
为了让文章不那么枯燥,我构建了一个精灵图鉴数据集(Pokedex)这都是一些受欢迎的精灵图。我们在已经准备好的图像数据集上,使用Keras库训练一个卷积神经网络(CNN)。
深度学习数据集

上图是来自我们的精灵图鉴深度学习数据集中的合成图样本。我的目标是使用Keras库和深度学习训练一个CNN,对Pokedex数据集中的图像进行识别和分类。Pokedex数据集包括:Bulbasaur (234 images);Charmander (238 images);Squirtle (223 images);Pikachu (234 images);Mewtwo (239 images)
训练图像包括以下组合:电视或电影的静态帧;交易卡;行动人物;玩具和小玩意儿;图纸和粉丝的艺术效果图。
在这种多样化的训练图像的情况下,实验结果证明,CNN模型的分类准确度高达97%!
CNN和Keras库的项目结构
该项目分为几个部分,目录结构如下:
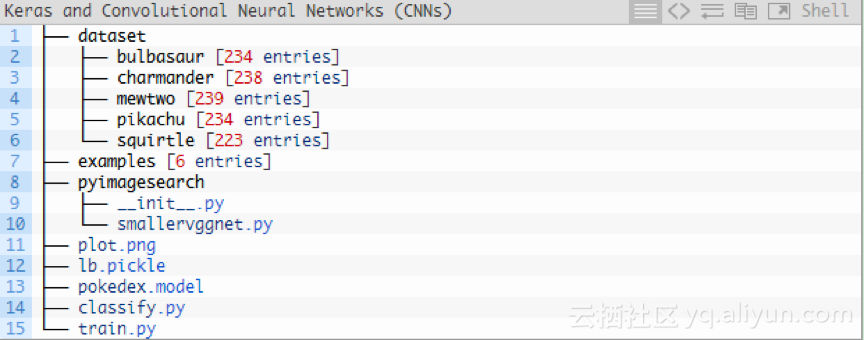
如上图所示,共分为3个目录:
1.数据集:包含五个类,每个类都是一个子目录。
2.示例:包含用于测试卷积神经网络的图像。
3.pyimagesearch模块:包含我们的SmallerVGGNet模型类。
另外,根目录下有5个文件:
1.plot.png:训练脚本运行后,生成的训练/测试准确性和损耗图。
2.lb.pickle:LabelBinarizer序列化文件,在类名称查找机制中包含类索引。
3.pokedex.model:序列化Keras CNN模型文件(即“权重文件”)。
4.train.py:训练Keras CNN,绘制准确性/损耗函数,然后将卷积神经网络和类标签二进制文件序列化到磁盘。
5.classify.py:测试脚本。
Keras和CNN架构
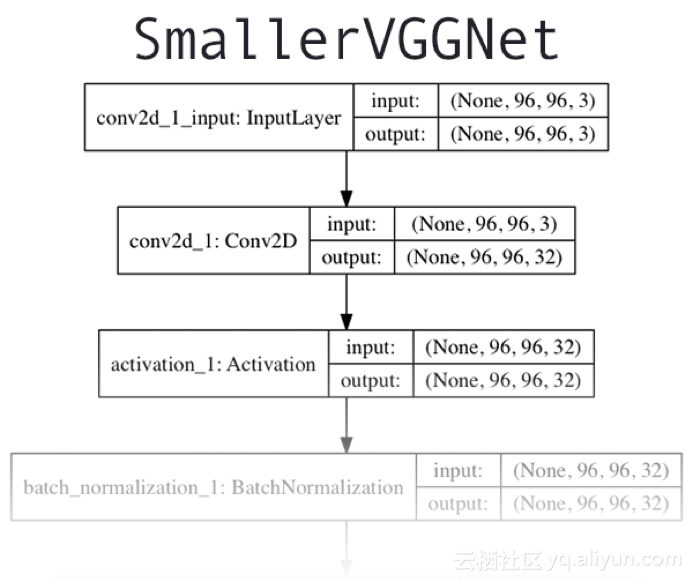
我们今天使用的CNN架构,是由Simonyan和Zisserman在2014年的论文“用于大规模图像识别的强深度卷积网络”中介绍的VGGNet网络的简单版本,结构图如上图所示。该网络架构的特点是:
1.只使用3*3的卷积层堆叠在一起来增加深度。
2.使用最大池化来减小数组大小。
3.网络末端全连接层在softmax分类器之前。
假设你已经在系统上安装并配置了Keras。如果没有,请参照以下连接了解开发环境的配置教程:
2.设置Ubuntu 16.04 + CUDA + GPU,使用Python进行深度学习。
继续使用SmallerVGGNet——VGGNet的更小版本。在pyimagesearch模块中创建一个名为smallervggnet.py的新文件,并插入以下代码:
注意:在pyimagesearch中创建一个_init_.py文件,以便Python知道该目录是一个模块。如果你对_init_.py文件不熟悉或者不知道如何使用它来创建模块,你只需在原文的“下载”部分下载目录结构、源代码、数据集和示例图像。
现在定义SmallerVGGNet类:
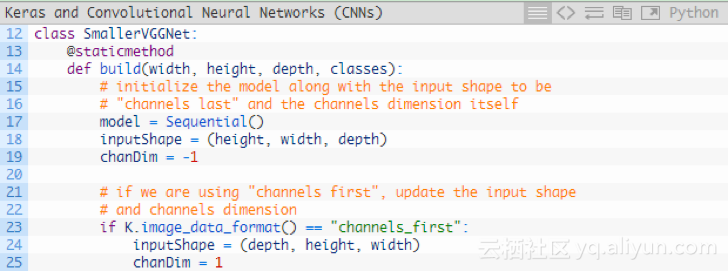
该构建方法需要四个参数:
1.width:图像宽度。
2.height :图像高度。
3.depth :图像深度。
4.classes :数据集中类的数量(这将影响模型的最后一层),我们使用了5个Pokemon 类。
注意:我们使用的是深度为3、大小为96 * 96的输入图像。后边解释输入数组通过网络的空间维度时,请记住这一点。
由于我们使用的是TensorFlow后台,因此用“channels last”对输入数据进行排序;如果想用“channels last”,则可以用代码中的23-25行进行处理。
为模型添加层,下图为第一个CONV => RELU => POOL代码块:
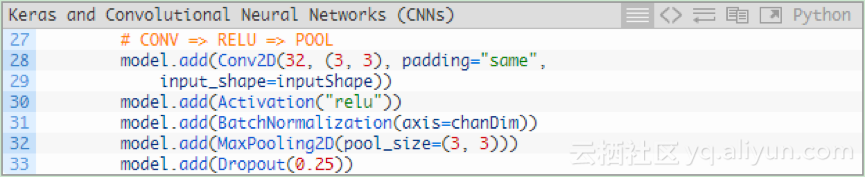
卷积层有32个内核大小为3*3的滤波器,使用RELU激活函数,然后进行批量标准化。
池化层使用3 *3的池化,将空间维度从96 *96快速降低到32 * 32(输入图像的大小为96 * 96 * 3的来训练网络)。
如代码所示,在网络架构中使用Dropout。Dropout随机将节点从当前层断开,并连接到下一层。这个随机断开的过程有助于降低模型中的冗余——网络层中没有任何单个节点负责预测某个类、对象、边或角。
在使用另外一个池化层前,添加(CONV => RELU)* 2层:
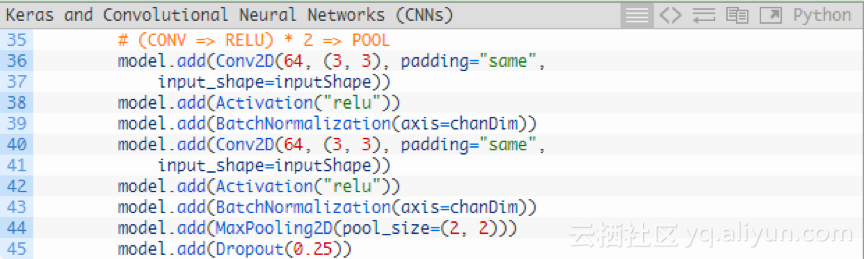
在降低输入数组的空间维度前,将多个卷积层RELU层堆叠在一起可以学习更丰富的特征集。
请注意:将滤波器大小从32增加到64。随着网络的深入,输入数组的空间维度越小,滤波器学习到的内容更多;将最大池化层从3*3降低到2*2,以确保不会过快地降低空间维度。在这个过程中再次执行Dropout。
再添加一个(CONV => RELU)* 2 => POOL代码块:
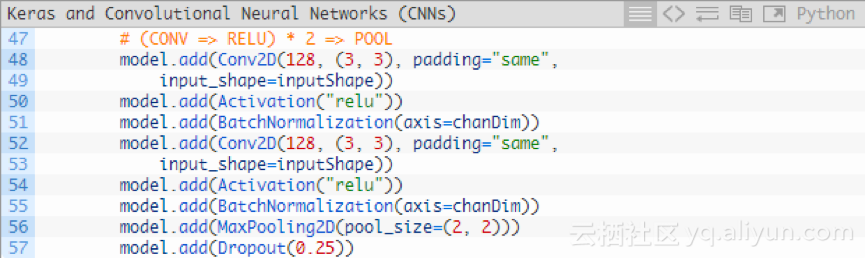
我们已经将滤波器的大小增加到128。对25%的节点执行Droupout以减少过拟合。
最后,还有一组FC => RELU层和一个softmax分类器:
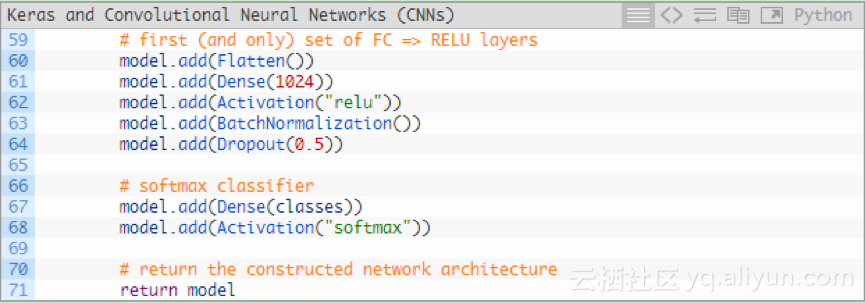
Dense(1024)使用具有校正的线性单位激活和批量归一化指定全连接层。
最后再执行一次Droupout——在训练期间我们Droupout了50%的节点。通常情况下,你会在全连接层在较低速率下使用40-50%的Droupout,其他网络层为10-25%的Droupout。
用softmax分类器对模型进行四舍五入,该分类器将返回每个类别标签的预测概率值。
CNN + Keras训练脚本的实现
既然VGGNet小版本已经实现,现在我们使用Keras来训练卷积神经网络。
创建一个名为train.py的新文件,并插入以下代码,导入需要的软件包和库:
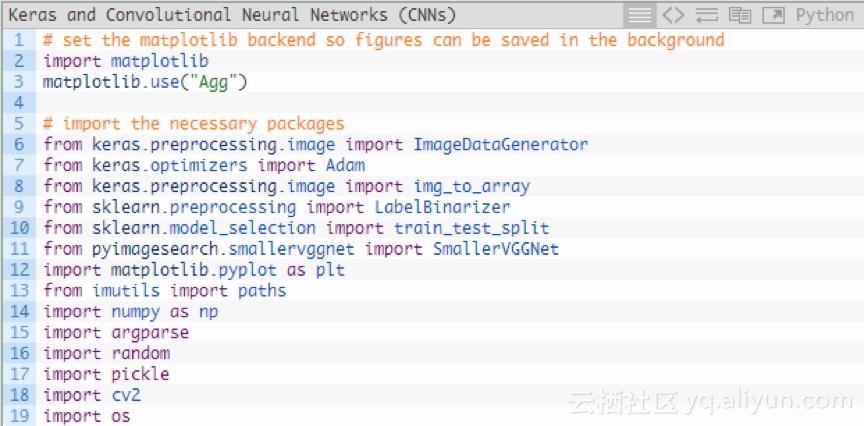
使用”Agg” matplotlib后台,以便可以将数字保存在背景中(第3行)。
ImageDataGenerator类用于数据增强,这是一种对数据集中的图像进行随机变换(旋转、剪切等)以生成其他训练数据的技术。数据增强有助于防止过拟合。
第7行导入了Adam优化器,用于训练网络。
第9行的LabelBinarizer是一个重要的类,其作用如下:
1.输入一组类标签的集合(即表示数据集中人类可读的类标签字符串)。
2.将类标签转换为独热编码矢量。
3.允许从Keras CNN中进行整型类别标签预测,并转换为人类可读标签。
经常会有读者问:如何将类标签字符串转换为整型?或者如何将整型转换为类标签字符串。答案就是使用LabelBinarizer类。
第10行的train_test_split函数用来创建训练和测试分叉。
读者对我自己的imutils包较为了解。如果你没有安装或更新,可以通过以下方式进行安装:
![]()
如果你使用的是Python虚拟环境,确保在安装或升级imutils之前,用workon命令访问特定的虚拟环境。
我们来解析一下命令行参数:
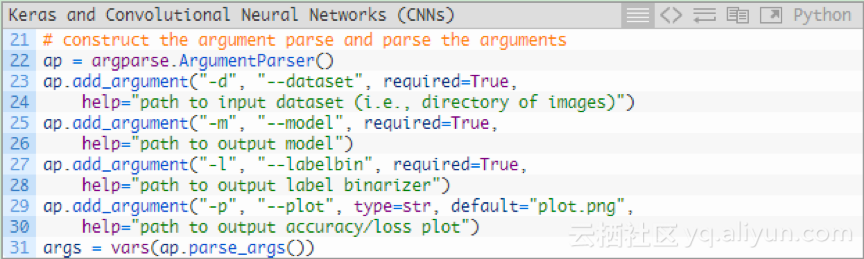
对于我们的训练脚本,有三个必须的参数:
1.--dataset:输入数据集的路径。数据集放在一个目录中,其子目录代表每个类,每个子目录约有250个精灵图片。
2.--model:输出模型的路径,将训练模型输出到磁盘。
3.--labelbin:输出标签二进制器的路径。
还有一个可选参数--plot。如果不指定路径或文件名,那么plot.png文件则在当前工作目录中。
不需要修改第22-31行来提供新的文件路径,代码在运行时会自行处理。
现在,初始化一些重要的变量:
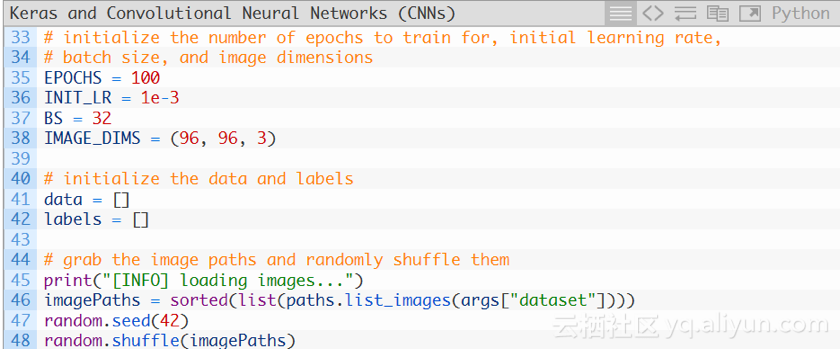
第35-38行对训练Keras CNN时使用的重要变量进行初始化:
1.-EPOCHS:训练网络的次数。
2.-INIT-LR:初始学习速率值,1e-3是Adam优化器的默认值,用来优化网络。
3.-BS:将成批的图像传送到网络中进行训练,同一时期会有多个批次,BS值控制批次的大小。
4.-IMAGE-DIMS:提供输入图像的空间维度数。输入的图像为96*96*3(即RGB)。
然后初始化两个列表——data和labels,分别保存预处理后的图像和标签。第46-48行抓取所有的图像路径并随机扰乱。
现在,对所有的图像路径ImagePaths进行循环:
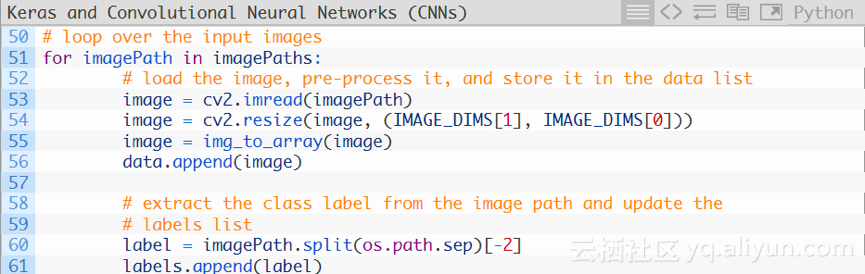
首先对imagePaths进行循环(第51行),再对图像进行加载(第53行),然后调整其大小以适应模型(第54行)。
现在,更新data和labels列表。
调用Keras库的img_to_arry函数,将图像转换为与Keras库兼容的数组(第55行),然后将图像添加到名为data的列表中(第56行)。
对于labels列表,我们在第60行文件路径中提取出label,并将其添加在第61行。
那么,为什么需要类标签分解过程呢?
考虑到这样一个事实,我们有目的地创建dataset目录结构,格式如下:
![]()
第60行的路径分隔符可以将路径分割成一个数组,然后获取列表中的倒数第二项——类标签。
然后进行额外的预处理、二值化标签和数据分区,代码如下:
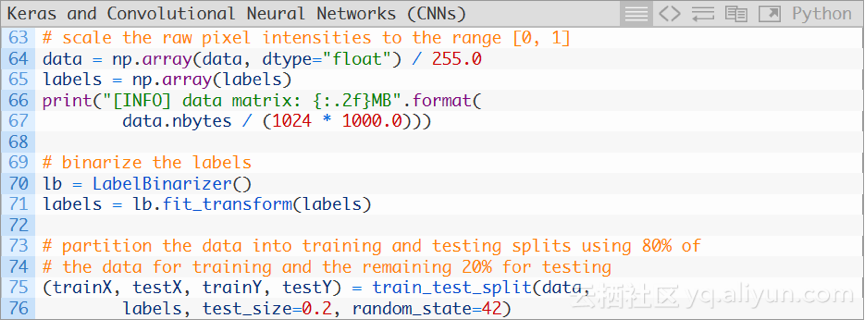
首先将data数组转换为NumPy数组,然后将像素强度缩放到[0,1]范围内(第64行),也要将列表中的labels转换为NumPy数组(第65行)。打印data矩阵的大小(以MB为单位)。
然后使用scikit-learn库的LabelBinarzer对标签进行二进制化(第70和71行)。
对于深度学习(或者任何机器学习),通常的做法是将训练和测试分开。第75和76行将训练集和测试集按照80/20的比例进行分割。
接下来创建图像数据增强对象:

因为训练数据有限(每个类别的图像数量小于250),因此可以利用数据增强为模型提供更多的图像(基于现有图像),数据增强是一种很重要的工具。
第79到81行使用ImageDataGenerator对变量aug进行初始化,即ImageDataGenerator。
现在,我们开始编译模型和训练:
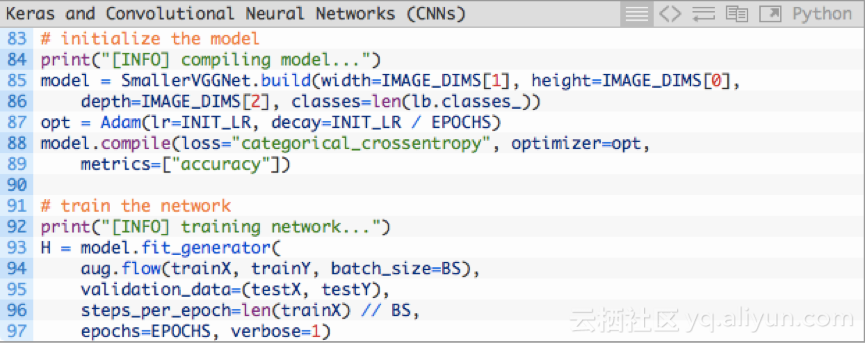
第85行和第86行使用96*96*3的输入图像初始化Keras CNN模型。注意,我将SmallerVGGNet设计为接受96*96*3输入图像。
第87行使用具有学习速率衰减的Adam优化器,然后在88行和89行使用分类交叉熵编译模型。
若只有2个类别,则使用二元交叉熵作为损失函数。
93-97行调用Keras的fit_generator方法训练网络。这一过程需要花费点时间,这取决于你是用CPU还是GPU进行训练。
一旦Keras CNN训练完成,我们需要保存模型(1)和标签二进制化器(2),因为在训练或测试集以外的图像上进行测试时,需要从磁盘中加载出来:
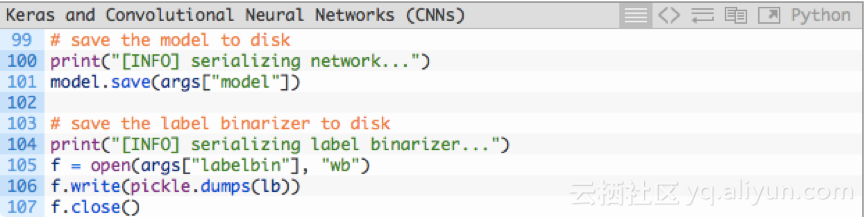
对模型(101行)和标签二进制器(105-107行)进行序列化,以便稍后在classify.py脚本中使用。
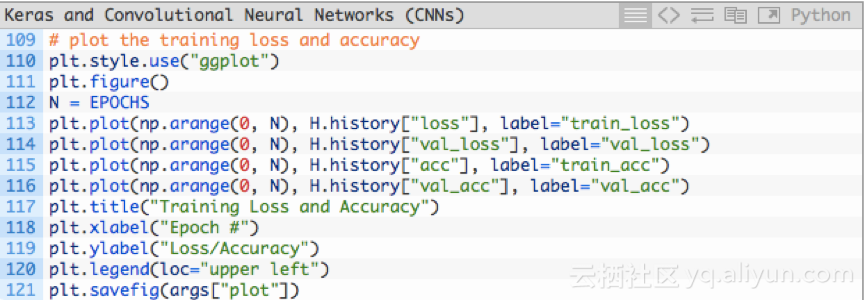
最后,绘制训练和损失的准确性图,并保存到磁盘(第121行),而不是显示出来,原因有二:(1)我的服务器在云端;(2)确保不会忘记保存图。
使用Keras训练CNN
执行以下代码训练模型:
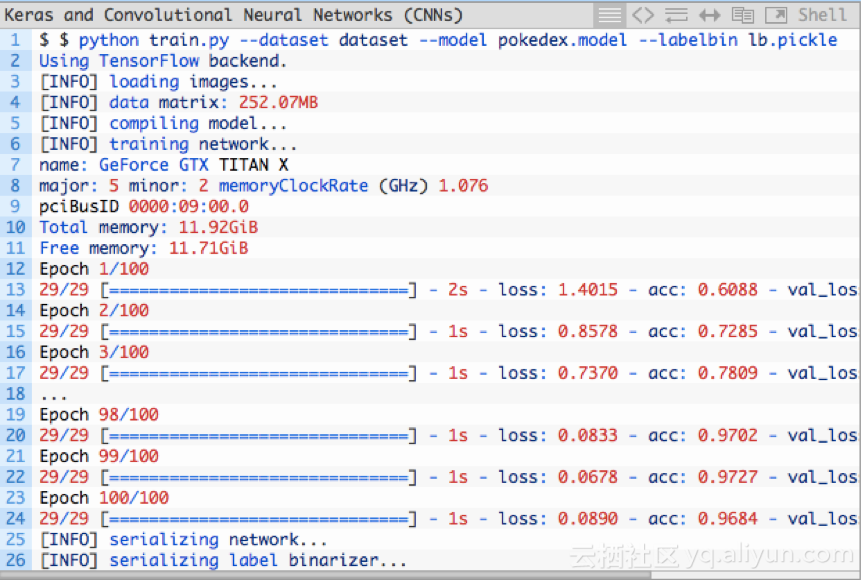
训练脚本的输出结果如上图所示,Keras CNN模型在训练集上的分类准确率为96.84%;在测试集上的准确率为97.07%
训练损失函数和准确性图如下:
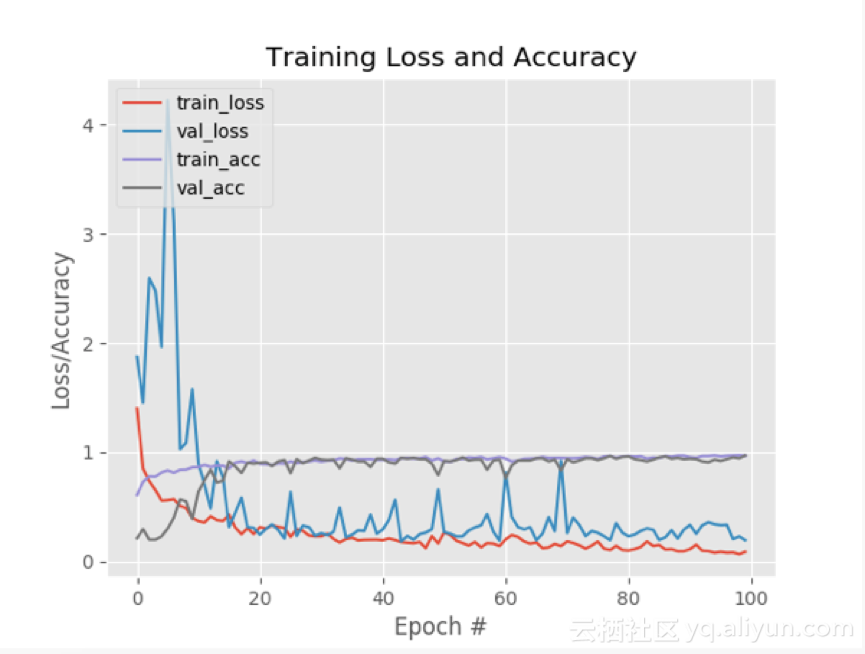
如上图所示,对模型训练100次,并在有限的过拟合下实现了低损耗。在新的数据上也能获得更高的准确性。
创建CNN和Keras的脚本
现在,CNN已经训练过了,我们需要编写一个脚本,对新图像进行分类。新建一个文件,并命名为classify.py,插入以下代码:
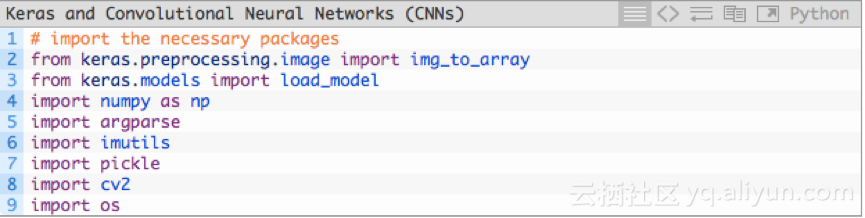
上图中第2-9行导入必要的库。
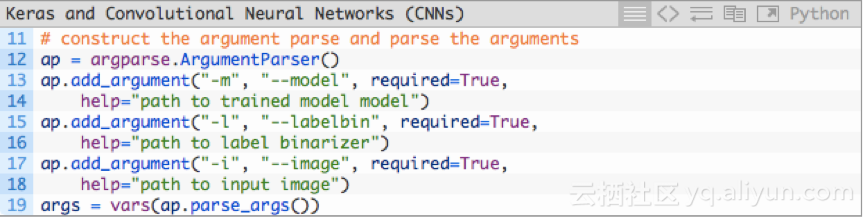
我们来解析下代码中的参数(12-19行),需要的三个参数如下:
1.--model:已训练模型的路径。
2.--labelbin:标签二进制器的路径。
3.--image:输入图像的路径。
接下来,加载图像并对其进行预处理:
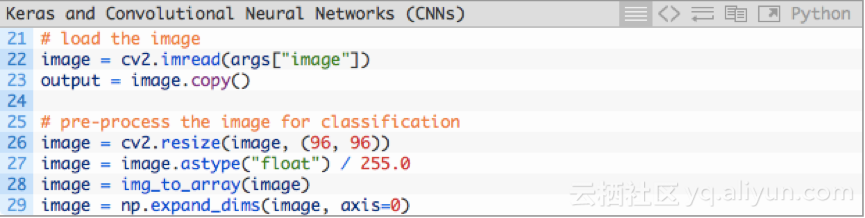
第22行加载输入图像image,并复制一个副本,赋值给out(第23行)。
和训练过程使用的预处理方式一样,我们对图像进行预处理(26-29行)。加载模型和标签二值化器(34和35行),对图像进行分类:
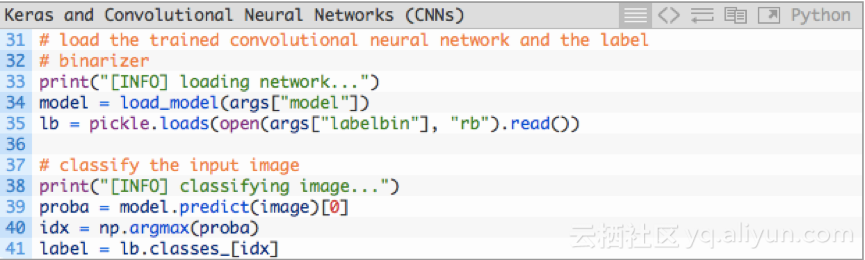
随后,对图像进行分类并创建标签(39-41行)。
剩余的代码用于显示:
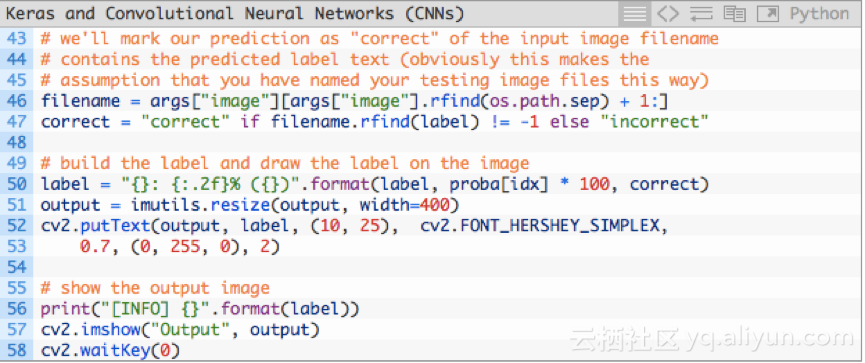
第46-47行从filename中提取精灵图鉴的名字,并与label进行比较。Correct变量是“正确(correct)”或“不正确(incorrect)”。然后执行以下操作:
1.50行将概率值和“正确/不正确”文本添加到类别标签label上。
2.51行调整输出图像大小,使其适合屏幕输出。
3.52和53行在输出图像上绘制标签。
4.57和58行显示输出图像并等待按键退出。
用KNN和Keras对图像分类
运行classify.py脚本(确保已经从原文“下载”部分获取代码和图片)!下载并解压缩文件到这个项目的根目录下,然后从Charmander图像开始。代码及试验结果如下:


Bulbasaur图像分类的代码及结果如下所示:


其他图像的分类代码和以上两个图像的代码一样,可自行验证其结果。
模型的局限性
该模型的主要局限是训练数据少。我在各种不同的图像进行测试,发现有时分类不正确。我仔细地检查了输入图像和神经网络,发现图像中的主要颜色会影响分类结果。
例如,如果图像中有许多红色和橙色,则可能会返回“Charmander”标签;图像中的黄色通常会返回“Pikachu”标签。这归因于输入数据,精灵图鉴是虚构的,它没有“真实世界”中的真实图像。并且,我们只为每个类别提供了比较有限的数据(约225-250张图片)。
理想情况下,训练卷积神经网络时,每个类别至少应有500-1,000幅图像。
可以将Keras深度学习模型作为REST API吗?
如果想将此模型(或任何其他深度学习模型)用作REST API运行,可以参照下面的博文内容:
3.使用Keras,Redis,Flask和Apache进行深度学习
总结
这篇文章主要介绍了如何使用Keras库来训练卷积神经网络(CNN)。使用的是自己创建的数据集(精灵图鉴)作为训练集和测试集,其分类的准确度达到97.07%。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Keras and Convolutional Neural Networks (CNNs)》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文。




