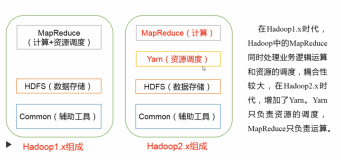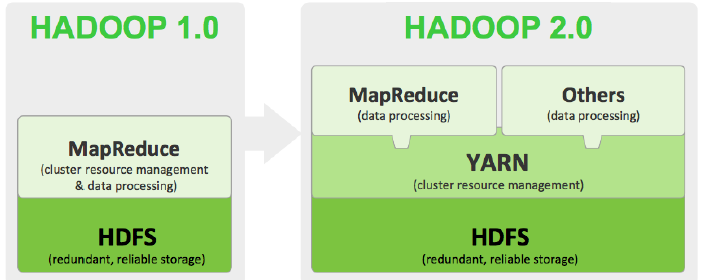
Hadoop1.x构成: HDFS、MapReduce(资源管理和任务调度);运行时环境为JobTracker和TaskTracker;
Hadoop2.0构成:HDFS、MapReduce/其他计算框架、YARN; 运行时环境为YARN
1、HDFS:HA、NameNode Federation
2、MapReduce/其他计算框架:运行在YARN之上的MapReduce通常称之为MapReduce2.0(MRv2)
3、YARN:资源管理系统(Yet Another Resource Negotiator),在其之上可以运行各种计算框架,如:MapReduce、Storm、Spark等;
HDFS2.0
解决HDFS1.0中单点故障和内存受限问题
解决单点故障: HDFS HA(High Available)
通过主备NameNode,当主NameNode发生故障时则切换到备NameNode;
解决内存受限问题: HDFS Federation
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;不同的NameNode可以分管不同的应用;
所有NameNode共享所有DataNode存储的资源;
HDFS2.0和HDFS1.0相比、仅是架构上发生了变化,使用方式不变,对HDFS使用者来说是透明的。比如说hdfs shell命令:
hadoop fs -ls /luogankun
hadoop fs -mkdir /luogankun/data
在HDFS1.0和HDFS2.0中用法是一致的。
YARN
Hadoop2.0新引入的资源管理系统
YARN核心思想:将MRv1中JobTracker的资源管理和任务调度分开,分别由ResourceManager和ApplicationMaster进程实现;
ResourceManager:负责整个集群的资源管理;整个集群只有一个;
ApplicationMaster:负责应用程序相关的事务,比如:任务调度、任务监控和任务容错;一个应用程序对应一个ApplicationMaster;
YARN引入的好处:使得多个计算框架可以运行在一个集群中,比如:MapReduce、Spark、Storm等;
MapReduce On YARN
运行在YARN之上的MapReduce称为MRv2;
将MapReduce作业直接运行在YARN上,而不是运行在由JobTracker和TaskTracker构建的MRv1之上;在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模块基本功能:
1、YARN:负责资源管理和调度;
2、MRAppMaster:负责一个应用程序/作业的任务切分、任务调度、任务监控和容错;
3、Map/Reduce Task:任务驱动引擎,与MRv1一致;
每个应用程序/作业对应一个MRAppMaster,所以:
1、单个应用程序/作业运行失败,不会影响其他应用程序/作业;
2、负责应用程序/作业相关的事务,包括将从YARN分配得到的资源二次分配给内部的任务、任务切分、任务健康和容错等;
source : http://www.cnblogs.com/luogankun/p/3886989.html