从智能客服到机器翻译,从文本摘要生成到用户评论分析,从文本安全风控到商品描述建模,无不用到自然语言技术,作为人工智能领域的一个重要分支,如何让机器更懂得人类的语言,尤其是汉字这种强表意文字,是一个具有极大挑战的事情。
词向量,是一种利用无监督学习方式(不需要人工数据标注),将词语映射到语义向量空间的技术。举个例子:在过去,计算机使用下标表示词语,比如“猫: 2123”,“狗: 142”,由于下标不一样,机器就只会认为是不同的词语,却不能像人一样感知词语间的语义关系。而词向量技术恰好弥补了这一点,使机器可以理解潜在的语义信息。实际上,现在很多自然语言处理的算法都是将其作为输入,进而建立端到端的算法模型。因此,设计出高质量的词向量生成算法是一个值得探讨的问题。
中文经过几千年的发展和演变,是一种强表意文字,对于我们而言,即使某个字不认识,都或许可以猜到其含义,机器却很难理解这些。比如,“蘒”这个字我们很可能不认识,但里面有“艹”字头,和“禾”木旁,那它也许就是长得像该字右下角部分的某种植物吧。通过词向量的方式,我们希望让机器能够理解汉字一笔一画之间的奥秘。然而,传统的算法并不能很好的利用中文语言学上的特性,这篇文章里,我们将提出一种利用笔画信息来提高中文词向量的方法。
词向量算法是自然语言处理领域的基础算法,在序列标注、问答系统和机器翻译等诸多任务中都发挥了重要作用。词向量算法最早由谷歌在2013年提出的word2vec,在接下来的几年里,经历不断的改进,但大多是只适用于拉丁字符构成的单词(比如英文),结合中文语言特性的词向量研究相对较少。
相关工作:
早在1954年,语言学家Harris提出“Distributional Hypothesis [1](分布式假设)”:语义相似的单词往往会出现在相似的上下文中。这一假设奠定了后续各种词向量的语言学基础,即用数学模型去刻画单词和其上下文的语义相似度。Bengio et al., 2003 [2] 提出了NNLM(基于神经网络的语言模型),由于每次softmax的计算量很大(分母项的计算时间复杂度O(|V|),V是全词表),相继出现了很多快速近似计算策略。
为了解决上述问题,谷歌提出了word2vec [3,4] 算法,其中包含了两种策略,一种叫做Negative Sampling(负采样),另一种是hierarchical softmax(层次softmax)。Negative Sampling的核心思想:每次softmax计算所有单词太慢,那就随机的选几个算一算好了,当然,训练语料中出现次数越多的单词,也就越容易被选中;而Hierarchical Softmax,简单来说,就是建一棵树状的结构,每次自上而下的从根计算到叶子节点,那么就只有对数时间复杂度了!如何构建这棵树可以使得让树的高度尽量小呢?哈夫曼树。
词向量模型的核心是构造单词与其上下文的相似度函数,word2vec工具包里面有两种实现方式,分别是skipgram和cbow。
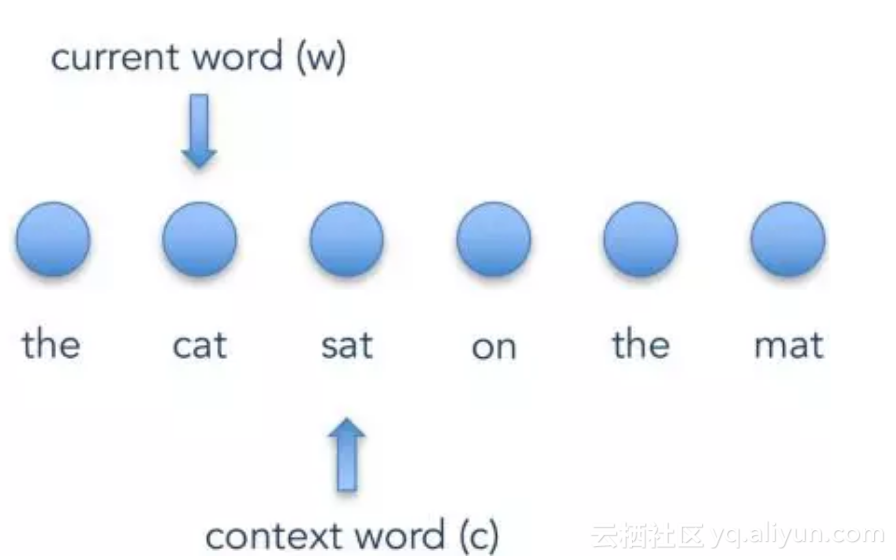
图 1 SGNS算法示意图
假设当前单词w是“cat”,而上下文单词c是“sat”,算法的目标是给定w最大化c出现概率(skipgram)。在这个算法中,每个单词都被当作一个整体,利用外部的上下文结构信息去学习得到词向量。
那么是否可以充分结合单词内部结构的(亚词)信息,将其拆分成更细粒度的结构去增强词向量?英文中每个单词所包含的character(字母)较多,每个字母并没有实际的语义表达能力。对于中文词语而言,中文词语可以拆解成character(汉字)。
Chen et al., 2015 [5] 提出了CWE模型,思路是把一个中文词语拆分成若干汉字,然后把原词语的向量表示和其中的每一个汉字的向量表示做平均,然后作为新的词语向量。
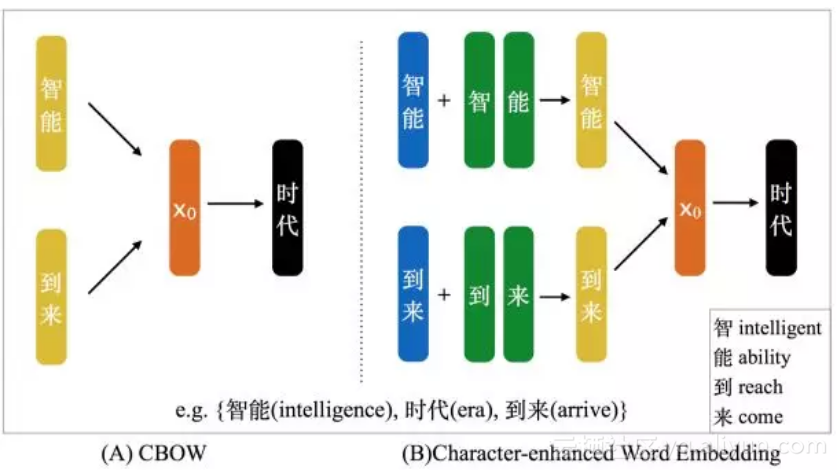
图 2 CWE模型示例
在该算法中,“智能”是一个上下文词语,先拆解成两个汉字“智”和“能”,然后计算出新的词语向量表示;同理,上下文词语“到来”也得到重新计算。CWE保持当前词语不拆分,这里“时代”保持不变。
不难想到,将汉字拆分成偏旁或许是一种不错的方式,Sun et al., 2014 [6]和Li et al., 2015 [7] 做过相关的研究。然而偏旁只是汉字的一部分,Yu et al., 2017 [8] 提出了更加细化的拆分,根据人工总结的“字件”,将汉字拆成一个一个的小模块,把词、汉字和字件一起进行联合学习:
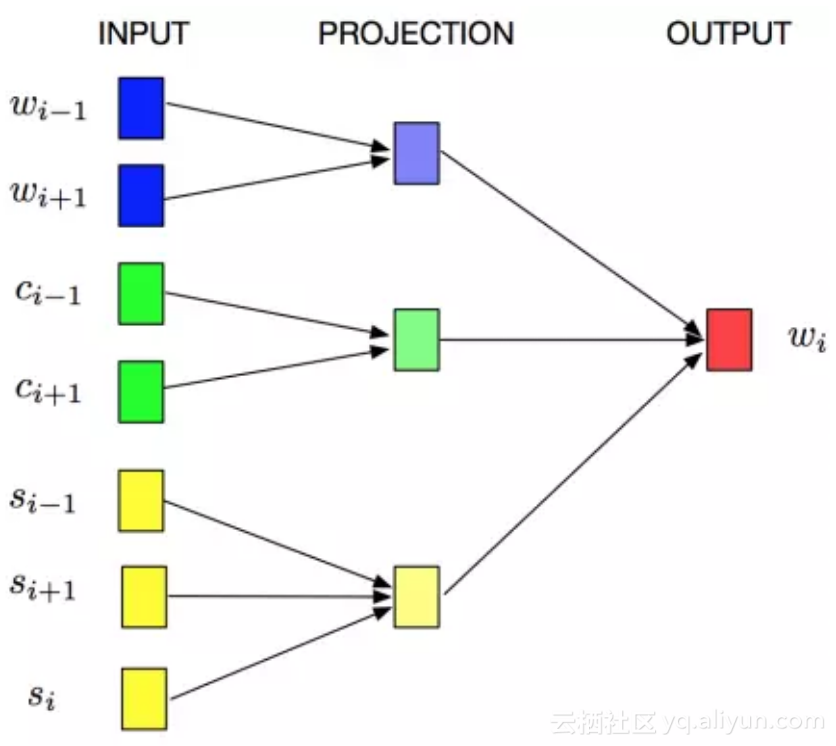
图 3 JWE算法示意图
其中,w , c和s分别表示词语、汉字和字件模块。字件粒度的拆分也取得了超过仅仅利用偏旁信息的方法。
此外,Su and Lee, 2017 [9] 提出了GWE模型,尝试从汉字的图片中利用卷积自动编码器来提取特征:
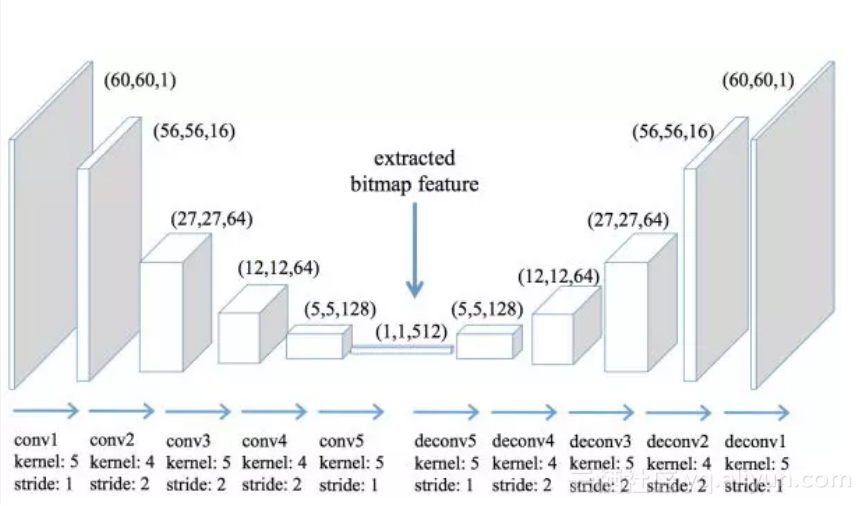
图 4 GWE卷积神经网络提取特征示意图
从汉字图片提取出特征之后,再结合上下文结构信息学习中文词向量。很遗憾的是,根据其原文的描述,这种方式得到的特征基本没有提升,不过这确实是非常有意思的一次试探。
问题与挑战:
自然语言处理的顶级会议ACL 2017,共提出了未来的四大研究方向,如何更好的利用“亚词”信息就是其中的一个。在中文词向量场景下,仅将中文词语拆解到汉字粒度,会一定程度上提高中文词向量的质量,是否存在汉字粒度仍不能刻画的情况?

图 5 汉字粒度拆解
可以看出,“木材”和“森林”是两个语义很相关的词语,但是当我们拆解到汉字粒度的时候,“木”和“材”这两个字对比“森”和“材”没有一个是相同的(一般会用一个下标去存储一个词语或汉字),因此对于这个例子而言,汉字粒度拆解是不够的。我们所希望得到的是:

图 6 更细粒度的亚词信息拆解
“木”和“材”可以分别拆解出“木”和“木”(来源于“材”的左半边)结构,而“森”和“林”分别拆解得到多个“木”的相同结构。此外,可以进一步将汉字拆解成偏旁、字件,对于以上例子可以有效提取出语义结构信息,不过我们也分析到:

图 7 偏旁和字件结构拆分举例
可以看出,“智”的偏旁恰好是“日”,而“日”不能表达出“智”的语义信息。实际上,偏旁的设计是为了方便在字典中查询汉字,因此结构简单、出现频率高变成了首要原则,并不一定恰好能够表达出该汉字的语义信息。此外,将“智”拆分到字件粒度,将会得到“失”,“口”和“日”三个,很不巧的是,这三个字件也均不能表达其汉字语义。我们需要设计出一种新的方法,来重新定义出词语(或汉字)具有语义的结构:
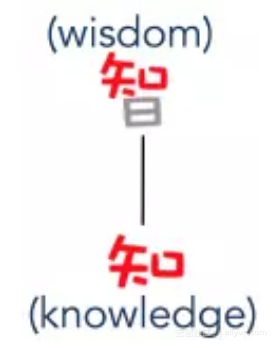
图 8 更细粒度的亚词信息拆解举例
这里,“知”是可以表达出“智”语义的模块,如何得到这样的亚词结构,并结合句子上下文设计模型的优化目标,生成出更好的中文词向量,将是后文要探索的内容。
cw2vec模型:
单个英文字符(character)是不具备语义的,而中文汉字往往具有很强的语义信息。不同于前人的工作,我们提出了“n元笔画”的概念。所谓“n元笔画”,即就是中文词语(或汉字)连续的n个笔画构成的语义结构。

图 9 n元笔画生成的例子
如上图,n元笔画的生成共有四个步骤。比如说,“大人”这个词语,可以拆开为两个汉字“大”和“人”,然后将这两个汉字拆分成笔画,再将笔画映射到数字编号,进而利用窗口滑动产生n元笔画。其中,n是一个范围,在上述例子中,我们将n取值为3, 4和5.
在论文中我们提出了一种基于n元笔画的新型的损失函数
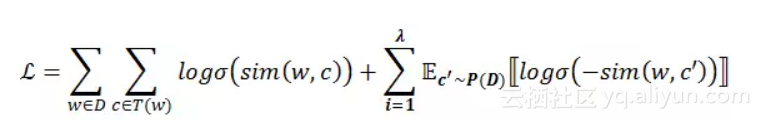

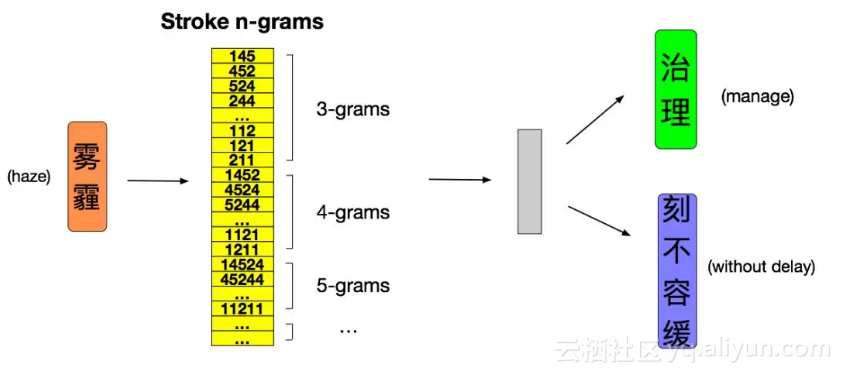
图 10 算法过程的举例
如上图所示,对于“治理 雾霾 刻不容缓”这句话,假设此刻当前词语恰好是“雾霾”,上下文词语是“治理”和“刻不容缓”。首先我们将当前词语“雾霾”拆解成n元笔画并映射成数字编码,然后划窗得到所有的n元笔画,根据我们设计的损失函数,计算每一个n元笔画和上下文词语的相似度,进而根据损失函数求梯度并对上下文词向量和n元笔画向量进行更新。
为了验证我们提出的cw2vec算法的效果,我们在公开数据集上,与业界最优的几个词向量算法做了对比:
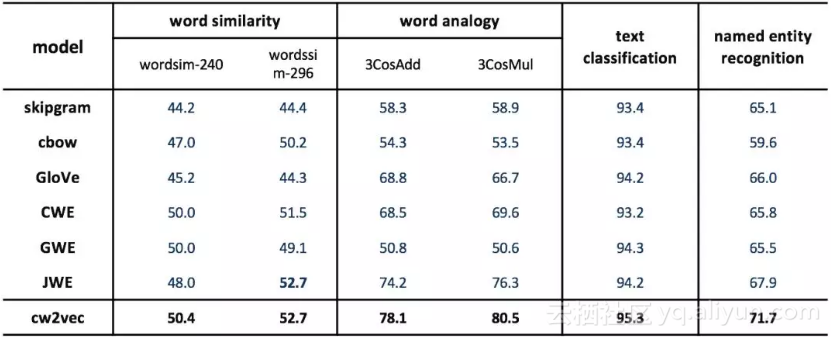
图 11 实验结果
上图中包括2013年谷歌提出的word2vec [2,3] 的两个模型skipgram和cbow,2014年斯坦福提出的GloVe算法 [10],2015年清华大学提出的基于汉字的CWE模型 [5],以及2017年最新发表的基于像素和字件的中文词向量算法 [8,9],可以看出cw2vec在word similarity,word analogy,以及文本分类和命名实体识别的任务中均取得了一致性的提升。同时,我们也展示了不同词向量维度下的实验效果:
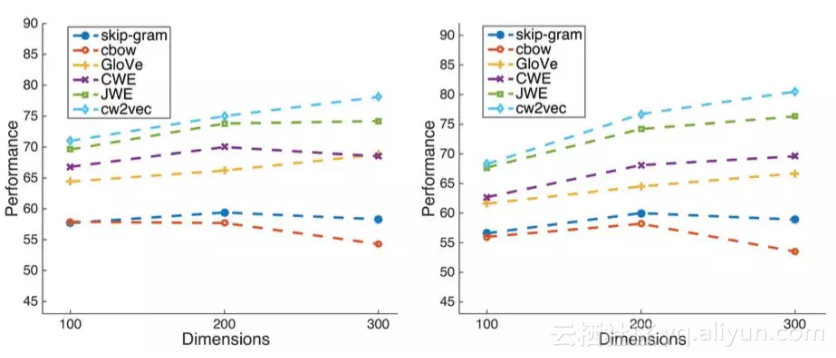
图 12 不同词向量维度下的实验结果
上图为不同维度下在word analogy测试集上的实验结果,左侧为3cosadd,右侧为3cosmul的测试方法。可以看出我们的算法在不同维度的设置下均取得了不错的效果。此外,我们也在小规模语料上进行了测试:
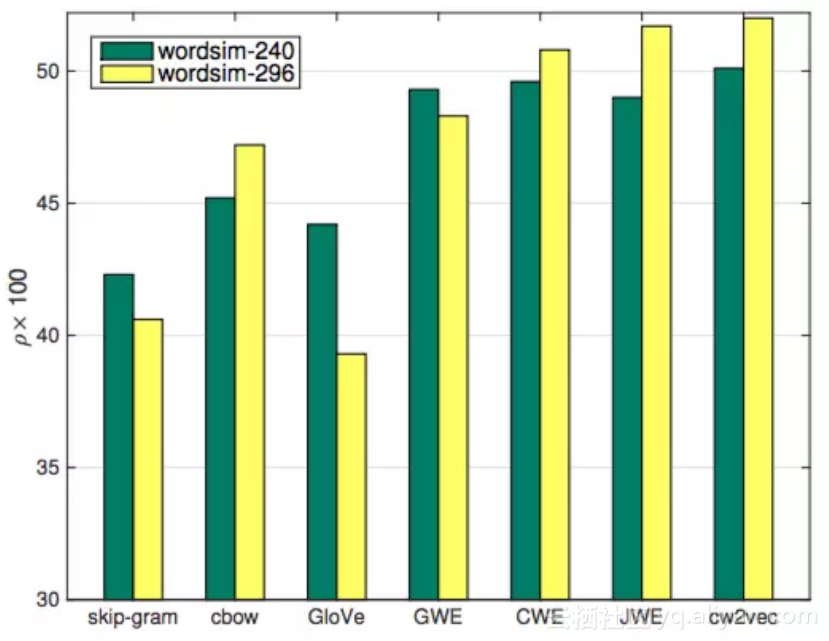
图 13 小训练数据下的实验结果
上图是仅选取20%中文维基百科训练语料,在word similarity下测试的结果,skipgram, cbow和GloVe算法由于没有利用中文的特性信息进行加强,所以在小语料上表现较差,而其余四个算法取得了不错的效果,其中我们的算法在两个数据集上均取得的了最优效果。
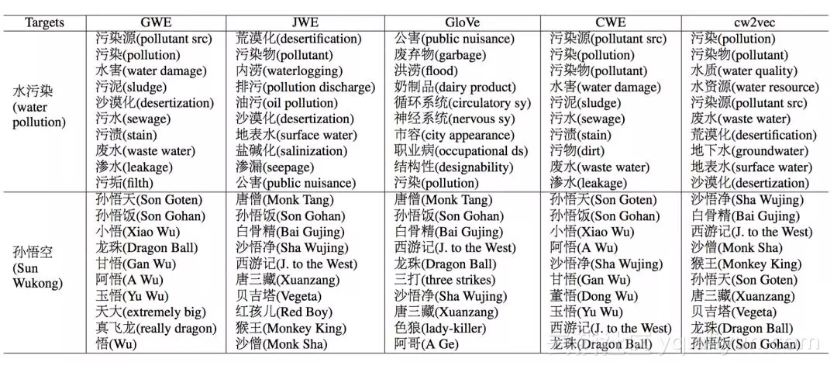
图 14 案例分析结果
为了更好的探究不同算法的实际效果,我们专门选取了两个词语做案例分析。第一个是环境相关的“水污染”,然后根据词向量利用向量夹角余弦找到与其语义最接近的词语。GWE找到了一些和“污”字相关的词语,比如“污泥”,“污渍”和“污垢”,而JWE则更加强调后两个字“污染”GloVe找到了一些奇怪的相近词语,比如“循环系统”,“神经系统”。CWE找到的相近词语均包含“水”和“污”这两个字,我们猜测是由于其利用汉字信息直接进行词向量加强的原因。此外,只有cw2vec找到了“水质”这个相关词语,我们认为是由于n元笔画和上下文信息对词向量共同作用的结果。第二个例子,我们特别选择了“孙悟空”这个词语,该角色出现在中国的名著《西游记》和知名日本动漫《七龙珠》中,cw2vec找到的均为相关的角色或著作名称。
作为一项基础研究成果,cw2vec在阿里的诸多场景上也有落地。在智能客服、文本风控和推荐等实际场景中均发挥了作用。此外,不单单是中文词向量,对于日文、韩文等其他语言我们也进行类似的尝试,相关的发明技术专利已经申请近二十项。
我们希望能够在基础研究上追赶学术界、有所建树,更重要的是,在具体的实际场景之中,能够把人工智能技术真正的赋能到产品里,为用户提供更好的服务。