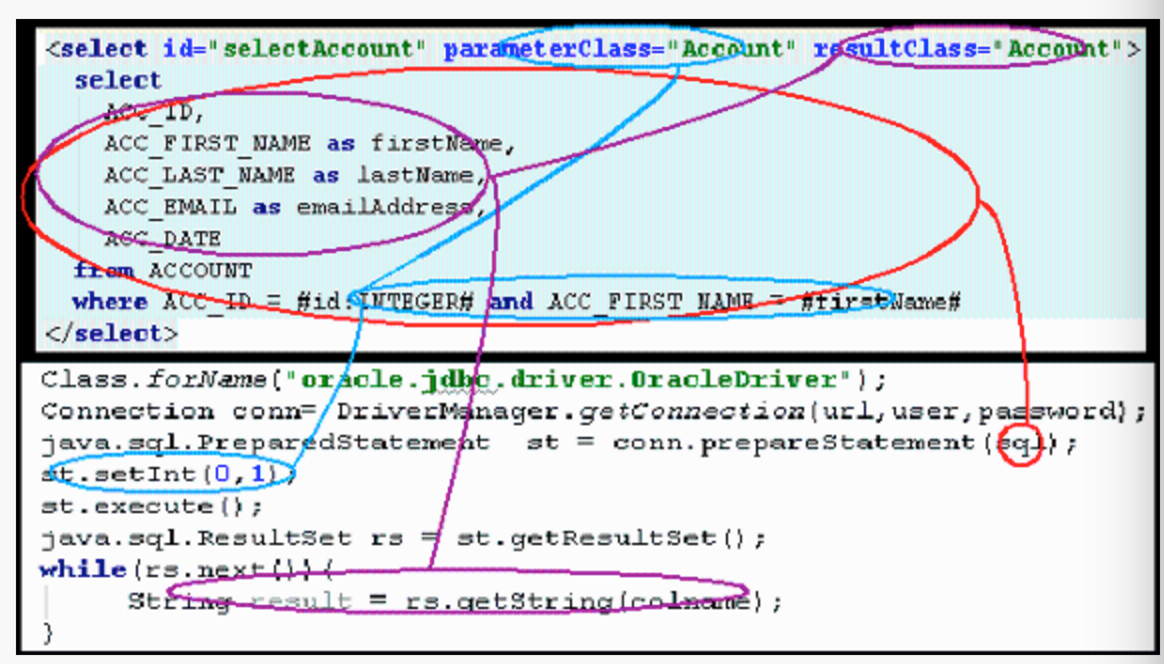
如果用最简洁的话来总结 iBATIS 主要完成那些功能时,我想下面几个代码足够概括。
1 Class.forName("oracle.jdbc.driver.OracleDriver"); 2 Connection conn= DriverManager.getConnection(url,user,password); 3 java.sql.PreparedStatement st = conn.prepareStatement(sql); 4 st.setInt(0,1); 5 st.execute(); 6 java.sql.ResultSet rs = st.getResultSet(); 7 while(rs.next()){ 8 String result = rs.getString(colname); 9 }
iBATIS 就是将上面这几行代码分解包装,但是最终执行的仍然是这几行代码。前两行是对数据库的数据源的管理包括事务管理,3、4 两行 iBATIS 通过配置文件来管理 SQL 以及输入参数的映射,6、7、8 行是 iBATIS 获取返回结果到 Java 对象的映射,也是通过配置文件管理。
配置文件对应到相应代码如图所示:
iBATIS 框架主要的类层次结构
iBATIS 的框架结构也是按照这种思想来组织类层次结构的,其实它是一种典型的交互式框架。先期准备好交互的必要条件,然后构建一个交互的环境,交互环境中还划分成会话,每次的会话也有一个环境。当这些环境都准备好了以后,剩下的就是交换数据了。其实涉及到网络通信,一般都会是类似的处理方式。
iBATIS 框架的主要的类层次结构图
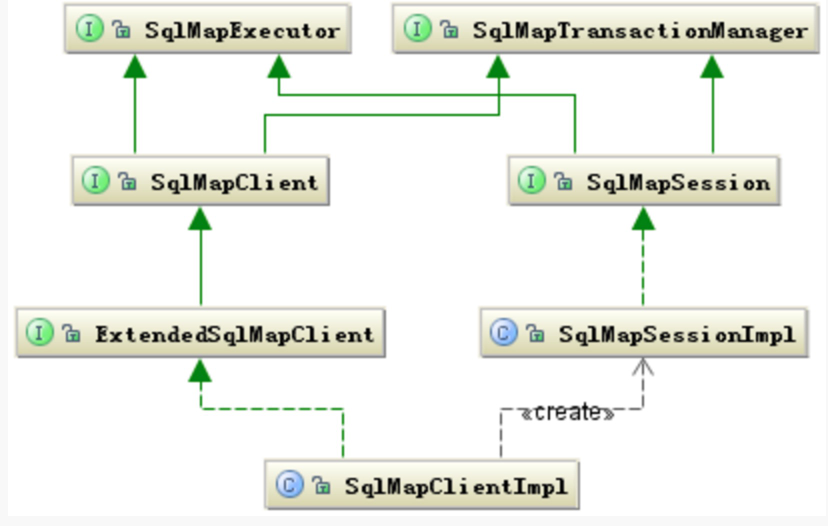
左边 SqlMapClient 接口主要定义了客户端的操作行为包括 select、insert、update、delete。
右边主要是定义了当前客户端在当前线程的执行环境。SqlMapSession 可以共享使用,也可以自己创建,如果是自己创建在结束时必须要调用关闭接口关闭。
当使用者持有了 SqlMapClientImpl 对象就可以使用 iBATIS 来工作了。SqlMapExecutorDelegate 这个类从名字就可以看出他是执行代理类。这个类非常重要,重要是因为他耦合了用户端的执行操作行为和执行的环境,他持有执行操作的所需要的数据,同时提供管理着执行操作依赖的环境。所以他是一个强耦合的类,也可以看做是个工具类。
iBATIS 框架的设计策略
iBATIS 框架的一个重要组成部分就是其 SqlMap 配置文件,SqlMap 配置文件的核心是 Statement 语句包括 CIUD。 iBATIS 通过解析 SqlMap 配置文件得到所有的 Statement 执行语句,同时会形成 ParameterMap、ResultMap 两个对象用于处理参数和经过解析后交给数据库处理的 Sql 对象。这样除去数据库的连接,一条 SQL 的执行条件已经具备了。
Statement 有关的类结构图
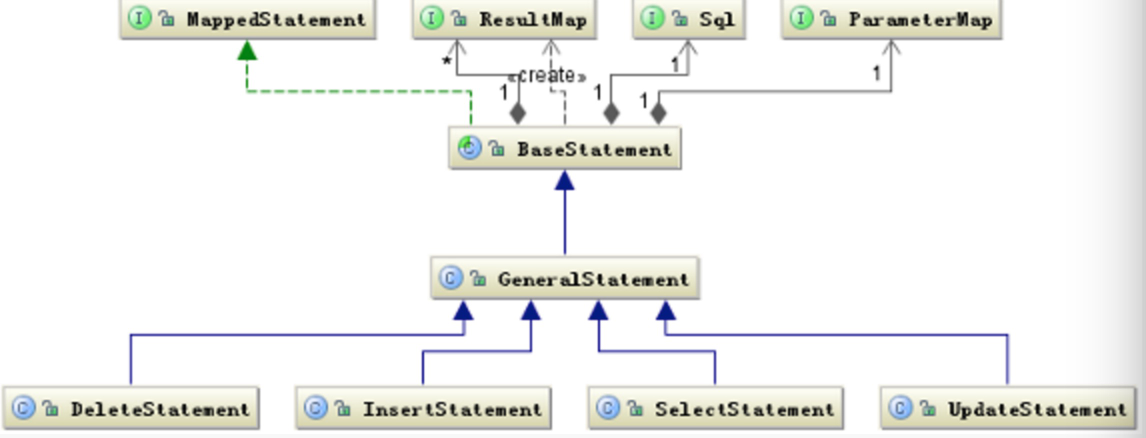
上图给出了围绕 SQL 执行的基本的结构关系(入参,出参,sql,Map 集合),还有一个关键的部分就是,如何定义 SQL 语句中的参数与 Java 对象之间的关系,这其中还涉及到 Java 类型到数据库类型的转换等一系列问题。
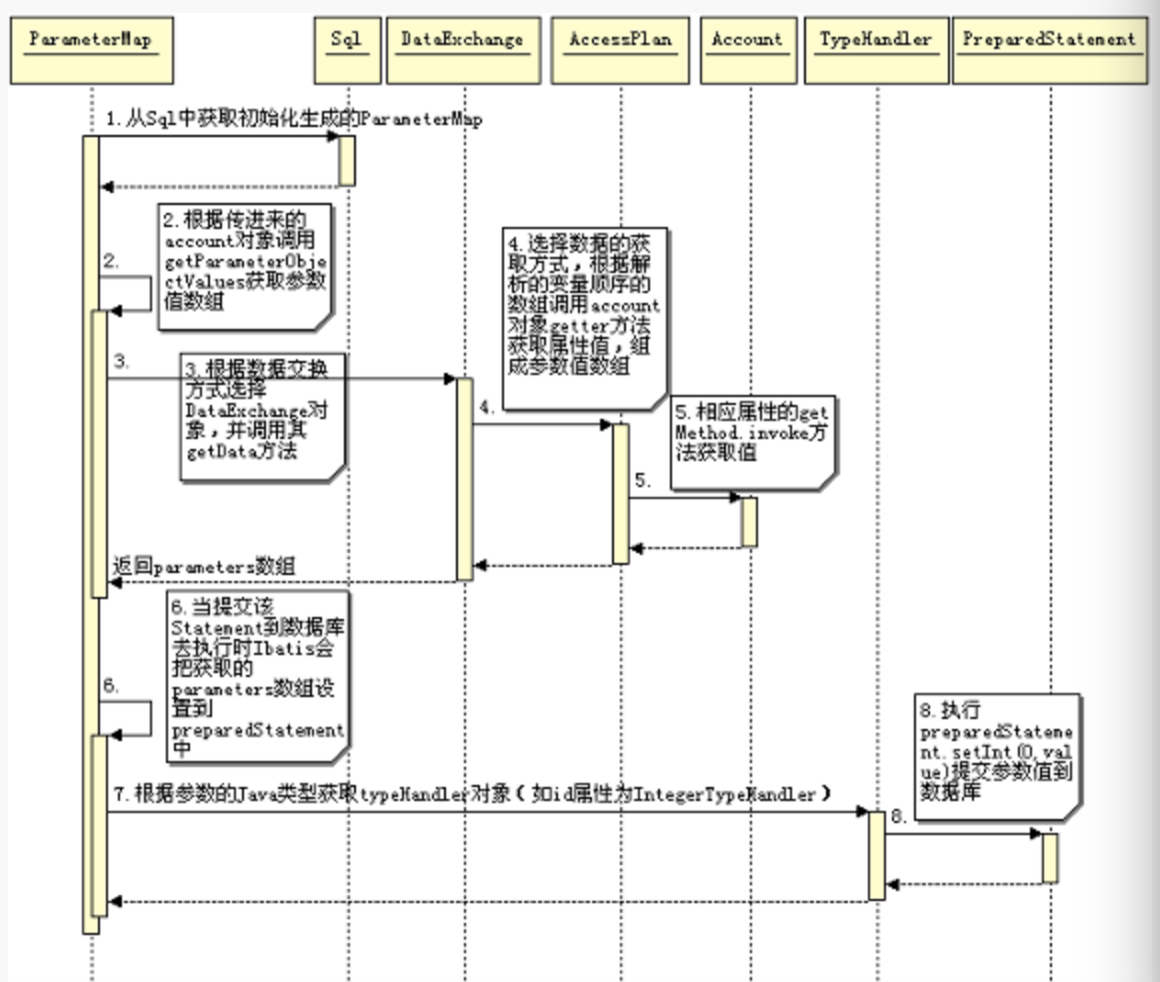
数据的映射大体的过程是这样的:根据 Statement 中定义的 SQL 语句,解析出其中的参数,按照其出现的顺序保存在 Map 集合中,并按照 Statement 中定义的 ParameterMap 对象类型解析出参数的 Java 数据类型。并根据其数据类型构建 TypeHandler(#id:INTEGER#) 对象,参数值的复制是通过 DataExchange 对象完成的。
参数映射相关的类结构图
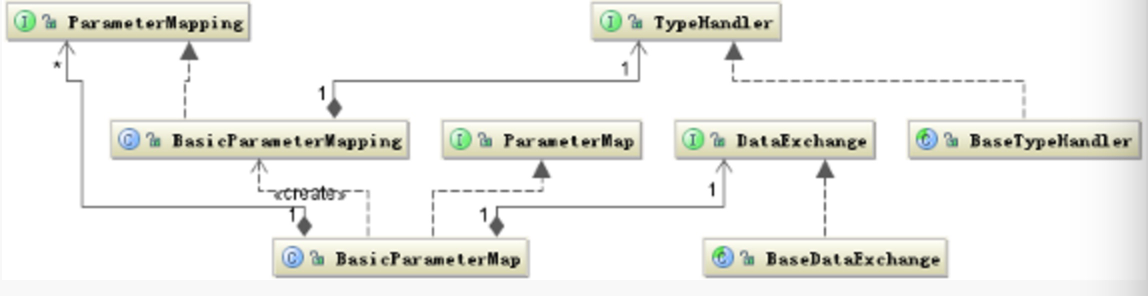
上图是输入参数的映射结构情况,返回结果 ResultMap 的映射情况也是类似的。主要就是要解决 SQL 语句中的参数与返回结果的列名与 Statement 中定义的 parameterClass 和 resultClass 中属性的对应关系。
iBATIS 框架的运行原理
主要执行步骤
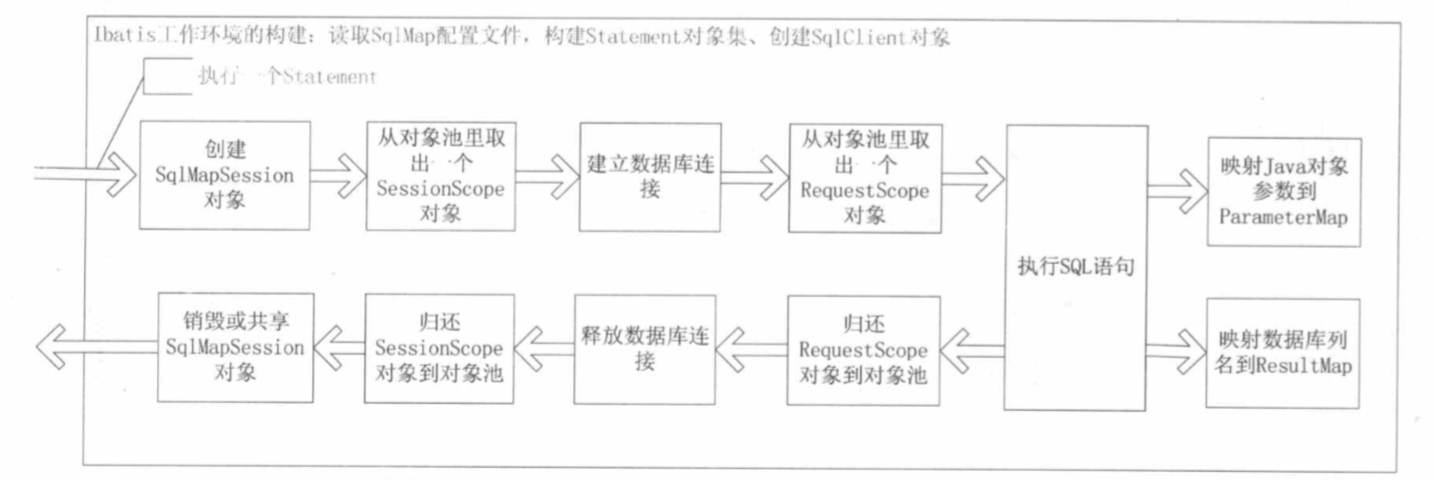
SqlMapSession 对象的创建和释放根据不同情况会有不同,因为 SqlMapSession 负责创建数据库的连接,包括对事务的管理,iBATIS 对管理事务既可以自己管理也可以由外部管理,iBATIS 自己管理是通过共享 SqlMapSession 对象实现的,多个 Statement 的执行时共享一个 SqlMapSession 实例,而且都是线程安全的。如果是外部程序管理就要自己控制 SqlMapSession 对象的生命周期。
示例 <beans> <bean id="sqlMapTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> </bean> <bean id="sqlMapTransactionTemplate" class="org.springframework.transaction.support.TransactionTemplate"> <property name="transactionManager" ref="sqlMapTransactionManager"/> </bean> <!--sql map --> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="configLocation" value="com/mydomain/data/SqlMapConfig.xml"/> <property name="dataSource" ref="dataSource"/> </bean> <bean id="dataSource" name="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/> <property name="url" value="jdbc:oracle:thin:@10.1.5.11:1521:XE"/> <property name="username" value="junshan"/> <property name="password" value="junshan"/> <property name="maxActive" value="20"/> </bean> <bean id="accountDAO" class="com.mydomain.AccountDAO"> <property name="sqlMapClient" ref="sqlMapClient"/> <property name="sqlMapTransactionTemplate" ref="sqlMapTransactionTemplate"/> </bean> </beans> <select id="selectAccount" parameterClass="Account" resultClass="Account"> select ACC_ID, ACC_FIRST_NAME as firstName, ACC_LAST_NAME as lastName, ACC_EMAIL as emailAddress, ACC_DATE from ACCOUNT where ACC_ID = #id:INTEGER# and ACC_FIRST_NAME = #firstName# </select> public class SimpleTest { public static void main(String[] args) { ApplicationContext factory = new ClassPathXmlApplicationContext("/com/mydomain/data/applicationContext.xml"); final AccountDAO accountDAO = (AccountDAO) factory.getBean("accountDAO"); final Account account = new Account(); account.setId(1); account.setFirstName("tao"); account.setLastName("bao"); account.setEmailAddress("junshan@taobao.com"); account.setDate(new Date()); try { accountDAO.getSqlMapTransactionTemplate().execute(new TransactionCallback(){ public Object doInTransaction(TransactionStatus status){ try{ accountDAO.deleteAccount(account.getId()); accountDAO.insertAccount(account); Account result = accountDAO.selectAccount(account); System.out.println(result); return null; } catch (Exception e) { status.setRollbackOnly(); return false; } } }); //accountDAO.getSqlMapClient().commitTransaction(); } catch (Exception e) { e.printStackTrace(); } } }
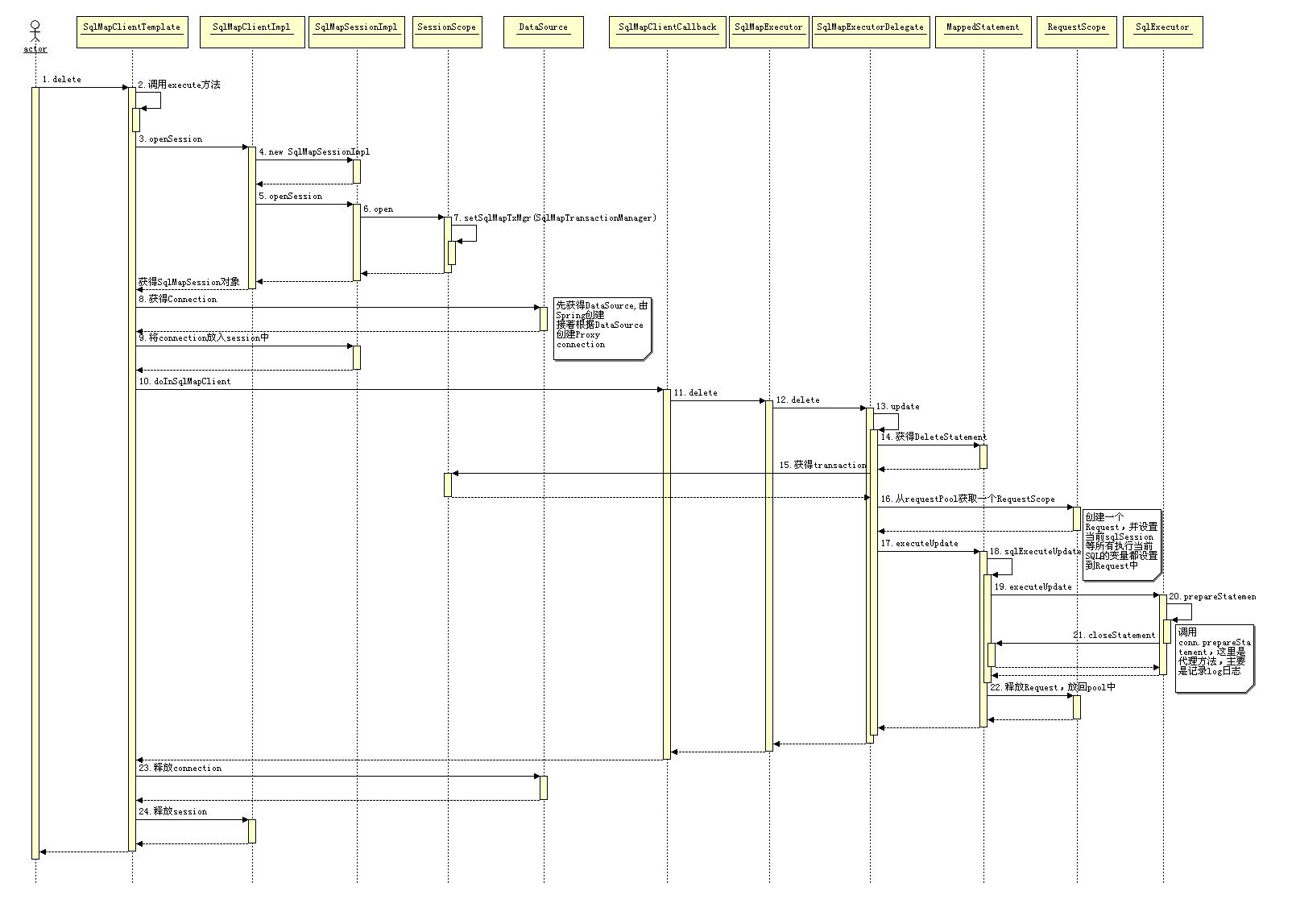
入参到 SQL 语句的解析
iBATIS 会把 SqlMap 配置文件解析成一个个 Statement,其中包括 ParameterMap、ResultMap,以及解析后的 SQL。当 iBATIS 构建好 RequestScope 执行环境后,要做的工作就是把传过来的对象数据结合 ParameterMap 中信息提取出一个参数数组,这个数组的顺序就是对应于 SQL 中参数的顺序,然后会调用 preparedStatement.setXXX(i, parameter) 提交参数。
我们给 account 对象的 id 属性和 firstName 属性分别赋值为 1 和“tao“,当执行下面这段代码时,iBATIS 必须把这两个属性值传给 SQL 语句中对象的参数。
解析后的sql
select
ACC_ID,
ACC_FIRST_NAME as firstName,
ACC_LAST_NAME as lastName,
ACC_EMAIL as emailAddress,
ACC_DATE
from ACCOUNT
where ACC_ID = ? and ACC_FIRST_NAME = ?
#id:INTEGER# 将被解析成 JDBC 类型是 INTEGER,参数值取 Account 对象的 id 属性。#firstName# 同样被解析成 Account 对象的 firstName 属性,而 parameterClass="Account"指明了 Account 的类类型。 #id:INTEGER# 和 #firstName# 都被替换成“?”,iBATIS 如何保证它们的顺序?iBATIS 会根据“#”分隔符取出合法的变量名构建参数对象数组,数组的顺序就是 SQL 中变量出现的顺序。接着 iBATIS 会根据这些变量和 parameterClass 指定的类型创建合适的 dataExchange 和 parameterPlan 对象。parameterPlan 对象中按照前面的顺序保存了变量的 setter 和 getter 方法列表。所以 parameter 的赋值就是根据 parameterPlan 中保存的 getter 方法列表以及传进来的 account 对象利用反射机制得到对应的参数值数组,再将这个数组按照指定的 JDBC 类型提交给数据库。在 8 步骤中如果 value 值为空时会设置 preparedStatement.setNull(i , jdbcType) 如果变量没有设置 jdbcType 类型时有可能会出错。
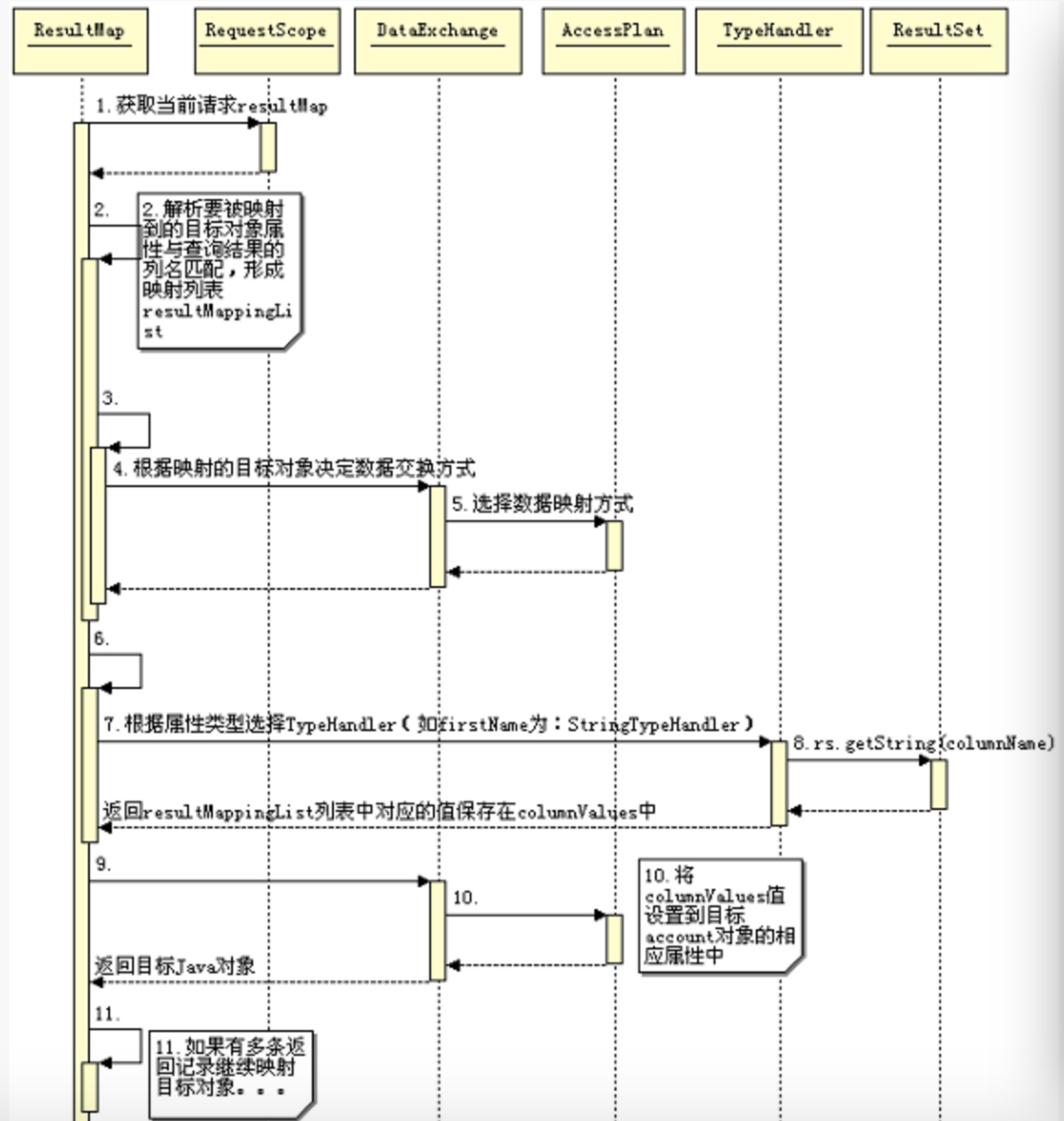
返回到 Java 对象的映射
数据库执行完 SQL 后会返回执行结果,和 ParameterMap 类似,填充返回信息需要的资源都已经包含在 ResultMap 中。当有了保存返回结果的 ResultSet 对象后,就是要把列名映射到 account 对象的对应属性中。这个过程大体如下:
根据 ResultMap 中定义的 ResultClass 创建返回对象,这里就是 account 对象。获取这个对象的所有可写的也就是 setter 方法的属性数组,接着根据返回 ResultSet 中的列名去匹配前面的属性数组,把匹配结果构造成一个集合(resultMappingList),后面是选择 DataExchange 类型、AccessPlan 类型为后面的真正的数据交换提供支持。根据 resultMappingList 集合从 ResultSet 中取出列对应的值,构成值数组(columnValues),这个数组的顺序就是 SQL 中对应列名的顺序。最后把 columnValues 值调用 account 对象的属性的 setter 方法设置到对象中。这个过程可以用下面的时序图来表示:
示例运行的结果
Account{id=0, firstName='tao', lastName='bobo', emailAddress='junshan
上面的结果和我们预想的结果似乎有所不同,看代码我们插入数据库的 account 对象各属性值分别为 {1,“tao”,“bao”,“junshan@taobao.com”,“时间”},返回应该是一样的结果才对。id 的结果不对、date 属性值丢失。再仔细看看这个 Statement 可以发现,返回结果的列名分别是 {ACC_ID,firstName,lastName,emailAddress,ACC_DATE} 其中 id 和 date 并不能映射到 Account 类的属性中。id 被赋了默认数字 0,而 date 没有被赋值。
ps:(where ACC_ID = #id:INTEGER#)
变量 id 后面跟上 JDBC 类型,这个 JDBC 类型有没有用?通常情况下都没有用,因此你可以不设,iBATIS 会自动选择默认的类型。但是如果这个值可能为空时如果没有指定 JDBC 类型可能就有问题了,在 Oracle 中虽然能正常工作但是会引起 Oracle 当前这个 SQL 有多次编译现象,因此会影响数据库的性能。还有当同一个 Java 类型如果对应多个 JDBC 类型(如 Date 对应 JDBC 类型有 java.sql.Date、java.sql.Timestamp)就可以通过指定 JDBC 类型保存不同的值到数据库。

