一、前言
个人感觉序列化简单来说就是按一定规则组包。反序列化就是按组包时的规则来接包。正常来说。序列化不会很难。不会很复杂。因为过于复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。就像压缩文件、解压文件,会占用大量cpu时间。
二、分配序列化空间的大小
说序列化之前先说下平台给序列化分配的buf的空间大小
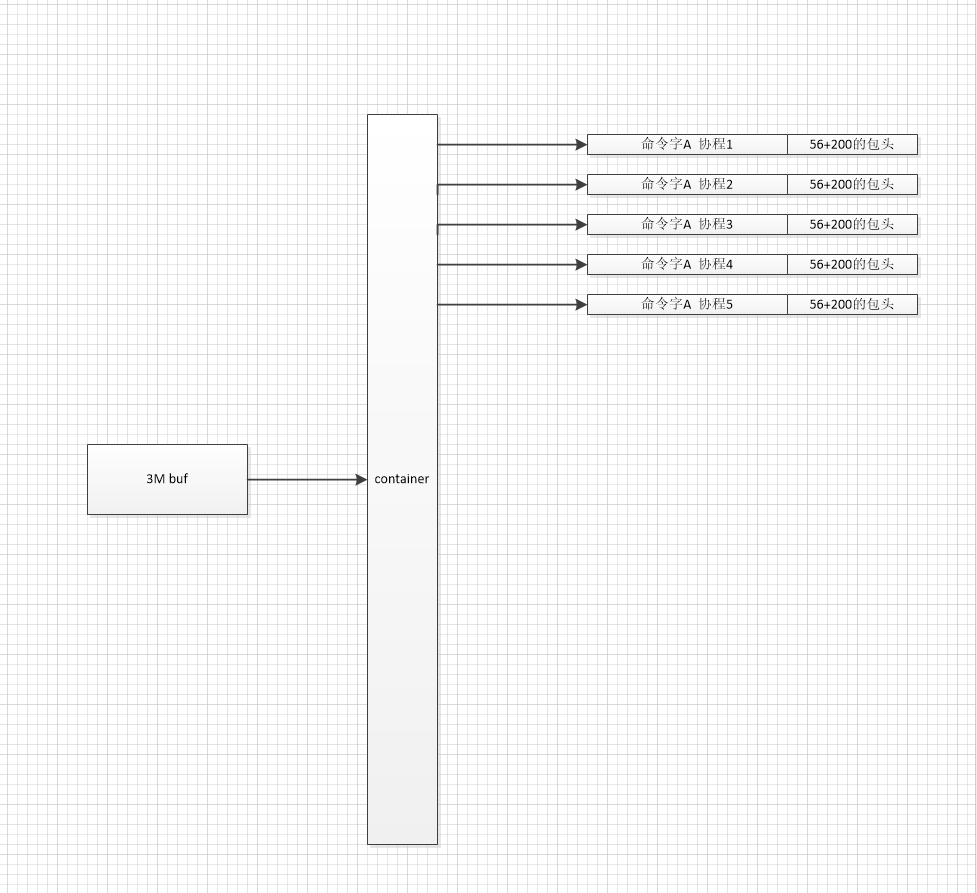
三、序列化步骤
1、我们先看下请求。


oCntlInfo.setOperatorUin(10458);
oCntlInfo.setOperatorKey("abcde");
oCntlInfo.setRouteKey(1234);
std::string source = "aaaaa";
std::string inReserve;
std::string errmsg;
std::string outStr;
std::string machineKey;
for(int i =0;i<500*1024;i++)
{
machineKey.append("a");
}
AoActionInfo oActionInfo;
oActionInfo.SetDisShopId(1111);
oActionInfo.SetDistributorId(2222);
uint32_t dwResult = Stub4App.AddActionSupplier(
oCntlInfo,
machineKey,
source,
1,
1,
oActionInfo,
inReserve,
errmsg,
outStr);
if(dwResult == 0)
{
std::cout << "Invoke OK!" << std::endl;
std::cout << "Invoke OK!" << std::endl;
}
客户端直接调用函数接口。到服务端请求结果
函数的入参都是我们需要序列化的内容。注意这里是rpc调用的一个关键点。
2、序列化开始
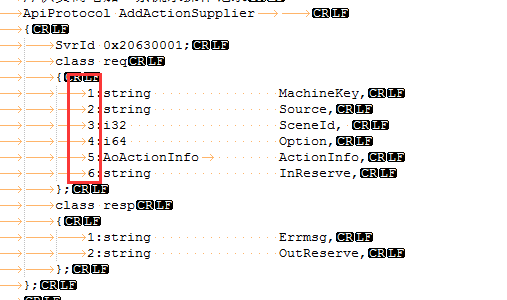
a) 先看下我们的thritf
如果下图。发现我们的函数入参也是打上了tag标志的。作用跟我们在结构体中打tag标志是一样的。为了标识一个字段的含义。
序列化的时候把这些tag序列化进去。 然后反序列化的时候靠这些tag来解析
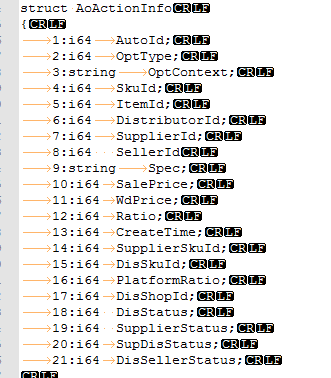
b ) 先把图贴出来。按着图来讲更清晰些

CByteStream(char* pStreamBuf = NULL, uint32_t nBufLen = 0,bool bStore=true, bool bRealWrite = true);
1)int32_t* pLen = (int32_t*)bs.getRawBufCur(); 2)bs << 0; 3)int32_t iLen=bs.getWrittenLength(); 4)Serialize_w(bs); 5)*pLen = bs.getWrittenLength() - iLen;
f)最后对整个_Cao_action_AddActionSupplier_Req写了两个字节的包尾
其实我们可以看到我们的这种序列化,很整齐。很规则。比较紧凑。但是并不节省空间。这个里面有很多数据可以压缩的。但是压缩带来一个问题就是解压的时候很消耗cpu的。跟我的业务场景不服和。也没必要。
四、序列化解析
其实知道了数据是怎么写入的 解析起来就很容易了。其实这种序列化就是两边约定规则。知道规则以后就可以解析了
解析的具体步骤就不详细说了。这里说下解析的时候几个特殊的地方
五、话外
我们的这一套就是远程调用rpc服务。通过我们的序列化。
其实就能了解所谓的RPC服务是什么样的。
说白了,远程调用就是将对象名、函数名、参数等传递给远程服务器,服务器将处理结果返回给客户端。
为了能解析出这些信息。在入参的时候做上标识(这里是打tag).
谷歌的protobuf也用过。跟thrift其实差不多但是序列化和反序列的话的具体实现是有些不同的。
谷歌的protobuf更节省空间
以前具体看过序列化的源码。觉得序列化反序列化以及rpc很神秘。现在看了源码才发现确实写的确实好,
但是没那么神秘里。其实就是按一定规则组包。所以还是要多看源码啊。
我们用的thrift就是 facebook的thrift。但是改了些东西。大体是一样的。
