,简称IVI(In-vehicle Information system )。于是三位老朋友又是老对手,都开始在IVI和自动驾驶领域开始竞争。而这也为Intel GVT-g的技术落地带来了转机。于是Intel率先发布了基于物联网的虚拟化方案(ACRN),并夹带着GVT-g的分片虚拟化技术浩浩荡荡地再次出发。

