We are already living in the era of Big Data. Big Data technology and products are ubiquitous in every aspect of our lives. From online banking to smart homes, Big Data has proven to be enormously useful in their respective use cases.
Redis—a high-performance key value database— has become an essential element in Big Data applications. As a NoSQL database, Redis helps enterprises make sense out of data by making database scaling more convenient and cost-effective. Cloud providers from across the globe, including Alibaba Cloud, are now offering a wide variety of Redis-related products for Big Data applications, such as Alibaba Cloud ApsaraDB for Redis.
This article introduces two methods of combining Redis with other Big Data technologies, specifically Hadoop and ELK.
Redis and Hadoop
Prominent in the world of big data, Hadoop is a distributed computing platform. With its high availability, expandability, fault tolerance, and low costs, it has now become a standard for Big Data systems. However, Hadoop's HDFS storage system makes it difficult to face end user applications (such as using a user’s browser history to recommend news articles or products). Therefore, the common practice is to send offline computing results to user-facing storage systems such as Redis and HBase.
Even though it is not suitable for facing end users, Hadoop is extremely versatile and useful in that it supports custom OutputFormat. If you need a customized output, all you have to do is inherit the OutputFormat by defining Redis OutputFormat in the Redis terminal to complete mapping.

Of course, there are rare situations where Redis is the output source, but luckily Hadoop also provides custom InputFormat functionality.

When you choose to use Redis, you can decide whether to use the Master-Slave version or the cluster version according to the scope of your results.
Redis and ELK
ELK is a combination of the three open-source tools ElasticSearch, Logstash, and Kibana. It has found wide-spread use in the field of log processing due to its flexible processing method, simple configuration, efficient search performance, and easy-to-use front-end interface,
Basic workflow is illustrated as below:
- LogStashAgent is deployed to each target machine, where it collects data based on logstash syntax and then sends it to ElasticSearch.
- ElasticSearch is then responsible for storing and indexing the data in LogAgent.
- Kibana interacts directly with ElasticSearch and is responsible for visual log analysis.
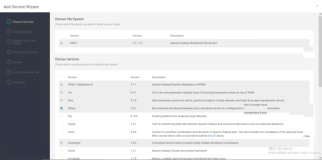
However, if there are too many LogStashAgent entries or too many indexes, pushing all data directly into ElasticSearch will generate too much stress. Typically when faced in such situation, a buffer pool is commonly set up between ElasticSearch and LogStash. Redis is typically selected to serve as the buffer pool. This is facilitated by ELK’s default support for Redis integration. The entire process can be completed by simply changing a few settings, as outlined in the image below:

Concluding Remarks
Redis is now a major component used in many Big Data applications. Redis is a favorable alternative to traditional relational database services because of its scalability and wide support for various programming languages. Alibaba Cloud ApsaraDB for Redis is a key value database service that offers in-memory caching and high-speed access to applications hosted on the cloud. Try Alibaba Cloud ApsaraDB for Redis for free today with the $300 New User Free Credit.