PostgreSQL 是全球最先进的开源数据库。作为学院派关系型数据库管理系统的鼻祖,它的优点主要集中在对 SQL 规范的完整实现以及丰富多样的数据类型支持(JSON 数据、IP 数据和几何数据等,大部分商业数据库都不支持)。除了完美支持事务、子查询、多版本控制(MVCC)、数据完整性检查等特性外,阿里云数据库RDS for PostgreSQL 版还集成了高可用和备份恢复等重要功能,减轻用户的运维压力。
PostgreSQL提供慢日志、SQL 运行报告、缺失索引等优化建议,用户可以根据优化建议并结合自身的应用方便的对数据库进行优化。接下来我们将介绍一下云数据库PostgreSQL 版性能优化的具体操作:
操作步骤
1.登录 RDS 管理控制台,选择【目标实例】。
2.在实例菜单中选择 【性能优化】。
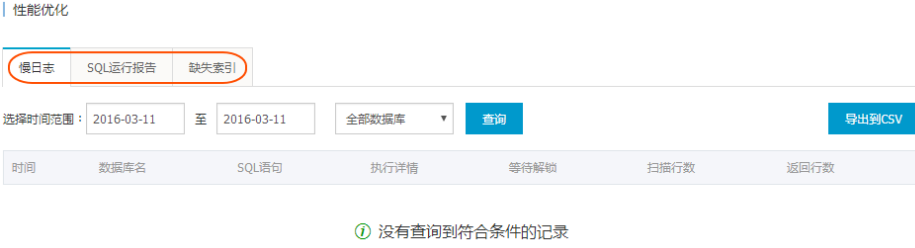
3.在 性能优化 页面,查询 慢日志、SQL 运行报告、缺失索引 信息,如下图所示。
对数据库PostgreSQL性能优化
以下是影响数据库性能的主要因素,用户可以根据这些信息采取一些措施来优化数据库:
慢日志:记录 1 个月内数据库中执行时间超过 1 秒(可以在 参数设置 中修改 long_query_time 参数来设置)的 SQL 语句,并进行相似语句去重,我们可以通过查询指定时间段内的指定数据库或者全部数据库进行优化数据库。
SQL 运行报告:SQL执行次数TOP10:统计执行时间大于5ms且执行次数排名前十的的SQL语句;
SQL执行时间TOP10:统计执行时间排名前十且大于100ms的SQL语句; SQL语句取前128个字符。我们可以通过查询指定时间段内执行次数 TOP10 的 SQL 或者执行时长 TOP10 的 SQL来优化数据库。
缺失索引:记录缺失索引的数据库表信息,并推荐用户创建索引的 SQL 语句,用户可以根据推荐创建索引的 SQL 语句优化 SQL。