通过基于区块链市场产生的数据训练出的机器学习模型有可能成为世界上最强大的人工智能。它们结合了两个强大的原始资源:私人机器学习,允许在不透露敏感私人数据的情况下进行训练,以及基于区块链所带有的激励机制,这些激励机制允许这些系统可以吸引最佳数据和模型,使其更加智能化。其最后导致的结果是开放的市场,任何人都可以出售他们的数据并保持其数据的私密性,而开发人员则可以使用激励措施为他们的算法吸引最佳数据。译者注:著名的华人物理学家张首晟也曾表示过区块链可以很好的解决人工智能需要大量的数据的难题。
起源
这个想法的基础是在2015年与理查德· 努梅莱的谈话中获得的。Numerai是一家对冲基金,它将加密的市场数据发送给任何想要竞争模拟股市的数据科学家,然后根据他们打造的模型性能的良好程度进行不同级别的奖励。
创建:
举个例子:我们试着创建一个完全分散的系统,用于在分散交易所交易加密货币。这是未来的一个方向:
数据:数据提供者可以获取数据并将其提供给建模人员。
模型构建:建模者选择要使用的数据并创建模型。训练是使用安全的计算方法完成的,该方法允许模型在不暴露底层数据的情况下进行训练。
元模型:构建元模型是基于考虑每个模型的算法创建的。
使用元模型:智能合约通过分散交换机制在链上以编程方式进行元模型交易。
分配收益/损失:经过一段时间后,交易产生利润或亏损。这种利润或损失是根据元模型的贡献者分成多少,这取决于他们制作多少智能元素。然后,模型转向并对其数据提供者执行类似的分发/股权削减。
可验证的计算:每个步骤的计算是集中式的,但可以使用像Truebit这样的验证游戏进行验证和挑战,或者使用安全的多方计算进行分散。
托管:数据和模型要么托管在IPFS上,要么托管在安全的多方计算网络中,因为链上存储将会过于昂贵。
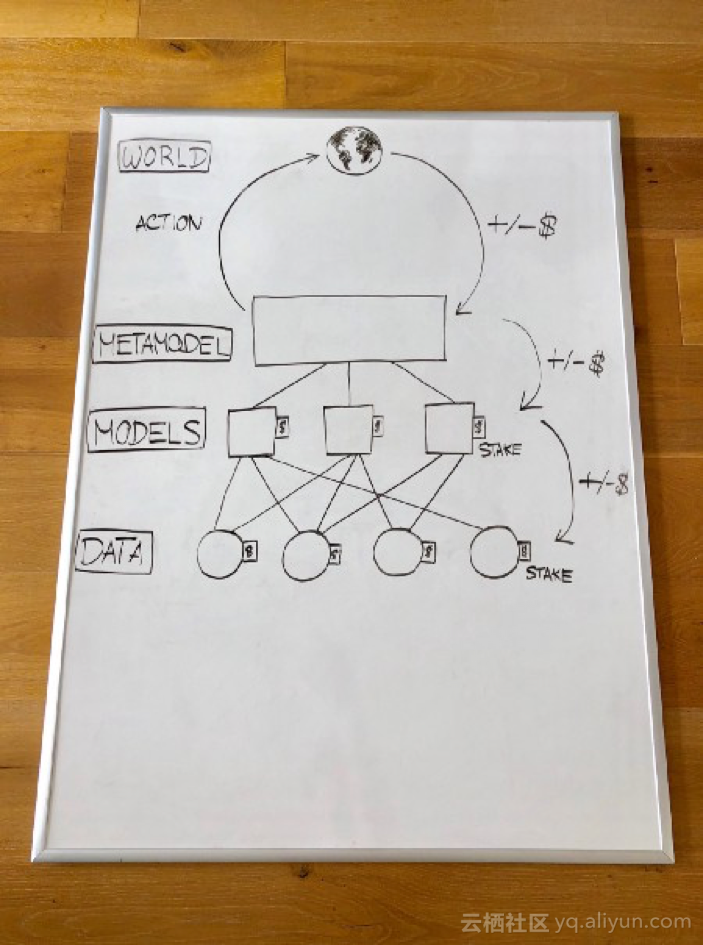
是什么让这个系统强大?
吸引全球最佳数据:吸引数据的激励措施是系统中最有效的部分,因为数据往往成为大多数机器学习的限制因素。比特币就是以同样的方式,通过开放式激励机制创建了一个全球计算能力最强的紧急系统,适当设计的数据激励结构将为你的应用程序带来世界上最好的数据。关闭数千或数百万个数据来源的系统几乎是不可能的。
算法之间的竞争:在以前不存在的地方创建模型/算法之间的公开竞争,使用数千种竞争新闻源算法来分散Facebook。
奖励的透明度:数据和模型提供商可以看到他们获得了他们提交的公平价值,因为所有计算都是可验证的,使他们更有可能参与。
自动化:在链上直接生成值并在令牌中直接生成值创建了一个自动化的,不受信任的闭环。
网络效应:数据提供者和数据科学家多面的网络效应使系统自我强化。它的表现越好,吸引的资金就越多,这意味着更多的潜在支出,这吸引了更多的数据提供者和数据科学家,他们使系统变得更加智能化,从而吸引更多的资金。
安全计算:安全的计算方法允许模型在数据上进行训练而不会泄露数据本身。目前使用和研究的安全计算有三种主要形式:同态加密(HE),多方安全计算(MPC)和零知识证明(ZKPs)。多方安全计算是最常用的专用机器学习计算方式,作为同态加密往往过于缓慢。安全计算方法是处于计算机科学研究的前沿技术,它们通常比常规计算慢几个数量级,但近年来一直在改进。
终极推荐系统:
为了证明私人机器学习的潜力,想象一下名为“终极推荐系统”的应用程序。它会监视你在设备上执行的所有操作:你的浏览记录、你在应用中执行的所有操作、手机上的图片、位置数据、消费记录、可穿戴传感器、短信、家中的相机。然后给你推荐:你应该访问的下一个网站、阅读文章、听歌或购买产品,这个推荐系统会非常有效。比谷歌,Facebook或其他任何现有的数据孤岛都要多,因为它对你更了解,它可以从你的私人数据中学习。与以前的加密货币交易系统的例子类似,它可以通过允许一个专注于不同领域的模型市场(例如:网站推荐,音乐)竞争访问你的加密数据并向你推荐某些东西,甚至可能为你提供数据。
目前的方法
来自Algorithmia Research的一个简单结构将模型的精确度设置为高于某个回测阈值:
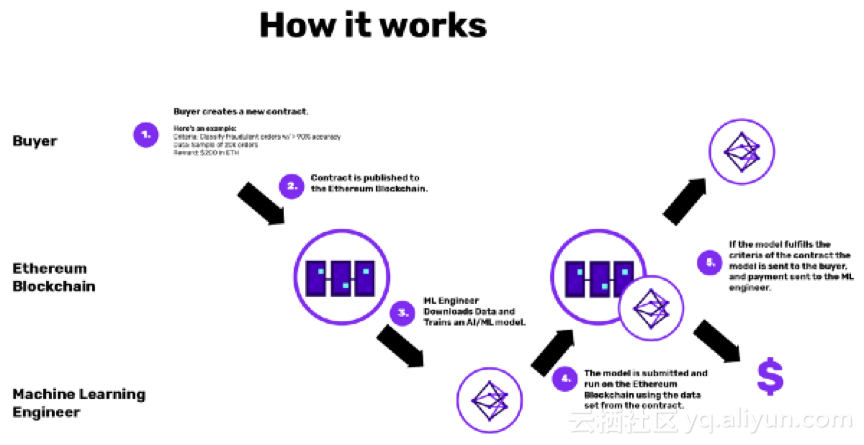
由Algorithmia Research创建机器学习模型的简单构造
Numerai目前采取三个步骤:它使用加密数据(尽管不完全同态),它将众包模型结合到元模型中,并根据未来表现奖励模型,而不是通过回溯测试。
还有一些人正在开始构建安全的计算网络。Openmined正在创建一个多方计算网络,用于在Unity上训练机器学习模型,该网络可以在任何设备上运行,包括游戏控制台(类似于家中的Folding),然后扩展以确保MPC的安全。
最终状态将是相互拥有的元模型,它使数据提供者和模型创建者的所有权与他们做出更聪明的决定成比例。这些模型将被标记化,随着时间的推移可以派发股息,甚至可能受到训练者的支配。这是一种互相拥有的蜂巢式思维。
启示
首先,分散式的机器学习市场可以消除目前科技巨头的数据垄断。在过去的20年中,他们将互联网上的主要价值创造源头标准化和商品化:专有数据网络和围绕它们的强大网络效应。结果——价值创造从数据转移到算法。
第二,他们创造了世界上最强大的AI系统,通过直接的经济激励为他们吸引最好的数据和模型。他们的力量通过多方面的网络效应而增加。随着Web 2.0时代的数据网络垄断变得商品化,它们似乎成为下一个重新聚合点的理想选择。
第三,正如推荐系统的例子所显示的,搜索是颠倒的——不是我们在找产品而是产品再找我们。每个人都可能有个人策略市场,推荐系统在竞争中将最相关的内容放入其供稿中,并且相关性由个人定义。
第四,它们使我们能够从Google和Facebook等公司获得的服务是一样的,并且不会泄漏我们的数据。
第五,机器学习可以更快地推进,因为任何工程师都可以访问开放的数据市场,而不仅仅是大型Web 2.0公司的一小部分工程师。
挑战
首先,安全计算方法目前非常缓慢,机器学习的计算成本太高。另一个好消息是科学界对安全计算方法的兴趣已经开始出现,性能正在不断提高。
其次,计算为元模型提供的一组特定数据或模型的值是很难,清理和格式化众包数据是具有挑战性的。
最后,具有讽刺意味的是,创建这种系统的广义构造的商业模式不如创建个体实例那么明确,这似乎是很多新的加密原语。
结论
私人机器学习与区块链激励相结合,可以在各种应用中创造出最强大的机器智能。随着时间的推移,可以解决很多重大的技术挑战。他们的长期潜力是巨大的,他们是可怕的:他们引导自己存在、自我强化、训练私人数据、并且几乎不可能关闭。无论如何,它们将是加密货币如何缓慢地进入每个行业的又一例证。
本文由@阿里云云栖社区组织翻译。
文章原标题《blockchain-based-machine-learning-marketplaces》
作者:Fred Ehrsam
译者:虎说八道 审校:袁虎。
文章为简译,更为详细的内容,请查看原文文章
