分布式事务
InnoDB存储引擎支持XA事务,通过XA事务可以来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中所有参与的事务要么都提交、要么都回滚,这对于事务原有的ACID要求又有了提高。另外,在使用分布式事务时,InnoDB存储引擎的事务隔离级别必须设置为SERIALIABLE。
XA事务允许不同数据库之间的分布式事务,如:一台服务器是MySQL数据库的,另一台是Oracle数据库的,又可能还有一台服务器是SQL Server数据库的,只要参与全局事务中的每个节点都支持XA事务。分布式事务可能在银行系统的转账中比较常见,如一个用户需要从上海转10 000元到北京的一个用户上:
#Bank@Shanghai:
update account set money=money-10000 where user='David';
#Bank@Beijing
Update account set money=money+10000 where user='Mariah';
这种情况一定需要分布式的事务,如果不能都提交或都回滚,在任何一个节点出现问题都会导致严重的结果:要么是David的账户被扣款,但是Mariah没收到;又或者是David的账户没有扣款,但是Mariah还是收到钱了。
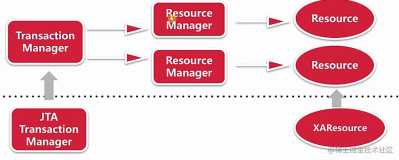
分布式事务由一个或者多个资源管理器(Resource Managers)、一个事务管理器(Transaction Manager)以及一个应用程序(Application Program)组成。
资源管理器:提供访问事务资源的方法。通常一个数据库就是一个资源管理器。
事务管理器:协调参与全局事务中的各个事务。需要和参与全局事务中的所有资源管理器进行通信。
应用程序:定义事务的边界,指定全局事务中的操作。
在MySQL的分布式事务中,资源管理器就是MySQL数据库,事务管理器为连接到MySQL服务器的客户端。下图显示了一个分布式事务的模型:
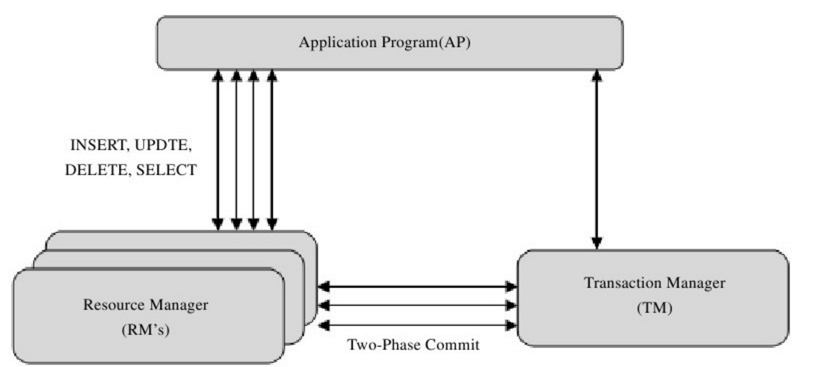
分布式事务使用两段式提交(two-phase commit)的方式。在第一个阶段,所有参与全局事务的节点都开始准备(PREPARE),告诉事务管理器它们准备好提交了。第二个阶段,事务管理器告诉资源管理器执行ROLLBACK还是COMMIT。如果任何一个节点显示不能提交,则所有的节点都被告知需要回滚。
当前Java的JTA(Java Transaction API)可以很好地支持MySQL的分布式事务,需要使用分布式事务应该认真参考其API。
下面的一个示例显示了如何使用JTA来调用MySQL的分布式事务,例子就是前面的银行转账,如下所示。
import javax.transaction.xa.Xid; class MyXid implements Xid { public int formatId; public byte gtrid[]; public byte bqual[]; public MyXid() { } public MyXid(int formatId, byte gtrid[], byte bqual[]) { this.formatId = formatId; this.gtrid = gtrid; this.bqual = bqual; } public int getFormatId() { return formatId; } public byte[] getBranchQualifier() { return bqual; } public byte[] getGlobalTransactionId() { return gtrid; } } import com.mysql.jdbc.jdbc2.optional.MysqlXADataSource; import javax.sql.XAConnection; import javax.transaction.xa.XAResource; import javax.transaction.xa.Xid; import java.sql.Connection; import java.sql.Statement; public class xa_demo { public static MysqlXADataSource GetDataSource(String connString,String user,String passwd) { try { MysqlXADataSource ds = new MysqlXADataSource(); ds.setUrl(connString); ds.setUser(user); ds.setPassword(passwd); return ds; } catch (Exception e) { System.out.println(e.toString()); return null; } } public static void main(String[] args) { String connString1 = "jdbc:mysql://192.168.24.43:3306/bank_shanghai"; String connString2 = "jdbc:mysql://192.168.24.166:3306/bank_beijing"; try { MysqlXADataSource ds1 = GetDataSource(connString1, "peter", "12345"); MysqlXADataSource ds2 = GetDataSource(connString2, "david", "12345"); XAConnection xaConn1 = ds1.getXAConnection(); XAResource xaRes1 = xaConn1.getXAResource(); Connection conn1 = xaConn1.getConnection(); Statement stmt1 = conn1.createStatement(); XAConnection xaConn2 = ds2.getXAConnection(); XAResource xaRes2 = xaConn2.getXAResource(); Connection conn2 = xaConn2.getConnection(); Statement stmt2 = conn2.createStatement(); Xid xid1 = new MyXid( 100, new byte[]{0x01}, new byte[]{0x02}); Xid xid2 = new MyXid( 100, new byte[]{0x11}, new byte[]{0x12}); try { xaRes1.start(xid1, XAResource.TMNOFLAGS); stmt1.execute("update account set money = money - 10000 where user = 'david'"); xaRes1.end(xid1, XAResource.TMSUCCESS); xaRes2.start(xid2, XAResource.TMNOFLAGS); stmt2.execute("update account set money = money + 10000 where user = 'mariah'"); xaRes2.end(xid2, XAResource.TMSUCCESS); int ret2 = xaRes2.prepare(xid2); int ret1 = xaRes1.prepare(xid1); if (ret1 == XAResource.XA_OK&&ret2 == XAResource.XA_OK){ xaRes1.commit(xid1, false); xaRes2.commit(xid2, false); } } catch (Exception e) { e.printStackTrace(); } } catch (Exception e) { System.out.println(e.toString()); } } }
参数innodb_support_xa可以查看是否启用了XA事务支持(默认为ON):
show variables like 'innodb_support_xa'\G
***************************1.row***************************
Variable_name:innodb_support_xa
Value:ON
1 row in set(0.01 sec)
另外需要注意的是,对于XA事务的支持,是在MySQL体系结构的存储引擎层。因此即使不参与外部的XA事务,MySQL内部不同存储引擎层也会使用XA事务。假设我们用START TRANSACTION开启了一个本地的事务,往NDB Cluster存储引擎的表t1插入一条记录,往InnoDB存储引擎的表t2插入一条记录,然后COMMIT。在MySQL内部,也是通过XA事务来协调的,这样才可以保证两张表的原子性。
不好的事务习惯
在循环中提交
开发人员非常喜欢在循环中进行事务的提交,下面是他们可能常写的一个存储过程:
CREATE PROCEDURE load1(count int unsigned)
begin
declare s int unsigned default 1;
declare c char(80) default repeat('a',80);
while s<=count do
insert into t1 select NULL,c;
commit;
set s=s+1;
end while;
end;
其实,在这个例子中,是否加上commit并不关键,因为InnoDB存储引擎默认为自动提交,因此上面的存储过程中去掉commit,结果是完全一样的。这也是另一种容易忽视的问题:
CREATE PROCEDURE load2(count int unsigned)
begin
declare s int unsigned default 1;
declare c char(80) default repeat('a',80);
while s<=count do
insert into t1 select NULL,c;
set s=s+1;
end while;
end;
不论上面哪个存储过程都存在一个问题:当发生错误时,数据库会停留在一个未知的位置。如我们要插入的是10 000条记录,但是在插入5000条时,发生了错误,而这时前5000条记录已经存放在数据库中,那我们应该怎么处理呢?还有一个问题是性能问题,上面两个存储过程都不会比在下面的一个存储过程快,因为它是放在一个事务里:
CREATE PROCEDURE load3(count int unsigned)
begin
declare s int unsigned default 1;
declare c char(80) default repeat('a',80);
start transaction;
while s<=count do
insert into t1 select NULL,c;
set s=s+1;
end while;
commit;
end;
比较这3个存储过程的执行时间:
call load1(10000);
Query OK,0 rows affected(1 min 3. 15 sec)
truncate table t1;
call load2(10000);
Query OK,1 row affected(1 min 1. 69 sec)
truncate table t1;
call load3(10000);
Query OK,0 rows affected(0. 63 sec)
显然,第三种方法要快得多!这是因为,每一次提交都要写一次重做日志,因此存储过程load1和load2实际写了10 000次,而对于存储过程load3来说,实际只写了1次。可以对第二个存储过程load2的调用进行调整,同样可以达到存储过程load3的性能,如下代码所示。
begin;
call load2(10000);
commit;
大多数程序员会使用第一种或者第二种方法,有人可能不知道InnoDB存储引擎自动提交的情况,另外有些人可能持有以下两种观点:首先,在他们曾经使用过的数据库中,对于事务的要求总是尽快地进行释放,不能有长时间的事务;其次,他们可能担心存在Oracle数据库中由于没有足够UNDO产生的Snapshot Too Old的经典问题。MySQL InnoDB存储引擎上述两个问题都没有,因此程序员不论从何种角度出发,都不应该在一个循环中反复进行提交操作,不论是显式的提交还是隐式的提交。
使用自动提交
自动提交并不是好习惯,因为这对于初级DBA容易犯错,另外对于一些开发人员可能产生错误的理解。MySQL数据库默认设置使用自动提交(autocommit)。可以使用如下语句来改变当前自动提交的方式:
set autocommit=0;
也可以使用START TRANSACTION、BEGIN来显式地开启一个事务。显式开启事务后,在默认设置下(即参数completion_type等于0),MySQL会自动执行SET AUTOCOMMIT=0的命令,并在COMMIT或者ROLLBACK结束一个事务后执行SET AUTOCOMMIT=1。
另外,在不同的语言API时,自动提交是不同的。MySQL C API默认的提交方式是自动提交的,而MySQL Python API则是自动执行SET AUTOCOMMIT=0,以禁用自动提交。因此在选用不同的语言来编写数据库应用程序前,应该对连接MySQL的API做好研究。
在编写应用程序开发时,最好把事务的控制权限交给开发人员,即在程序端进行事务的开始和结束。同时,开发人员必须了解自动提交可能带来的问题。
使用自动回滚
InnoDB存储引擎支持通过定义一个HANDLER来进行自动事务的回滚操作,如一个存储过程中发生了错误,会自动对其进行回滚操作,因此很多开发人员喜欢在应用程序的存储过程中使用自动回滚操作,如下面的一个存储过程:
create procedure sp_auto_rollback_demo()
begin
declare exit handler for sqlexception rollback;
start transaction;
insert into b select 1;
insert into b select 2;
insert into b select 1;
insert into b select 3;
commit;
end;
存储过程sp_auto_rollback_demo首先定义了一个exit类型的handler,当捕获到错误时进行回滚。结构如下所示:
show create table b\G
因此插入第二个记录1时会发生错误,但是因为启用了自动回滚的操作,因此这个存储过程的执行结果如下所示:
call sp_auto_rollback_demo;
select * from b;
Empty set(0.00 sec)
看起来运行没有问题,非常正常。但是,执行sp_auto_rollback_demo这个存储过程的结果到底是正确的还是错误的呢?
对于同样的存储过程sp_auto_rollback_demo,开发人员可能会进行这样的处理:
create procedure sp_auto_rollback_demo()
begin
declare exit handler for sqlexception begin rollback;select -1;end;
start transaction;
insert into b select 1;
insert into b select 2;
insert into b select 1;
insert into b select 3;
commit;
select 1;
end;
当发生错误时,先回滚,然后返回-1,表示运行有错误。运行正常,返回值1。因此这次运行的结果就会变成:
call sp_auto_rollback_demo()\G
***************************1.row***************************
-1:-1
1 row in set(0.04 sec)
select * from b;
Empty set(0.00 sec)
看起来我们可以得到运行是否准确的信息。但问题还没有最终解决,对于开发来说,重要的不仅是知道发生了错误,而是发生了什么样的错误。因此自动回滚存在这样的一个问题。
使用自动回滚大多是以前使用Microsoft SQL Server数据库。在Microsoft SQL Server数据库中,可以使用SET XABORT ON来回滚一个事务。但是Microsoft SQL Server数据库不仅会自动回滚当前的事务,并且还会抛出异常,开发人员可以捕获到这个异常。因此,Microsoft SQL Server数据库和MySQL数据库在这方面是有所不同的。
对于事务的BEGIN、COMMIT和ROLLBACK操作,应该交给程序端来完成,存储过程只要完成一个逻辑的操作。
下面演示用Python语言编写的程序调用一个存储过程sp_rollback_demo,存储过程sp_rollback_demo和之前的存储过程sp_auto_rollback_demo在逻辑上完成的内容大致相同:
create procedure sp_rollback_demo()
begin
insert into b select 1;
insert into b select 2;
insert into b select 1;
insert into b select 3;
end;
和sp_auto_rollback_demo存储过程不同的是,在sp_rollback_demo存储过程中去掉了对于事务的控制语句,将这些操作都交由程序来完成。接着来看test_demo.py的程序源代码:
#!/usr/bin/env python
#encoding=utf-8
import MySQLdb
try:
conn=MySQLdb.connect(host="192.168.8.7",user="root",passwd="xx“,db="test")
cur=conn.cursor()
cur.execute("set autocommit=0")
cur.execute("call sp_rollback_demo")
cur.execute("commit")
except Exception,e:
cur.execute("rollback")
print e
观察运行test_demo.py这个程序的结果:
python test_demo.py
starting rollback
(1062,"Duplicate entry'1'for key'PRIMARY'")
在程序中控制事务的好处是,我们可以得知发生错误的原因。如上述这个例子中,我们知道是因为发生了1062这个错误,错误的提示内容是Duplicate entry'1'for key'PRIMARY',即发生了主键重复的错误,然后可以根据发生的原因来调试我们的程序。