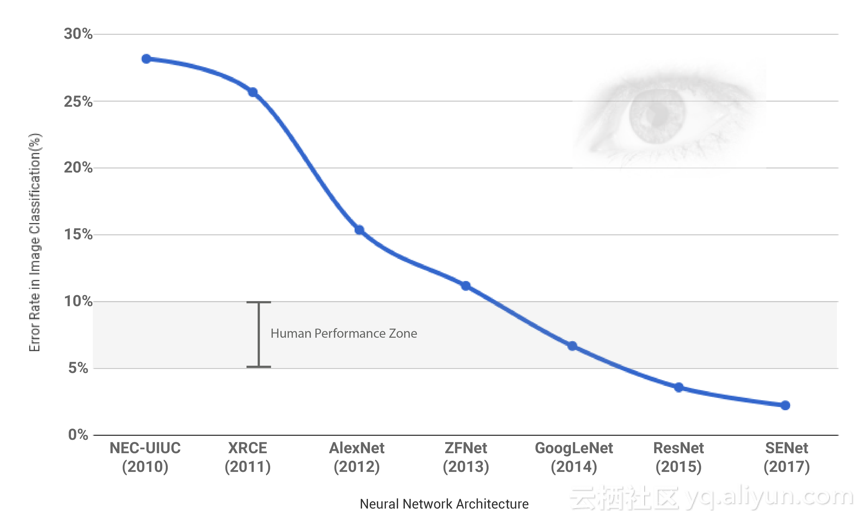
从ILSVRC中可以看出,近几年图像分类神经网络架构的错误率以惊人的幅度下降
深度学习已经存在了几十年,Yann Lecun在1998年就发表了一篇关于卷积神经网络(CNN)的论文。但是直到十年前,深度学习才开始真正的发展并慢慢成为人工智能研究的主要焦点领域。这些转变主要是因为处理能力(即 GPU)的增强、大量可用性的数据(即Imagenet数据集)以及新的算法和技术。2012年,AlexNet(一种大型深度卷积神经网络),赢得了年度ImageNet大规模视觉识别挑战赛(ILSVRC)。
从此以后,CNN的变体开始在ILSVRC中称霸,并超过人类精确度的水平。
作为人类,我们很容易理解图像的内容。例如,在观看电影时,我们认知一个东西是矮人后,可以轻松的去识别其他的矮人。然而,对于一台机器来说,这项任务极具挑战性,因为它在这幅图中看到的是一组数字。

在本篇文章中作者基于以往在深度学习方面的经验,列出了一些具有启发性的研究论文,这些论文是任何与计算机视觉相关的人必读的。
关于图像分类的开创性研究论文
在2012年的ILSVRC 中,Alex Krizhevsky,IIya Sutskever和Geoffrey Hinton介绍了一种深度卷积神经网络-AlexNet。在这场比赛中AlexNet的以15.4%的错误率拿下榜首,并远超第二名(第二名的错误率是26.2%)。AlexNet的这一傲人成绩震撼了整个计算机视觉社区,并使深度学习和CNN得到了很大的重视。
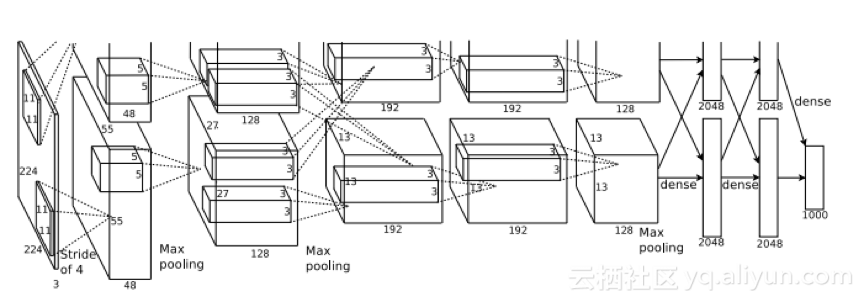
这个CNN架构模型清晰地展示了两个GPU之间的责任划定:一个GPU运行图形顶部的图层部分,另一个运行图层底部的图层部分。
这是第一个在ImageNet数据集上表现得非常好的模型,AlexNet奠定了深度学习的基础。它仍然是关于深度学习中引用次数最多的论文之一,被引用约7000次。
Matthew D Zeiler(Clarifai的创始人)和Rob Fergous夺得了2013年ILSVRC的冠军,它将错误率降至11.2%。ZFNet引入了一种新颖的可视化技术,可以深入了解中间要素图层的功能以及分类器的运行情况,而这些AlexNet都没有。
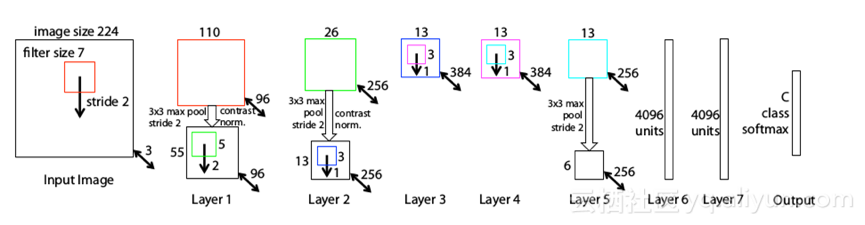
ZFNet的网络架构
ZFNet利用被称为解卷积网络(Deconvolutional Networks)的技术检查不同功能激活以及与输入空间关系。
牛津大学的Karen Simonyan和Andrew Zisserman创建了深度CNN,被选为2014年ISLVRC图像分类比赛中的第二名。VGG Net表明,通过将深度增加到16-19个重量层可以实现对现有技术配置的显著改进。
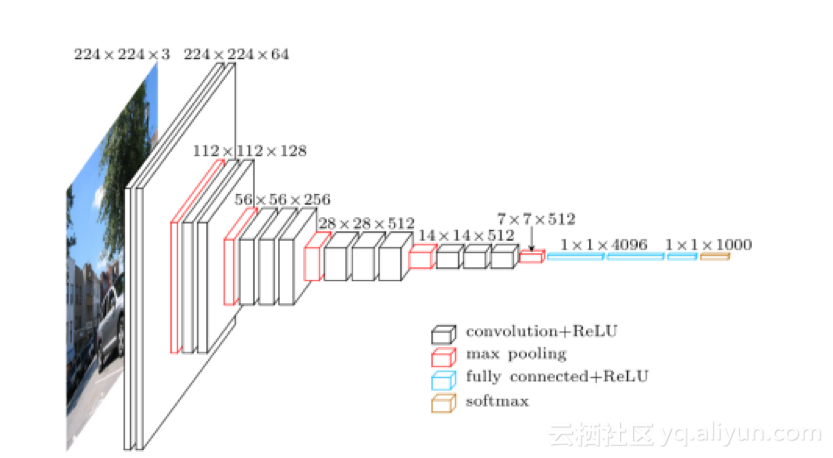
VGG网络的宏观架构
该架构很容易理解(比GoogleLeNet更为简单),但仍然可以表现出最佳的准确性。它的特征映射现在在转移学习和其他需要预先训练的网络的算法中被大量使用,如大多数生成式对抗网络(GANs)。
2014年ISLVRC的获奖者Christian Szegedy等提出了一个名为GoogLeNet的22层神经网络。这是一种初始模型,巩固了Google在计算机视觉领域的地位。GoogLeNet将错误率下降到6.7%。这种架构的主要特征在于提高了网络内部计算资源的利用率。这是通过精心设计实现的,可以在保持计算预算不变的同时增加网络的深度和宽度。GooLeNet引入了Inception module的概念,并不是所有的事情都是按顺序发生的,存在一些并行发生的网络部分。
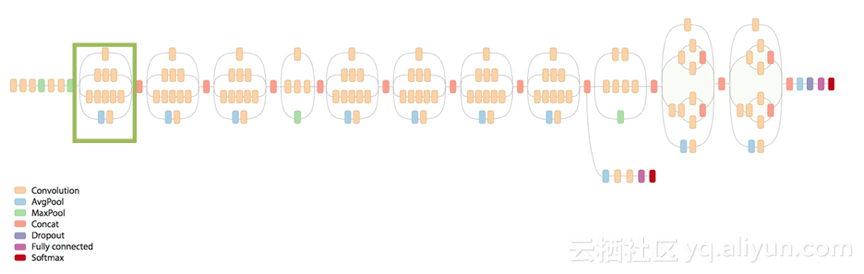
GoogLeNet架构的示意图,突出显示的框是启动模块。
值得注意的是,GoogLeNet的错误率接近人类的表现。GoogLeNet是第一批将CNN图层并不总是按顺序叠加的概念化模型之一。
微软的ResNet由Kaiming He、Xiangyu Zhang和Shaoqing Ren开发,它是一种学习框架,用于缓解比以前更深的网络训练。作者提供了全面的经验证据,表明这些残留网络更容易优化,并且可以通过增加深度提高准确性。
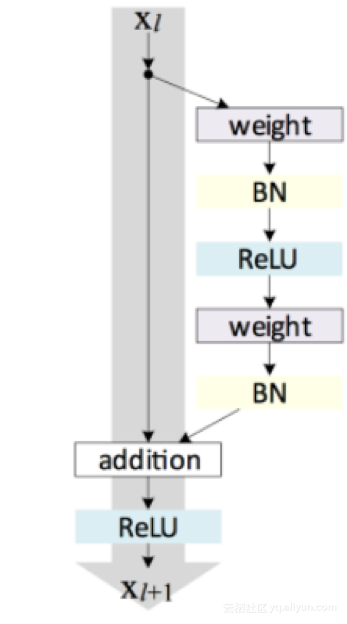
ResNet架构中的残余块。
ResNet以一种新的152层网络架构,其错误率为3.57%,超过了人类的性能,通过一个令人难以置信的架构在分类、检测和本地化领域创造了新的记录。
Sergey Zagoruyko和Nikos Komodakis在2016年发表了这篇论文,对ResNet模块的架构进行了详细的实验研究,在此基础上他们提出了一种新颖的架构,它可以减少整个网络的深度并增加残余网络的宽度。
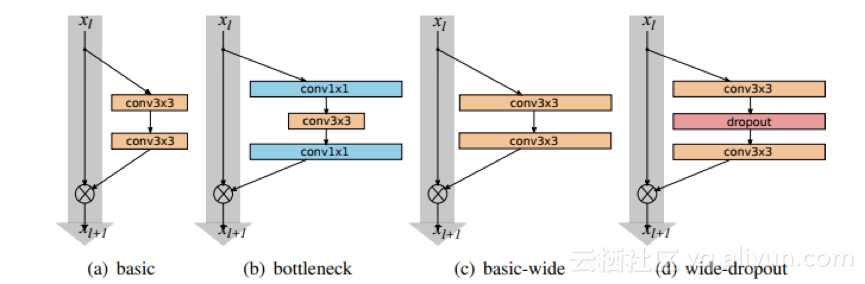
作者使用的各种残余块
作者将最终的网络结构命名为宽残差网络(WRNs)。与ResNet的卷积层相比,Wide ResNet可以具有2-12倍甚至更多的特征映射。
ResNeXt在2016年的ILSCRV 中获得第二名。它是一个简单的高度模块化的图像分类网络架构。ResNeXt设计产生了一种同构的多分支体系结构,只有少数超参数可供设置。
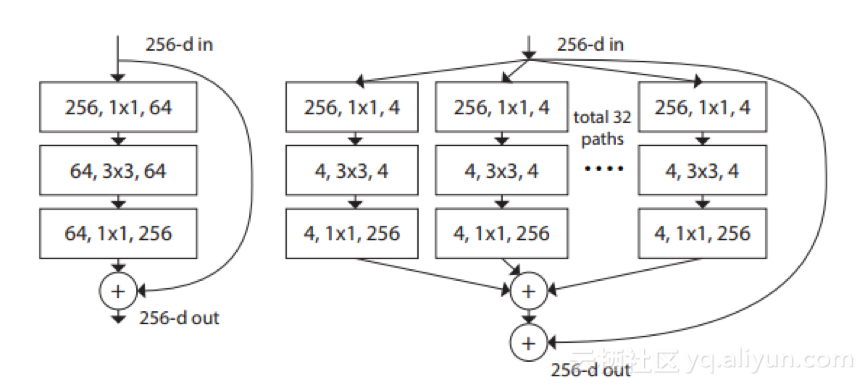
一个ResNeXt块(右)与一个ResNet块(左)
这种策略揭示了一个新的维度,作为除深度和宽度维度以外的一个重要因素,作者将其命名为“基数”。容量增加时,增加基数比变深或变宽更有效。因此,它的准确性要高于ResNets和Wide ResNets。
密集卷积网络由Gao Huang, Zhuang Liu,Kilian Q.Weinberger和Laurens van der Maaten在2016年开发,以前馈方式将每层连接到每个其他层。对于每一层,前面所有图层的特征映射都被用作输入,并且它自己的特征映射被用作所有后续图层的输入。
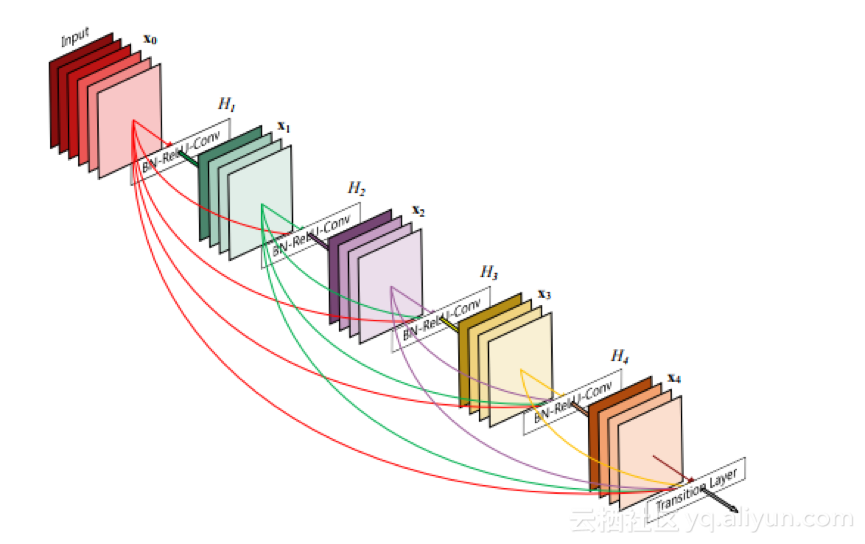
一个5层密集块。每个图层都将前面的所有要素图作为输入。
DenseNet有几个引人注目的优点,例如缓解梯度消失问题,加强特征传播,鼓励特征重用以及大幅度减少参数数量。DenseNet胜过ResNets,同时需要更少的内存和计算来实现高性能。
新的构架具有前景广阔的未来潜力
CNN的变体可能主宰图像分类体系结构设计。Attention Modules和SENets将在适当的时候变得更加重要。
2017年ILSCRV 的获奖作品Squeeze-and-Excutation Networks(SENet)在比赛中错误率为令人难以置信的2.251%,该作品适用于挤压、激励和缩放操作。SENets并没有为特征通道的整合引入新的空间,而是开展了一项新的“特征重新校准”策略。
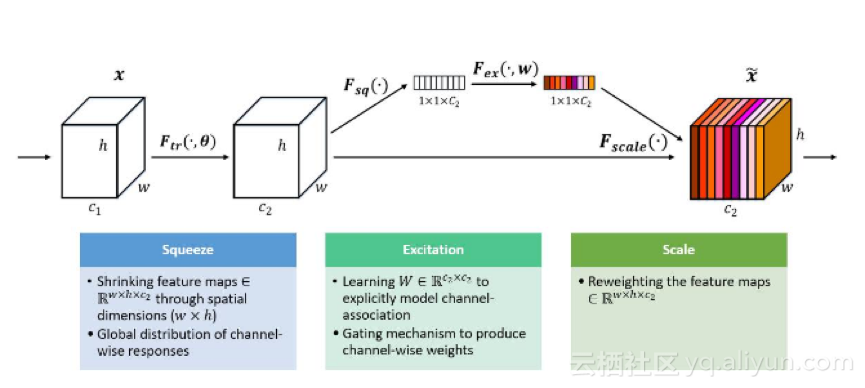
SENet模型的示意图:挤压,激励和缩放操作
作者模拟了功能通道之间的相互依赖关系。训练SENet可以自动获得每个功能通道的重要性,并利用这个来增强有用的功能。
Residual Attention Network是一种使用注意机制的卷积神经网络,可以以端到端的训练方式与先进的前馈网络架构(state-of-art feed forward network)相结合。注意力残留学习用于训练非常深的Residual Attention Networks,这些网络可以轻松扩展到数百层。

Residual Attention Network分类插图:选择的图像显示不同的功能在参与注意网络中具有不同的对应注意掩码。天空面具减少了低级别的背景蓝色功能。气球示例蒙版突出显示高级气球底部特征。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Must-read Path-breaking Papers About Image Classification》
作者:PARTH SHRIVASTAVA
译者:乌拉乌拉,审校:袁虎。
文章为简译,更为详细的内容,请查看原文文章。




